前言
对于流式计算(streaming)而言,窗口是一个永远绕不开的话题,最常见的需求,比如计算某个字段最近一小时的累积量,计算某个字段一天的出现的次数等。本篇文章针对流式计算的窗口模型(window model)进行深入解析。需要注意的是,本篇文章内容没有考虑容错问题,也就是默认本地内存中的数据不会丢失。
下面直奔主题,如果想更全面的了解流式计算和窗口模型,参考google大神的两篇博客。
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
基础窗口
通常情况下,我们理解窗口最多的是基于时间窗口,比如每过5分级计算某个字段的累积量,又或者是基于事件的窗口。而我认为,窗口应该是一个更广义的模型。
在流式计算中,数据是没有边界的,源源不断的数据从输入流向输出,但是计算是需要边界的,无论是增量计算还是全量计算,都需要一个范围。那么,把无限的数据流划分成一段一段的数据集,这个计算模型可以称为窗口模型。
基本的窗口模型,会根据时间来划分出一个一个有范围的窗口,在此基础上对一批数据集进行计算。那么问题来了,划分窗口的时间从哪来呢。一般情况下,有两种必定出现的时间,数据的发生时间(event time)和数据处理的时间(process time)。
这两个时间怎么选择呢,先来看一个例子,比如网页中一个事件的触发从而向后台提交了一条数据,后台把数据发到了kafka,另一端有一个kafka的消费者把数据取出来进行计算,那么数据发生时间就是该网页事件触发的时间,而数据处理时间则为最终计算这条数据的时刻。理想情况下,这两个时间是成正比关系的,也就是数据发生的越晚,那么数据处理的越晚,但现实总是残酷的,由于网络波动,硬件设备故障等原因,数据总是会不按顺序的被处理,参考图1(来源于引用)。
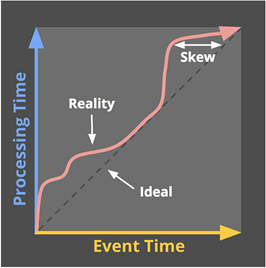
图1
在这个背景下,对时间的选择显得更加复杂。一般而言用的是数据产生的时间,更贴近业务的需求,所见即所得么,否则采用数据处理的时间会导致结果不稳定。
时间选择问题暂时解决了,那么数据不是连续的情况下,怎么划分出窗口,比如你想象中每过1分钟输出一个窗口,然而数据在59秒之后再也没有被接受直到几分钟之后。这显然是不满足需求的,所以,引入了watermark这个概念,个人认为翻译为水位线比水印更好理解,水印这概念太抽象了。
watermark用于判定是否到达窗口的阈值,也就是产生一个窗口,watermark会不断自我更新(说白了就是有个守护线程保证watermark不因为没有数据而不增长)。当watermark到达窗口的阈值,那么小于watermark的数据会进入到该窗口。而watermark也分为基于数据产生时间或者数据处理时间得到。
基于数据产生时间,那么会导致窗口的触发时间比理想慢很多,也就延迟大,因为数据是乱序进入的,需要等待直到数据的产生时间到达窗口阈值。
基于数据处理时间,那么会导致窗口内的数据缺失,理由有上面的差不多。
所以这就又引申出了另一个问题,这个问题可以通过触发器(trigger)解决。所谓触发器,其实就是根据不同的场景需求,给出最适合的窗口触发要求,比如基于watermark的触发器,基于事件的触发器,基于会话的触发器,更多参考streaming 102。触发器又是另一个层面的东西了,和实际业务有关,就不再赘述。
窗口的划分问题解决了,那么数据的生命周期是不是也得再思考一下?数据从输入到输出,可能会经历一个或者多个窗口,也可能由于延迟错过所有的窗口,这就需要定义一个清晰的范围来完整的给出数据的生命周期。这引入了一个新的概念lag,在‘watermark大于窗口结束时间+lag’这个前提下,该窗口满足‘数据的时间小于watermark-lag’的数据可以被释放,这个定义弥补了数据在生命周期管理的缺口。
高阶窗口
基础窗口介绍了窗口的基本思想和功能特性,可以满足绝大部分需求。下面说说窗口的其他特性,聚合和撤销(retracting)。
可能会出现这类需求,每次计算利用上一次计算后的结果,这样既避免了重复计算,又减少了内存缓存。但在流式计算中会有个问题,每次窗口计算得到的聚合结果可能不是正确的,再完美的触发器也会在某个窗口遗漏一些延迟数据,可能到下个窗口这些延迟的数据出现了,这就需要窗口支持撤销功能,也就是修改上一个窗口的统计结果,然后把修改后的结果一起发送到下个窗口。这样在下个窗口做统计的时候,就会修正之前错误的统计,并到达最优结果。
总结
批量计算其实是流式计算的一个子集,而窗口就是流式计算转为批量计算的临界点,所以这是及其重要的概念,另外更多的例子和实战参考apache beam,一个高度抽象的统一编程模式。