Java集合

HashSet集合

补充:hashCode()相同,但equals()不一定相同(大部分都是相同);hashCode()不相同,那equals()一定不相同;如果equals()不相同,但hashCode()有可能相同(小概率)。底层原理暂时没理解,详细可以点击:这里
所以重写equals的时候,有必要重写hashCode(),保证数据唯一性,即:equals相同时,hashCode也相同;hashCode()相同时,equals也相同,达成充要条件。
HashSet相关方法
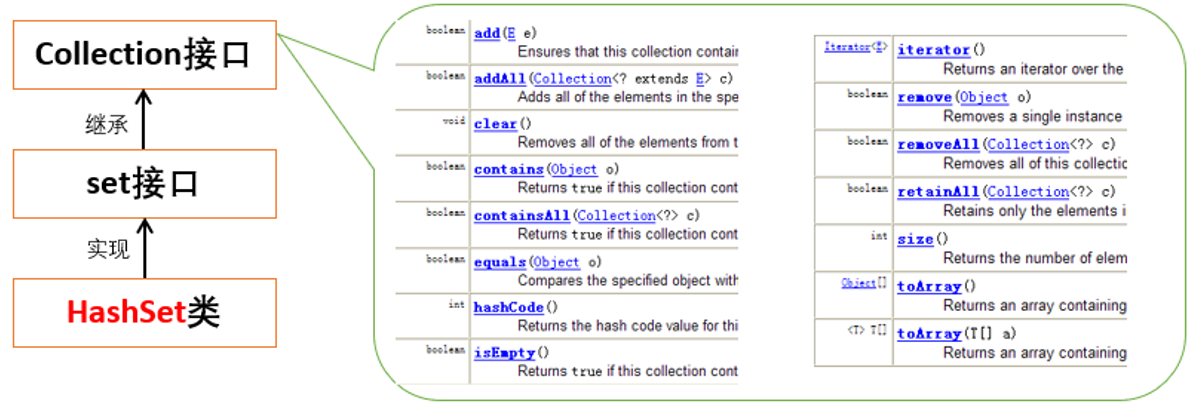
Collection集合遍历的Iterator迭代器

for each增强循环

hashCode()方法

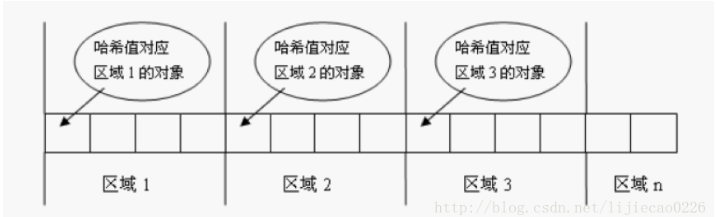
补充:hashSet的底层是通过hashMap实现的,hashMap的put()方法实现:会先比较hashCode,再比较equals。
之所以先比较hashCode是因为每个引用类型的数据都是根据hashCode()存储的,hashCode()把数据分到了不同区域,这样比较的时候可以迅速的找到hashCode计算的哈希值找到同一的区域,不用遍历整个集合浪费时间。
例子


