上一篇博客中,详细介绍了UserCF和ItemCF,ItemCF,就是通过用户的历史兴趣,把两个物品关联起来,这两个物品,可以有很高的相似度,也可以没有联系,比如经典的沃尔玛
的啤酒尿布案例。通过ItemCF,能能够真正实现个性化推荐,最大限度地挖掘用户的需求。在购物网站和电子商务,图书中,应用特别广泛。需要维护物品相似度表。spark的MLlib中,
有FP-Growth树挖掘物品的相关度,应用很多。关于FP-Growth树的介绍,有很多博文,不详细说了。他相对于Apriori算法,做了很大的改进,大大降低了时间复杂度。构建FP-Growth
树的过程,还需要维护一个头表(链表),用来存储频繁项集的前缀路径。下面的一张图,可以说明:
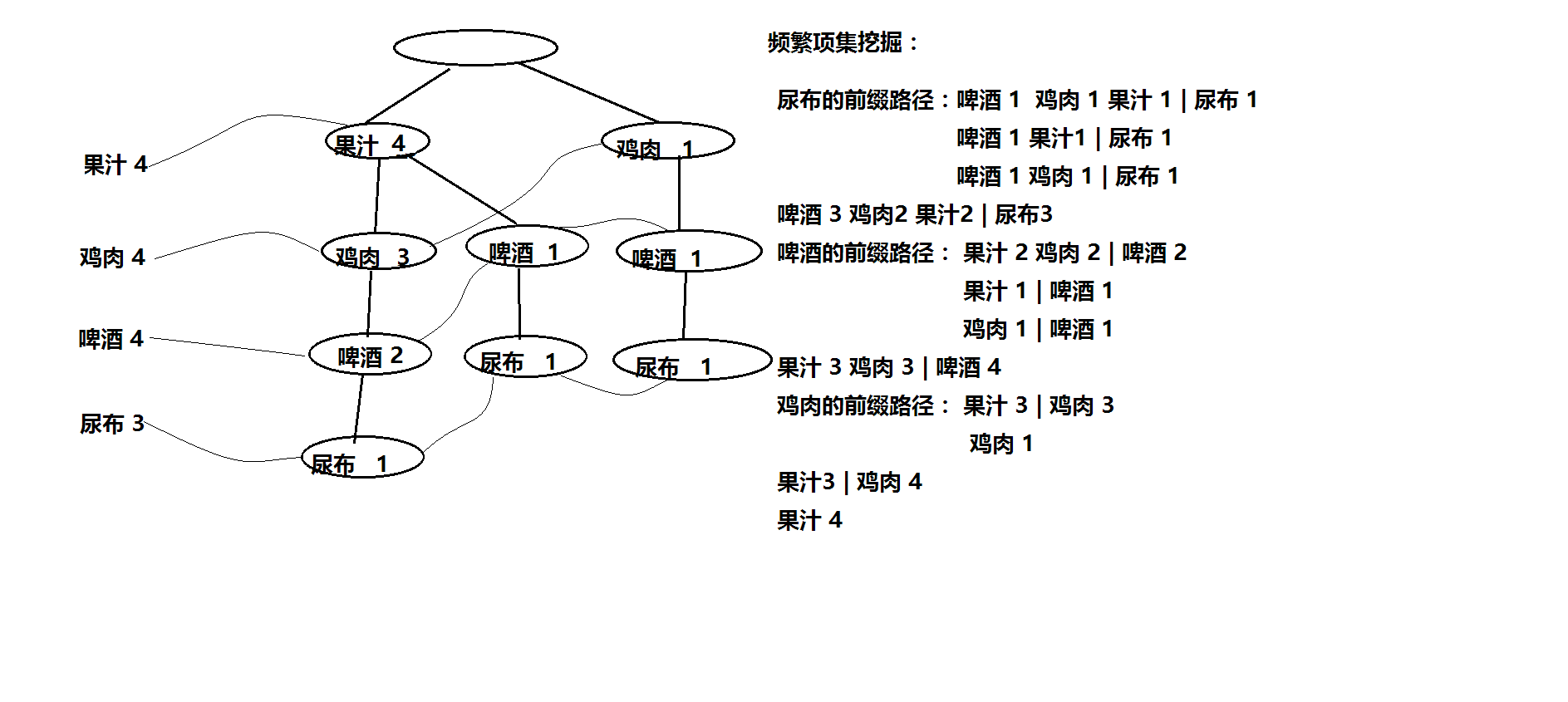
从FP-Growth增长树中挖掘出频繁项集后,比如:啤酒3 鸡肉2 果汁2 | 尿布3,设置了minConf(最小置信度)后,当用户(或者是一个新用户)购买了尿布时,可以给他推荐啤酒,鸡肉。下面的代码,说明了这一原理:
package com.txq.spark.test
/**
* Created by ACER on 2016/11/22.
