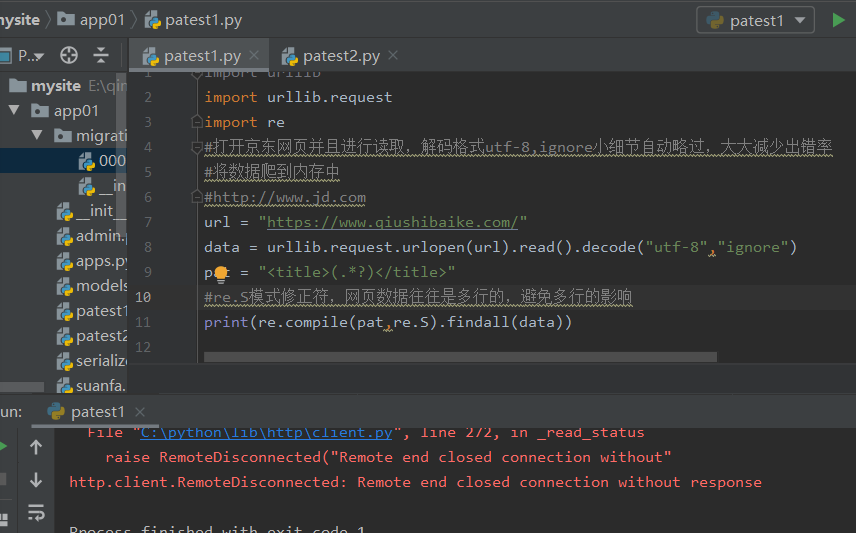
import urllib.request
import re
#浏览器伪装
#建立opener对象,opener可以进行设置
opener = urllib.request.build_opener()
#构建元祖User-Agent,键值
UA = ("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36")
#将其放入addheaders属性中
opener.addheaders = [UA]
#将opener安装为全局
urllib.request.install_opener(opener)
url = "http://www.qiushibaike.com"
pat = "<title>(.*?)</title>"
data = urllib.request.urlopen(url).read().decode("utf-8","ignore")
print(re.compile(pat,re.S).findall(data))