import java.util.HashSet; import java.util.Iterator; import java.util.Set; /** * * @author leak * HashSet集合的常用方法 */ public class Test4 { public static void main(String[] args) { Set set = new HashSet(); //集合里面存储都是引用类型 //add()方法添加元素进集合 set.add(1);//这里虽然存储了基本数据类型,但是会自动转为包装类存储 set.add("a"); System.out.println(set); //remove()移除集合元素 set.remove(1); System.out.println(set); //contains()判断集合是否包含该值,返回布尔类型 System.out.println(set.contains("a")); //clear()清空集合所有元素 set.clear(); System.out.println(set); //集合遍历 set.add("a"); set.add("b"); set.add("c"); set.add("d"); set.add("d");//set集合存的值是不重复的 System.out.println("大小还是:"+set.size()); set.add(null);//集合可以存储null //输出set集合,可以看出排序是根据hashCode()排序 //set集合是无顺序存储的 System.out.println(set); //从这里可以看出set集合可以存储不同引用类型的对象 set.add(1); set.add(true); set.add(null); //方法一:使用迭代器遍历集合 //创建迭代器对象 Iterator it = set.iterator(); //hasNext()判断是否存在元素 while(it.hasNext()) { //存在,则打印输出 System.out.println(it.next()); } //方法二:for each增强循环 //set集合里面的每一个元素赋值给o变量 for(Object o : set) { System.out.println(o); } //集合的大小,数组是长度length,集合是size System.out.println(set.size());//获取集合的元素个数 } }
泛型
Collection集合可以存储不同的引用数据类型,那么如果只想用存储一种引用类型的集合,那怎么办呢?就需要用到泛型来约束集合存储的类型。(补充:无论泛型是哪种,add()方法都可以添加null,但是还是不要添加null进去,有些类型会报空指针异常)
泛型指定集合的数据类型,但是泛型只能指定引用数据类型,不能指定基本数据类型。
public class Test5 { public static void main(String[] args) { //泛型,集合可以通过泛型指定引用数据类型 //注意:泛型只能使用引用数据类型,不能使用基本数据类型 //指定String为集合的泛型,那么这个集合不能存String类型之外类型,否则报错 Set<String> set = new HashSet<String>(); set.add("a"); set.add("b"); //下面的三种类型都会报错,因为set集合已经使用了泛型String约束 // set.add(1);Set<String> set = new HashSet<String>(); // set.add(true); // set.add('a'); //补充:Set<Object> set = new HashSet<Object>(); // 等同于 Set set = new HashSet();这里省略了泛型就是Object } }
TreeSet集合
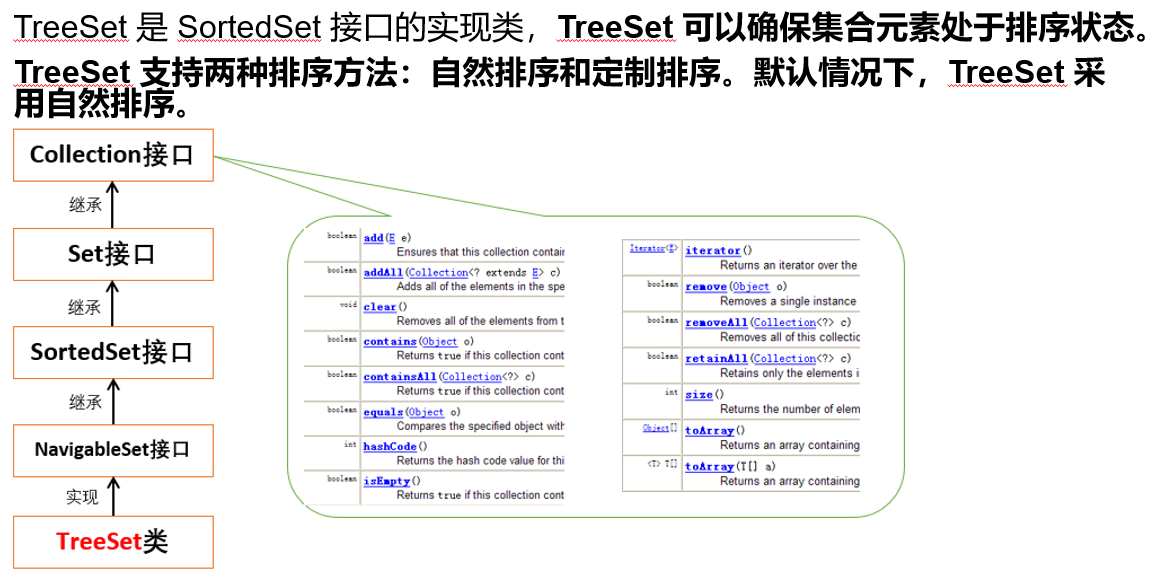
TreeSet默认的自然排序