*/
case class ItemFreq(val item:String,val freq:Double) {
}
package com.txq.spark.test
import java.util.concurrent.ConcurrentHashMap
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection._
/**
* Created by ACER on 2016/11/20.
*/
object Test1 {
System.setProperty("hadoop.home.dir", "D://hadoop-2.6.2");
val conf = new SparkConf().setMaster("local").setAppName("testFP-Growth");
val sc = new SparkContext(conf);
var freqMap = new ConcurrentHashMap[mutable.ArrayBuffer[String],mutable.ArrayBuffer[ItemFreq]]();//捆绑推销(key值为用户购买的历史商品)
val items = new ConcurrentHashMap[Long,mutable.ArrayBuffer[String]]()//用户购买的历史商品
val minSupport = 0.5//最小支持度
val minConf = 0.75//最小置信度
var freq = 0L//用户历史商品出现的次数
var li = mutable.ArrayBuffer[ItemFreq]()
def main(args: Array[String]): Unit = {
//1.加载过去一段时间,大量用户购买的商品,数据源为商品列表,训练FP-Growth模型
val data = sc.textFile("D://fp.txt").map(_.split(" ")).cache()
val count = data.count()
val fpg = new FPGrowth().setMinSupport(minSupport).setNumPartitions(3)
val model = fpg.run(data)
//2.输出所有频繁项集
val result = model.freqItemsets.filter(_.items.size >= 1)
result.foreach(f => println(f.items.mkString(" ")+"->"+f.freq))
//3.获取用户id,并得到历史商品
val userId = args(0).toLong
var bucket:mutable.ArrayBuffer[String] = items.get(userId.toLong)
if(bucket == null){
bucket = new mutable.ArrayBuffer[String]()
for(i <- 1 until args.length){
bucket += (args(i))
}
}
items.put(userId,bucket)//收集用户购买的历史商品
for(item <- result){
//4.在模型中找出与用户的历史商品相符合的频繁项集,得到频率
if(item.items.mkString == items.get(userId).mkString){
freq = item.freq
}
}
println("历史商品出现的次数:" + freq)//调试信息(输出用户历史商品的支持度)
//5.根据历史商品,找出置信度相对高的频繁项,推荐给用户
for(f <- result){
if(f.items.mkString.contains(items.get(userId).mkString) && f.items.size > items.get(userId).size) {
val conf:Double = f.freq.toDouble / freq.toDouble
if(conf >= minConf) {
//找出所有置信度大于minConf的项
var item = f.items
for (i <- 0 until items.get(userId).size) {
item = item.filter(_ != items.get(userId)(i)) //过滤掉用户历史商品,剩下的为推荐的商品
}
for (str <- item) {
li += ItemFreq(str, conf)
}
}
}
}
freqMap.put(items.get(userId),li);
println("推荐的商品为:")
freqMap.get(items.get(userId)).foreach(f =>println(f.item + "->" + f.freq))
}
}
挖掘出的频繁项集:
尿布->3
尿布 啤酒->3
果汁->4
鸡肉->4
鸡肉 果汁->3
啤酒->4
啤酒 鸡肉->3
啤酒 果汁->3
历史商品出现的次数:4
推荐的商品为:
鸡肉->0.75
啤酒->0.75
测试文件为:
果汁 鸡肉
鸡肉 啤酒 鸡蛋 尿布
果汁 啤酒 尿布 可乐
果汁 鸡肉 啤酒 尿布
鸡肉 果汁 啤酒 可乐