写在前面
众所周知,scala一向宣称自己是面向函数的编程,(java表示不服,我是面向bean的编程!)那什么是函数?
在接触java的时候,有时候用函数来称呼某个method(实在找不出词了),有时候用方法来称呼某个method,虽然method的中文翻译就是“方法”,但对于java来说,方法和函数是等价的,或者说没有函数这个概念。
而对于scala,这两者似乎有一个较为明确的边界。
你会发现满世界的函数,而你却在写方法
Scala 方法&函数
方法
Scala的方法和java可以看成是一样的,只是多了点语法糖。
比如无参方法在申明时可以不加括号,甚至在调用过程也不用加括号
def f = 1+1 println(f)
比如方法可以添加泛型规则,这在java中只能在类申明
def f[T](t: T) = {t}
还有其它很多细节语法,遇到才深入吧
一般而言只要知道函数的结构就行(但是我想说,spark的代码就没有一个函数长成这样的啊..),请忽略下图的“函数”字样,其实就是方法
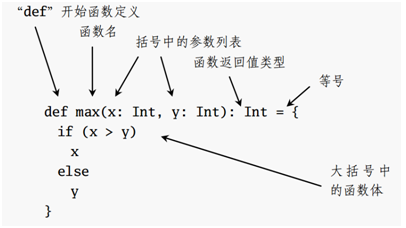
方法应用
def method(): Unit ={ //本地方法 def print(str:String): Unit ={ println(str) } print("hello") }
方法的语法还是跟java差不多的,只是有些可以省略而已。
比较重要的就是本地方法,即方法中嵌套方法
函数
Scala的函数是基于Function家族,0-22,一共23个Function Trait可以被使用,数字代表了Funtcion的入参个数
函数语法
下面这四个函数的意义是一样的
// println(fun1) // println(fun2) // println(fun3) // println(fun4) // 都为<function2> val fun1 = new Function2[Int,Int,Int]() { override def apply(v1: Int, v2: Int): Int = { v1+v2 } } val fun2 = new ((Int, Int) => Int)() { override def apply(v1: Int, v2: Int): Int = { v1+v2 } } val fun3 = (v1:Int,v2:Int) => v1+v2 // _可以把method转换成function val fun4 = fun4Method _ def fun4Method(v1:Int,v2:Int): Int = { v1+v2 }
一般我们都采用第三种fun3定义方式,也是最难懂的一个定义方式。具体结构参考下图

那函数有什么用呢?
Java里只有方法都能适应一切需求,那scala又提出函数的概念肯定有意义。
1.函数可以直接赋值给变量,可以让函数很方便的传递
2.闭包(closure),可以把灵活操作代码块,从而引申出其他灵活的语法
函数应用
在spark中,有很多方法入参中使用函数的场景,比如如下函数
defrunJob[T,U](fun: Iterator[T] => U ,resHandler: (Int, U) => Unit): Unit ={ //忽略里面的逻辑 }
其中的fun和resHandler都是函数
Fun是入参为Iterator[T],返回值为U的函数,一个入参的函数其实就是Function1的实例
resHandler是入参为Int和 U无返回值的函数,二个入参的函数其实就是Function2
模拟spark中常见的一段代码语法,拿一个普通scala类型的例子来说
//模拟spark的runJob方法 def runJob[T,U](fun: Iterator[T] => U ,resHandler: (Int, U) => Unit): Unit ={ val listBuffer = new ListBuffer[T] listBuffer.append("h".asInstanceOf[T]) listBuffer.append("e".asInstanceOf[T]) listBuffer.append("l".asInstanceOf[T]) listBuffer.append("l".asInstanceOf[T]) listBuffer.append("o".asInstanceOf[T]) //这里调用函数其实用到了伴生对象的概念,fun(xxx)就是fun.apply(xxx) val res = fun(listBuffer.iterator) //spark中,这里是每个partition的数据都存入arr,这里做模拟就一个partition了:) resHandler(0,res) } //模拟调用runJob的方法 def main(args: Array[String]): Unit = { val arr = new Array[String](1) //fun函数的实际逻辑 val fun = (it:Iterator[String]) => { val sb = new StringBuilder() while (it.hasNext) sb.append(it.next()) sb.toString() } //resHandler函数的实际逻辑 val resHandler = (i:Int,res:String) => arr(i) = res runJob[String,String](fun ,resHandler) println(arr.mkString("")) }
其实就是传递函数的逻辑,和java的匿名类差不多(只有一个方法的匿名类),只是多了点语法糖
这么做的好处也是不言而喻的
1.可以构造出更抽象的方法,使得代码结构更简洁
2.spark的思想就是lazy,而函数传递也是一个lazy的过程,只有在实际触发才会执行
偏函数
英文为PartialFunction,不知道这么翻译对不对,貌似都这么叫。
PartialFunction其实是Funtion1的子类
参考源码
trait PartialFunction[-A, +B] extends (A => B)
A => B就是标准的函数结构
那PartialFunction有什么作用呢?
模式匹配!
PartialFunction最重要的两个方法,一个是实际的操作逻辑,一个是校验,其实就是用来做模式匹配的。
参考资料
《Scala编程》