最近聆听了两个IEEE FELLOW的高论。周末北大林老师来学校做了个报告,讲了很多新的机器学习概念。但是本人更关注的低秩学习,林老师只字未提。虽然如此,林老师的论文最近还是深入研究了很多,有多少改进的空间先不说,一篇LADMAP就需要看好几篇论文甚至回溯到十几年前的一些论文。或者说,当目标函数中有多个要求的变量的时候,一般采用ADM方法。但是一般会选用ADM的改进方法,比如11年林老师的ALADMAP方法。然而光看这篇也不能看懂,因为算法中又使用了林老师10年的一篇论文的方法,简单说就是一个低秩学习的约束条件。不过这个约束条件,也许大牛们觉得不屑于用文字在论文里解释两行吧。。不过还是要感谢林老师提供了fast版的开源程序。
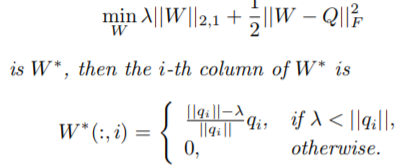
总之,低秩似乎还是在说降维的事。那么降维是为了加快计算是显而易见的,还有没有其他原因呢。
d为特征空间的维度,当其趋于无穷大时,距离测量开始失去其在高维空间中测量不相似性的有效性。这样,就需要寻找合适的度量,或者降维。
另一个问题就是惩罚项的问题。正好遇到北辰新聘的墨尔本的客座IEEE FELLOW,于是专门问了一下这个事。加惩罚项没关系,关键是损失函数和惩罚项要匹配,或者说这样凑成的目标函数之前有标准的被证明是凸的问题。再就是神经网络中如果增加惩罚项,也要考虑看相应的论文再采用能用的惩罚项策略。