TreeSet集合是通过compareTo()方法进行排序,对集合中的元素从小到大排序(正序)。
import java.util.Iterator; import java.util.Set; import java.util.TreeSet; public class Test6 { public static void main(String[] args) { //TreeSet默认自然排序,也就是有序存储 //TreeSet的增删 包含 清空方法都是和hashSet一致,迭代器,for each都是 //这里泛型类型指定Integer,只能存储Integer类型,基本的数据类型int会自动转为包装类 Set<Integer> set = new TreeSet<Integer>(); set.add(1); // set.add(1.21);//会报错 set.add(2); set.add(9); set.add(4); set.add(3); System.out.println(set);//TreeSet自然排序 //增加元素 set.add(129); System.out.println(set); //删除元素 set.remove(32); System.out.println(set); //判断是否元素存在于集合 System.out.println(set.contains(32)); //清空集合 set.clear(); System.out.println(set); //集合的大小,数组是length System.out.println(set.size()); //方法一:使用迭代器遍历集合 //创建迭代器对象 Iterator it = set.iterator(); //hasNext()判断是否存在元素 while(it.hasNext()) { //存在,则打印输出 System.out.println(it.next()); } //方法二:for each增强循环 //set集合里面的每一个元素赋值给o变量 for(Object o : set) { System.out.println(o); } } }
TreeSet定制排序
如果需要实现定制排序,则需要在创建 TreeSet 集合对象时,提供一个 Comparator 接口的实现类对象。由该 Comparator 对象负责集合元素的排序逻辑。
import java.util.Comparator; import java.util.Set; import java.util.TreeSet; public class Test7 { public static void main(String[] args) { Set<Person> set = new TreeSet<Person>(new Person()); Person p1 = new Person(12,"ds"); Person p2 = new Person(22,"asd"); Person p3 = new Person(34,"dbd"); Person p4 = new Person(232,"dwe"); Person p5 = new Person(11,"osb"); set.add(p1); set.add(p2); set.add(p3); set.add(p4); set.add(p5); //遍历打印 for(Person p : set) { System.out.println(p.age+" "+p.name); } } } //定制逻辑排序,为什么实现Comparator要用类呢,因为比较只能比较同一类型 //所以要使用一个类去实现Comparator接口,才能重写里面的compare比较方法 //不同类型,比较的内容不一样,所以要使用类来实现Comparator接口 class Person implements Comparator<Person>{ int age; String name; public Person() {} public Person(int age,String name) { this.age = age; this.name = name; } //定制排序逻辑在compare方法中实现 //接口必须重写的方法 @Override public int compare(Person o1, Person o2) { //正序排序,从小到大,正序和倒序区别,比较下面的就知道了 if(o1.age > o2.age) { return 1; }else if(o1.age < o2.age) { return -1; }else { return 0; } } // @Override // public int compare(Person o1, Person o2) { // //倒序排序,从大到小 ,区别在于 o1.age和o2.age相比返回什么,1/-1 // if(o1.age < o2.age) { // return 1; // }else if(o1.age > o2.age) { // return -1; // }else { // return 0; // } // } }
List和ArrayList

