前言
本文通过对flume的架构,数据链路和数据的可靠性来分析flume的原理,并在文末提供了demo(官网搬运)。
架构
flume可以理解为是一个ETL工具,本身是单点的,也就是只有agent,没有server,但是通过强大的source-channel-sink-source…机制,可以通过在多个节点上起agent构成一个DAG,从而形成分布式形态。参考图1,图2(其他图就不贴了,参考官网文档),flume支持在任意节点启动任意数量的agent,并且agent与agent之间可以通过rpc连接。需要注意的是,1个source可以下发数据到多个channel(通过`ChannelSelector`,最常见的就是广播,或者动态路由),1个sink只能从1个channel获取数据,但是多个sink又可以从1个channel拉取数据(通过`SinkProcessor`)。这样的DAG设计意图很明显,source生产数据通常都是比sink处理数据快的,所以channel起到数据缓冲作用,并且通过事务机制保证数据的可靠性。试想一下场景,假如数据量很大,1个source消费速度跟不上,也就是说达到了单进程的性能瓶颈,那么可以启动多个agent;假如数据量一般,1个source就足够,但是处理很复杂比如IO密集型的操作,那么可以通过多sink的方式从channel拉数据,也就是sink端做负载均衡,比如`LoadBalancingSinkProcessor`。flume这样的设计很好的满足了各种场景需求。
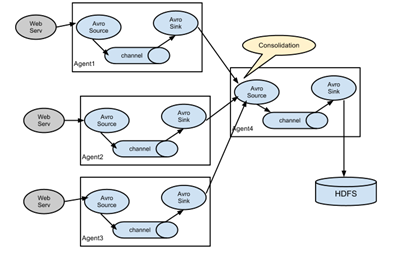
图1
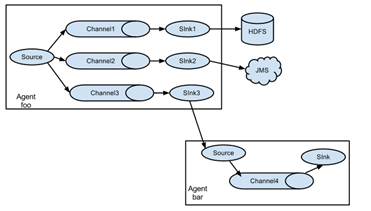
图2
数据链路
参考图3,flume的三个核心组件的数据链路是基于推送和拉取模式,其中Channel可以理解为列队,也是实现数据可靠性的关键组件。比如常见的,采用FileChannel之类落盘的channel场景中,当source推送数据到channel失败,那么就会触发source重试,当sink拉取数据操作失败,那么回通知channel回滚,直到sink操作成功才提交之前的那些数据,从而使得channel移除那些已经被成功处理的数据。

图3
flume的组件也不仅仅只有source,channel,sink这三个。参考图4,完整的数据链路还有ChannelProcessor和SinkeProcessor。ChannelProcessor主要功能有两个,1.对事件进行拦截,提供修改事件的入口; 2.对channel的选择,我们知道1个source可以发送数据到多个channel,但是具体发送到哪些channel呢?这里就是选择器决定了source发送到哪些channel。SinkProcessor的功能其实也类似,由于一个channel的事件可以被多个sink拉取,那么SinkProcessor决定了sink拉取的策略,这里flume衍生出了sinkGroup的概念,一般情况下,1个sink对应1个线程,而sinkGroup可以包含多个sink共用1个线程。
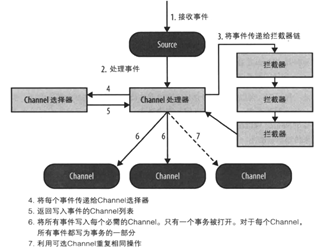
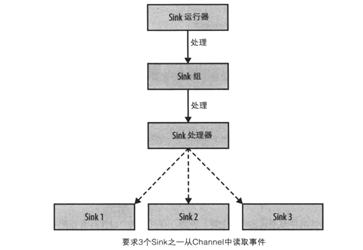
图4
数据可靠性
数据可靠性是非常重要的一个特性,所以拉出来单独做一下说明。
flume基于Channel和Transaction接口实现数据不丢失的特性。其中channel负责对数据持久化,维护了所有没有被事务提交的事件,Transaction负责实现事务语义,类似jdbc的事务语法,如下
Transaction tx = ch.getTransaction(); try { tx.begin(); ... // ch.put(event) or ch.take() ... tx.commit(); } catch (ChannelException ex) { tx.rollback(); ... } finally { tx.close(); }
通过这两个接口的保证,flume可以实现at leaset once的语义,这是由于sink可以出现rpc超时等一些问题,导致误以为失败导致事件被重复拉取。这个问题可以通过对事件分配唯一id,再通过其他大数据组件去重。
总结
flume提供一个灵活的设计思路,可以通过agent组合构建出符合自己需求的DAG,有点类似storm,但是程序更加轻量。并且提供了很多开箱即用的插件,可以说是很良心了。
demo
下面通过一个案例来了解flume,思路是构建基于netcat的agent,然后通过telnet进行验证。
# 创建一个新的flume配置文件
vi example.conf
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
# 启动flume agent,并开启http的度量监控,可以通过http请求获取相关度量数据
flume-ng agent --name a1 --conf-file example.conf -Dflume.root.logger=INFO,console -Dflume.monitoring.type=http -Dflume.monitoring.port=9999
# 通过telnet进行调试
telnet localhost 44444
# 发现消息,可以看到flume agent可以成功接收
参考
// flume官网文档以及源码
http://flume.apache.org/FlumeUserGuide.html
// 书乃本也~
《Flume 构建高可用、可扩展的海量日志采集系统》