存储过程包含一组复杂的SQL语句,使生成存储过程的执行计划的代价有些高。因此通常重用存储过程的执行计划来代替生成新计划是有利的。但是有时候现有的计划可能不适用或者在重用期间可能不能提供最佳的处理策略。SQL Server重编译存储过程中的语句来生成一个新的执行计划以解决这个问题。
1、产生存储过程重新编译的要素 为提高SQL性能,不仅仅是只注意SQL语句写法问题,也不仅是意味者提高硬件要求,我们也必须要关注存储过程编译的时机,以及影响存储过程重新编译的起因,也是改进性能的一项不可避免的因素。
影响存储过程重新编译因素:
a、存储过程语句中引用常规表、临时表或视图架构变化(索引修改、创建……)
b、表索引或列上统计变化超过一定的阈值
c、存储过程编译时一个对象不存在,但是在执行期间创建
d、执行计划老化并释放
e、表列上绑定值变化
f、 环境变化(Set)
g、参数的不确定性
2、表列上绑定值的变化
表结构如下:创建一张表并设置DateTimes默认值为当前时间 ,创建存储过程信息如下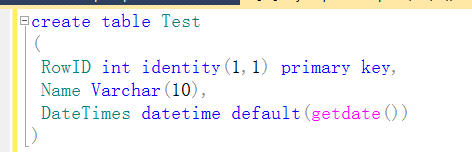

