之前研究的CRF算法,在中文分词,词性标注,语义分析中应用非常广泛。但是分词技术只是NLP的一个基础部分,在人机对话,机器翻译中,深度学习将大显身手。这篇文章,将展示深度学习的强大之处,区别于之前用符号来表示语义,深度学习用向量表达语义。这篇文章的最大价值在于,为初学者指明了研究方向。下面为转载的原文:
在深度学习出现之前,文字所包含的意思是通过人为设计的符号和结构传达给计算机的。本文讨论了深度学习如何用向量来表示语义,如何更灵活地表示向量,如何用向量编码的语义去完成翻译,以及有待改进的地方。
【编者按】Jonathan Mugan写了两篇博文来解释计算机如何理解我们在社交媒体平台上使用的语言,以及能理解到何种程度。本文是其中的第二篇。
在深度学习出现之前,我们书写的文字所包含的意思是通过人为设计的符号和结构传达给计算机的。我在上一篇博文里详细阐述了这个实现过程。这里先回顾一下几种符号方法:WordNet、ConceptNet和FrameNet,通过对比来更好地理解深度学习的能力。然后我会讨论深度学习如何用向量来表示语义,以及如何更灵活地表示向量。接着我将探讨如何用向量编码的语义去完成翻译,甚至为图片添加描述和用文字回答问题。最后,我总结了用深度学习技术真正地理解人类语言还需要哪些改进。
WordNet可能是最著名的象征意义的语料库,由普林斯顿大学研发。它将意思相近的单词归为一组,并且表示组与组之间的层次联系。举个例子,它认为“轿车”和“汽车”指的是同一个物体,都是属于一类交通工具。
ConceptNet是来自麻省理工学院的语义网络。它表示的关系比WordNet更广。例如,ConceptNet认为“面包”一词往往出现在“烤面包机”附近。然而,词语间的这种关系实在是不胜枚举。理想情况下,我们会说“面包机”不能被“叉子”插入。
FrameNet是伯克利大学的一个项目,它试图用框架对语义归档。框架表示各种概念及其相关的角色。正如我在上一篇博文里写到的,孩子生日聚会框架的不同部分有着不同的角色,比如场地、娱乐活动和糖源。另一个框架是“购买”这个行为,包括卖方、买方和交易商品。计算机能够通过搜索触发框架的关键词来“理解”文字。这些框架需要手动创建,它们的触发词也需要手动关联。我们可以用这种方式来表示大量知识,但是很难一五一十地明确写出来。因为内容实在太多,完完全全写出来也太费神了。
符号也可以用来创建语言模型,计算某个单词将会出现在句子中的概率。举个例子,假设我刚刚写下“我吃了”,那么下一个词语是“庆丰包子”的概率,可以用语料库中“我吃了庆丰包子”出现的次数除以“我吃了”出现的次数来计算。此类模型相当有用,但我们知道“庆丰包子”与“狗不理包子”非常相似,至少比“电饭锅”相似,但是模型并没有利用这种相似性的优势。使用的词语有千千万万,若是存储所有三词短语需消耗(词语数量 x 词语数量 x 词语数量)存储空间,这也是使用符号所带来的问题,因为词语以及词语的组合实在太多。所以,我们需要一种更好的方式。
使用向量表示语义
深度学习使用向量来表示语义,因此概念不再是由一个庞大的符号来表示,而是由特征值表示的一个向量来表示。向量的每个索引代表神经网络训练得到的一个特征,向量的长度一般在300左右。这是一种更加有效的概念表示方法,因为这里的概念是由特征组成的[Bengio and LeCun, 2007]。两个符号只有相同或者不同两种情况,而两个向量可以用相似性来衡量。“庆丰包子”对应的向量与“狗不理包子”对应的向量很接近,但是它们和“轿车”对应的向量差别很大。如同WordNet处理方式一样,相似的向量被归为同一类。
向量还存在内部结构。如果你用意大利向量减去罗马向量,得到的结果应该与法国向量减去巴黎向量的结果非常接近[Mikolov et al., 2013]。我们可以用一个等式来表示:
意大利 - 罗马 = 法国 - 巴黎
另一个例子是:
国王 - 皇后 = 男人 - 女人
我们通过训练神经网络来预测每个词语附近的词语,得到带有这些属性的向量[Mikolov et al., 2013]。你可以从谷歌或者是斯坦福直接下载已经训练好的向量,或是用Gensim软件库自己训练。令人惊讶的是这种方法竟然有效,而且词向量有如此直观的相似性和联系,但事实上确实是有效。
由词向量构成语义
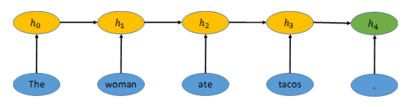
我们已经有了原来表示单个词语的向量,该如何用这些词表示语义,甚至形成完整的句子呢?我们使用一种称为递归神经网络(recurrent neural network, RNN)的技术,如下图所示。用RNN把句子“The woman ate tacos.”编码为向量,记作h4。单词“the”的词向量记作h0,然后RNN把h0与表示“woman”的词向量结合,生成新的向量h1。然后向量h1继续与下一个单词“ate”的词向量结合,生成新的向量h2,以此类推,直到向量h4。向量h4则表示了完整的句子。
一旦信息被编码为一个向量,我们就能将其解码为另一种形式[2],如下图所示。比如,RNN随后可以将向量h4表示的句子翻译(解码)成西班牙语。它先根据已有向量h4生成一个最有可能的单词。向量h4与新生成的单词“La”一起又产生了向量h5。在向量h5的基础上,RNN推出下一个最有可能出现的单词,“mujer”。重复进行这个过程直到产生句号,网络结构也到此为止。
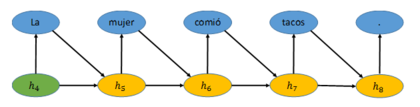
使用这种编码器—解码器模型来做语言转换,需要用一个包含大量源语言与目标语言的语料库,基于这个语料库训练RNN网络。这些RNN通常含有非常复杂的内部节点[3>,整个模型往往有几百万个参数需要学习。
我们可以将解码的结果以任何形式输出,例如解析树(parse tree)[6],或是图像的描述,假设有足够多包含描述的图像素材。当给图片添加描述时,你可以用图片训练一个神经网络来识别图像中的物体。然后,把神经网络输出层的权重值作为这幅图像的向量表示,再将这个向量用解码器解析出图像的描述[4,7]。(点击这里和这里查看示例)
从合成语义到关注、记忆和问答
刚才的编码器—解码器方法似乎像是小把戏,我们接着就慢慢的来看看其在实际场景的应用。我们可以把解码的过程想象成回答问题,“这句话该怎么翻译?”或者,已经有了待翻译的句子,并且一部分内容已经翻译了,那么“接下去该怎么写?”
