一、文件操作
文件操作分为三个步骤:文件打开、操作文件、关闭文件,但是,我们可以用with来管理文件操作,这样就不需要手动来关闭文件。
实现原理:
import contextlib
@contextlib.contextmanager
def show():
print('123')
yield
print('456')
with show():
print('777')
print('888')
print('999')
操作步骤
#windows下默认为gbk,要指定编码为'utf-8'
#'r'为只读,'test.txt'为文件路径
f=open('test.txt','r',encoding='utf-8') #utf-8编码方式打开文件
data=f.read() #操作文件
f.close() #关闭文件
print(data)
# 用with语句打开,不需要手动关闭
with open('test.txt','r',encoding='utf-8') as f:
print(f.read())
示例
# r,只读模式【默认,不存在则报错】
# w,只写模式【不可读:不存在则创建;存在则清空内容】
# x,只写模式【不可读:不存在则创建,存在则报错】
# a,追加模式【不可读;不存在则创建;存在则只追加内容】
# "+"表示可以同时读写某个文件,比如r+、w+、x+、a+
# "b"表示以字节的方式操作,rb或r+b,wb或w+b,xb或x+b,ab或a+b,
# 以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,这些都需要程序员来做转换。
# f.tell() 读取指针的位置
# f.seek() 设置指针的位置
# r只读(不存在则报错)
with open('test.txt', 'r', encoding='utf-8') as f:
print(f.read()) # test.txt,不存在,报错
# w只写(不可读,不存在创建,存在则清空)
with open('test.txt', 'w') as f:
f.write('123') # 创建test.txt 写入新内容123
# x只写(不可读,不存在创建,存在报错)
with open('test.txt', 'x') as f:
f.write('666') # 这里存在,报错
# a追加模式(不可读,不存在创建,存在往末尾追加)
with open('test.txt', 'a') as f:
f.write('111') # 往test.txt里面追加111
# 以字节方式打开,将test.txt里面的文件内容清空,往里面写入'大家好',需要将内容转换成bytes类型
with open('test.txt', 'wb') as f:
str_data = '大家好'
byte_data = str_data.encode('utf-8')
f.write(byte_data)
# 以rb读
with open('test.txt', 'rb') as f:
data = f.read()
print(data) # b'xe5xa4xa7xe5xaexb6xe5xa5xbd'
print(type(data)) # 打印出读取的类型<class 'bytes'>
str_data = data.decode('utf-8')
print(str_data) # 大家好
# r+形式 写的时候在末尾追加,指针移到到最后
with open('test.txt','r+',encoding='utf-8') as f:
print(f.tell()) # 打印下 文件开始时候指针指向哪里 这里指向 0
print(f.read()) # 读出文件内容'大家好'
print(f.tell()) # 文件指针指到 9,一个汉子三个字符串,指针是以字符为单位
f.write('我在学习') # 写入内容'我在学习',需要特别注意此时文件指针在末尾
print(f.read()) # 指针到末尾去了,所以读取的内容为空
print(f.tell()) # 指针指到15
f.seek(0) # 将指针内容指到 0 位置
print(f.read()) # 因为文件指针指到开头去了,所以可以读到内容 大家好我在学习
# w+形式 存在的话先清空 一写的时候指针到最后
with open('test.txt', 'w+') as f:
f.write('python') # test.txt存在,所以将内面的内容清空,然后再写入 'python'
print(f.tell()) # 此时指针指向6
print(f.read()) # 读不到内容,因为指针指向末尾了
f.seek(0) # 移动指针到开头
print(f.read()) # 读到内容
# a+打开的时候指针已经移到最后,写的时候不管怎样都往文件末尾追加
with open('test.txt', 'a+') as f:
print(f.tell())
f.write(' is best')
print(f.read()) # 读不到内容,因为指针指向末尾了
f.seek(0) # 移动指针到开头
print(f.read()) # 读到内容
# x+文件存在的话则报错
with open('test.txt', 'x+') as f: # FileExistsError: [Errno 17] File exists: 'test.txt'
print(f.tell())
f.write(' hello')
print(f.read())
f.seek(0)
print(f.read())
同时操作多个文件
# 拷贝A文件到B文件中
with open('A.txt','r',encoding='utf-8') as fr,open('B.txt','w',encoding='utf-8') as fw:
for line in fr: # 一行行的读
fw.write(line) # 一行行的写
二、字符编码
在python中,编码是一个比较折腾的难点,特别是python2。
首先,了解下这几种编码:
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号,显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
在python3中,字符串编码是unicode,默认文件编码是utf-8(存在硬盘上的文件),所以可以省略文件头编码声明:#-*- coding:utf-8 -*-
读取到内存会被python解释器自动转换成unicode
而且,所有的unicode字符编码后都会变成bytes类型
但是如果是其他文件编码,如gbk,则需要声明文件编码:#-*- coding:gbk -*-,但是以gbk读取到内存中后,依然会转为unicode
总之,以什么编码方式存在硬盘上(代码字符串文件头定义的编码,比如:# -*- coding:utf8 -*-),就用什么编码方式从硬盘上读,不管什么编码方式,python3都会将字符串在内存中转为unicode
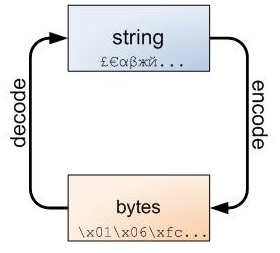
py3自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8

#-*- coding:utf-8 -*-
import sys
print(sys.getdefaultencoding()) # utf-8
s = '你好'
print(s) # 你好
print(type(s)) # <class 'str'>
print(s.encode()) # b'xe4xbdxa0xe5xa5xbd'
s_to_gbk = s.encode('gbk') # 编码成gbk
print(s_to_gbk) # b'xc4xe3xbaxc3'
print(s_to_gbk.decode('gbk').encode('utf-8')) # gbk转成utf-8,和上面s.encode()一样,b'xe4xbdxa0xe5xa5xbd'
三、练习题(参考答案已放在Q群文件中)
1.实现简单的shell sed替换功能
2.注册
注册信息存放在文件中
3.模拟登陆
连续登陆失败三次,就锁定用户