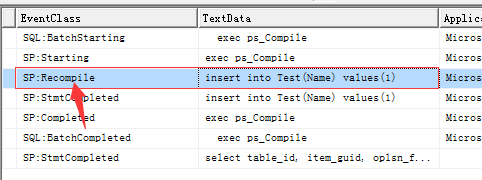
修改Test表中DateTimes绑定值信息,并执行,使用SQL Profiler工具查看存储过程执行的信息(进行了重新编译)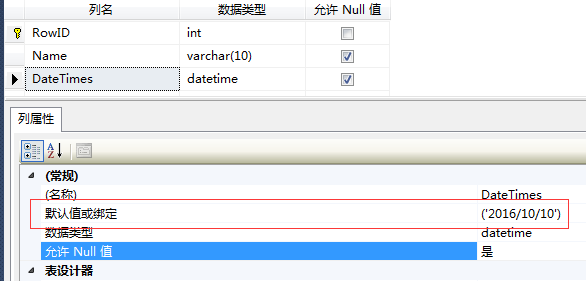
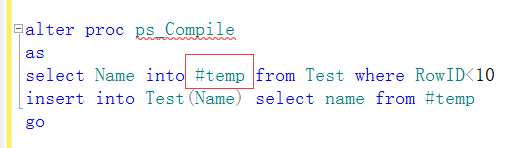
3、存储过程语句中引用常规表、临时表或视图架构变化(索引修改、创建……) 当存储过程中的临时表……架构等发生变化也会导致存储过程重新编译。当我们修改了表架构时,原有的执行计划引擎将会被SQL放弃,当执行这个存储过程时,SQL Server会自动检测架构是否修改并重新编译。
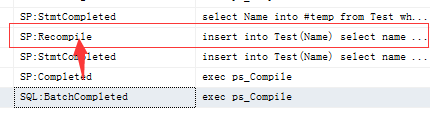
4、表索引或列上统计变化超过一定的阈值 Sqlserver 查询是基于开销查询的,在首次生成执行计划时是基于多阶段的分析优化才确定出较好的执行计划。而这些开销的基数估计,是根据统计信息来确定的。统计信息其实就是对表的各个字段的总体数据进行分段分布数据库默认都会自动维护。如何查看表的统计信息(展开表->选择统计信息->右键属性)
当统计数超过阈值是就会引起存储过程重新编译,(BUT)但是重新编译可以生成一个与之前完成想同的执行计划这样,重新编译的开销就是额外的开销应当避免;如何避免不必要编译这里提供两种方法(未重新编译):
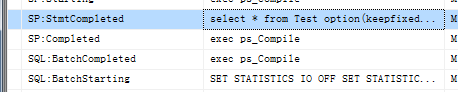
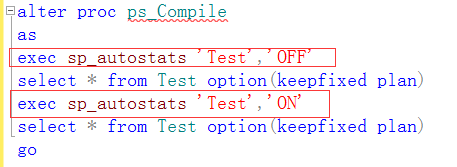
1、保持原有的执行计划方案(keepfixedPlan)
2、关闭表自动统计信息(sp_autostats)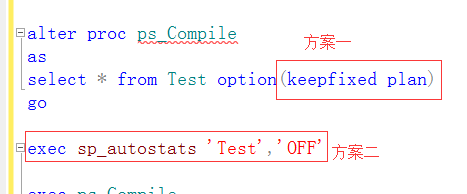
5、执行计划老化并释放 SQL Server通过维护缓冲中执行计划的寿命来管理存储过程缓冲的大小,如果一个存储过程长时间未被重新执行,执行计划的寿命字段将下降为0,内存短缺时将把该计划从缓冲中删除。当这种情况发生并且存储过程被重新执行时,将生成一个新计划并将其缓冲到过程缓冲中,如果系统中有足够的内存,未使用的计划在内存压力增加之前不会被删除。
查询缓存执行计划方式:
Sys.dm_exec_cached_plans: 包含缓存的执行计划,每个执行计划对应一行。
Sys.dm_exec_plan_attributes: 这是一个系统函数,每一个执行计划都对应着一些属性,在这个系统函数中包含着这些属性。
Sys.dm_exec_sql_text: 这是一个系统函数,返回文字格式的执行计划。
Sys.dm_exec_query_plan: 这是一个系统函数,返回xml格式的执行计划。
删除缓存方式:
清除全局缓存使用下面的语句:
DBCC DROPCLEANBUFFERS;
从全局缓存中清除执行计划,使用下面的语句:
DBCC FREEPROCCACHE;
清除某一个数据库中的执行计划,使用下面的语句:
DBCC FLUSHPROCINDB(<db_id>);
清除一个特定的执行计划使用下面的语句:
DBCC FREESYSTEMCACHE(<cachestore>);
6、环境变化(Set) 所谓环境变化指的是SQL SERVER ManageMent Studio开发环境设置的变化
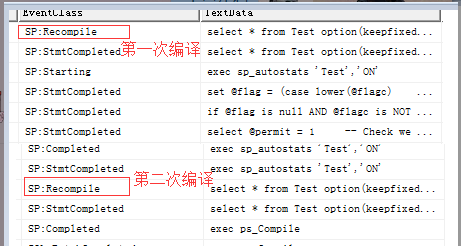
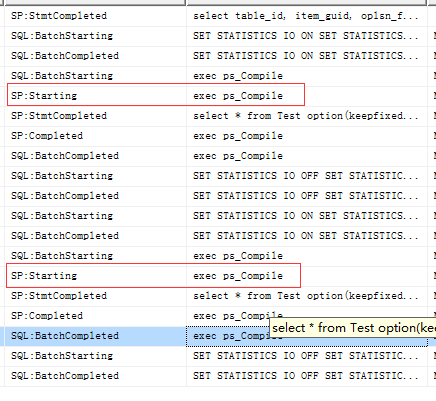
7、参数的不确定性 参数不确定性就很简单了,在不少的存储过程中都会编写部分的业务逻辑信息,进行SQL拼接操作,但是不正当的拼接就会降低存储过程的性能,导致执行存储过程执行时执行计划中多出一步重新编译操作从而降低了存储过程的性能(案例见:高效安全式SQL拼接)
8、重新编译执行时机
学习了影响存储过程重新编译因素后,有不少开发人员会问我们什么时候该让存储过程进行编译什么时候又不该让其编译换句话来说,重新编译应在什么时候执行??
a、当使用表(或对应的统计)中数据的分布变化或者表中添加了新的索引时。这时为查询计划生成了一个策略提高了查询性能时需重新编译不要使用缓存计划;
b、当删除一个对查询性能没有任何影响的索引时,这时对此查询没有任何影响时就不需要重新译否则降低了缓冲效率添加了CPU额外的开销
9、操作存储过程编译的方式 a、调用sp_recompile系统存储过程(exec sp_recompile 'Test')对指定的表每次使用时进行编译
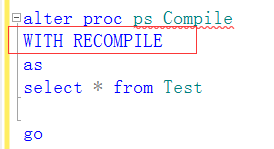
b、使用WITH RECOMPILE子句(强制数据库引擎每次重新生成执行计划,针对特定的存储过程、或某一个比较特殊的存储执行才会使用;使用With Recompile 生成的计划不会被缓存,也不会影响到原缓存的计划),

c、使用OPTIMIZE FOR查询提示(RECOMPILE方式提供了完全不使用计划缓存的节奏。但有些时候特性谓语的执行计划被使用的次数很多,仅仅那些谓语条件产生大量返回结果集的参数编译,我们可以考虑Optimize For参数)

使用了该参数会使得缓存的执行计划按照OPTIMIZE FOR后面的谓语条件来生成并缓存执行计划,这也可能造成不在该参数中的查询效率低下,但是该参数是我们选择的,因此通常我们知道哪些谓语条件会被使用的多一些。