为了回答这些问题,算法首先需要记住一些状态。在之前提到的例子中,系统只记住当前向量状态h以及最后写下的单词。若是我们想让它能运用之前全部所见所学该怎么办?在机器翻译的例子里,这就意味着在选择下一个单词时,要能够回溯之前的状态向量h0、h1、h2和h3。Bahdanau et al. [1]创造了能满足这种需求的网络结构。神经网络学习如何在每个决策点确定之前哪个记忆状态是最相关的。我们可以认为这是一个关注记忆的焦点。
它的意义在于,由于我们可以将概念和语句编码为向量,并且我们可以使用大量的向量作为记忆元素,通过搜索能找到问题的最佳答案,那么深度学习技术就能用文字来回答问题了。举一个最简单的例子[8],用表示问题的向量与表示记忆的向量做内积运算,把最吻合的结果作为问题的最佳回答。另一种方法是把问题和事实用多层神经网络进行编码,并把最后一层输出传给一个函数,函数的输出即为答案。这些方法都是基于模拟问答的数据来训练,然后用下文Weston[8]所示的方法回答问题。
下一个前沿方向是准确理解语义
刚刚讨论的方法是关于如何以读故事的方式回答问题,但是故事的一些重要情节一目了然,我们不必都写下来。设想桌上放着一本书。计算机如何才能知道你挪动桌子的同时也挪动了书本?同样的,计算机怎么知道屋外只是下雨了呢?就如Marvin Minsky所问,计算机如何知道你能用一根绳索拉箱子而不是推箱子呢?因为这些事实我们不会都写下来,故事将只限于能被我们算法所表示的知识。为了获取这部分知识,我们的机器人(robot)将通过实景体验或者模拟体验来学习。
机器人必须经历这种实景体验,并用深度神经网络编码,基于此可以构建通用语义。如果机器人总是看到箱子从桌上掉下来,它则会根据这一事件创建一条神经回路。当妈妈说“天啊,箱子跌落下来了”,这条回路将会和单词“跌落”结合。然后,作为一个成熟的机器人,当它再遇到句子“股票跌落了10个点”,根据这条神经回路,它就该理解其中的意思了。
机器人还需要把一般的实景体验与抽象推理相结合。试着来理解这句话的含义“他去了垃圾场。”(He went to the junkyard.)WordNet只能提供一组与“went”相关的单词。ConceptNet能把“went”和“go”联系在一起,但是永远也不明白“go”的真正意思是什么。FrameNet有一个self-motion的框架,已经非常接近了,但还是不够。深度学习能把句子编码成向量,然后回答各种问题,诸如用“垃圾场”回答“他在哪儿”的问题。然而,没有一种方法能够传递出一个人在不同位置这层意思,也就是说他既不在这里,也不在其它地方。我们需要有一个连接自然语言和语言逻辑的接口,或者是用神经网络对抽象的逻辑进行编码。
实践:深度学习的入门资源
入门的方法有很多种。斯坦福有一门用深度学习做NLP的公开课。也可以去看Hinton教授在Coursera Course的课程。另外,Bengio教授和他的朋友们也编写了一本简明易懂的在线教材来讲解深度学习。在开始编程之前,如果你使用Python语言,可以用Theano,如果你擅长Java语言,就用Deeplearning4j。
总结
计算机性能的提升和我们生活的日益数字化,推动了深度学习的革命。深度学习模型的成功是因为它们足够大,往往带有上百万的参数。训练这些模型需要足够多的训练数据和大量的计算。若要实现真正的智能,我们还需要走得更深。深度学习算法必须从实景体验中习得,并概念化这种经验,然后将这些经验与抽象推理相结合
关于作者

Jonathan是21CT的首席科学家。他主要研究机器学习和人工智能如何使用在文本和知识中让计算机变得更智能。他在德克萨斯农工大学获得心理学学士学位和工商管理硕士,在德克萨斯大学获得计算机博士学位。他也是《 Curiosity Cycle: Preparing Your Child for the Ongoing Technological Explosion》一书的作者。