例子
import java.util.ArrayList; import java.util.List; /** * * @author leak * ArrayList和HashSet是相反的 * ArrayList是有序,且元素可重复 * HashSet是无序,且元素不重复 */ public class Test8 { public static void main(String[] args) { List<String> list = new ArrayList<String>(); //ArrayList的add方法默认按照添加元素顺序存储(有序) list.add("A");//第一个,索引下标0 list.add("B");//索引下标1 list.add("C");//索引下标2 list.add("D");//索引下标3 list.add("A");//索引下标4,运行使用重复元素 System.out.println(list); //get(index)根据索引下标获取元素 System.out.println(list.get(2));//通过索引访问指定位置的集合元素 //add(index,value)可以指定位置添加元素 //add(value) list.add("a"); list.add(2,"df");//指定索引下标位置插入数据 System.out.println(list); //ArrayList集合合并 List<String> list1 = new ArrayList<String>(); list1.add("1"); list1.add("2"); //addAll(value)默认插入到最后位置 //addAll(index,value)指定索引位置插入 list.addAll(2,list1);//把一个集合添加进集合里面 System.out.println(list); //indexOf(value)获取指定元素在集合中第一次出现的下标 //lastIndexOf(value)获取指定元素在集合中最后一次出现的下标 System.out.println(list.indexOf("A"));//0 System.out.println(list.lastIndexOf("A"));//7 //remove(index)根据指定的索引下标移除元素 list.remove(0); System.out.println(list); //set(index,value)根据指定索引下标,修改元素 list.set(0,"A"); System.out.println(list); //subList(start,end)根据索引下标截取指定范围的集合元素 //这里的end不包含结束,也就是(2,4)只包含了2,3 List<String> sublist = list.subList(2, 4); System.out.println(sublist); //集合大小 System.out.println(list.size()); } }
补充:

Set/List小总结:Set集合是无序,且不可重复;List集合是有序,且可重复。(也就是set和list集合是相反的)通常说的set集合值的是hashSet集合,TreeSet是有序,且不可重复。通常的list集合是说ArrayList集合。
Map集合

Map接口和HashMa集合常用方法
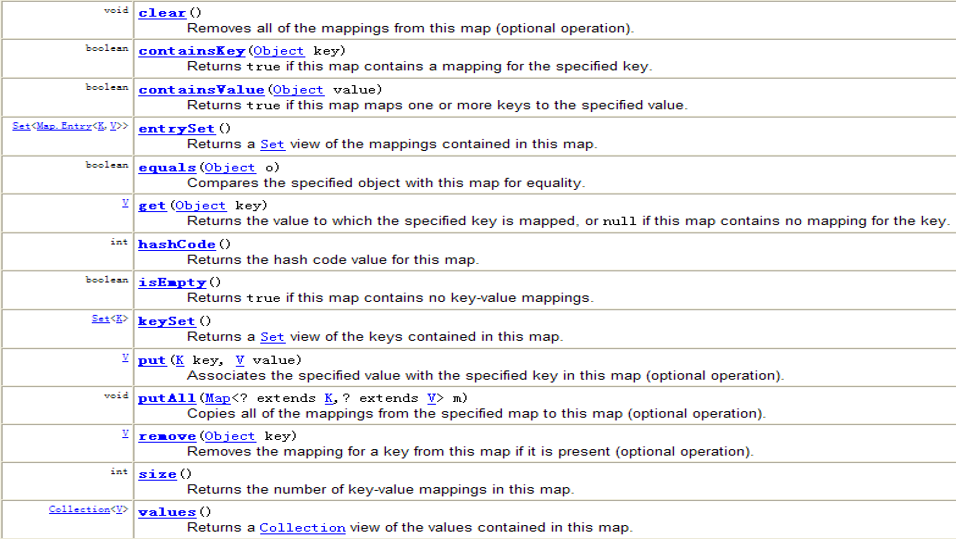
例子
import java.util.Collection; import java.util.HashMap; import java.util.Map; import java.util.Map.Entry; import java.util.Set; /** * * @author leak * map集合 * 通常的map集合指的是HashMap * */ public class Test9 { public static void main(String[] args) { Map<String,Integer> map = new HashMap<String,Integer>(); //put(key,value)键值对添加元素 map.put("b",1); map.put("c",3); map.put("e",2); System.out.println(map); //get(key)根据key取value的值 System.out.println(map.get("e")); //remove(key)根据key移除键值对 System.out.println(map.remove("c")); //size()获取集合的大小 System.out.println(map.size()); //containsKey(key)根据key判断集合是否存在该key System.out.println(map.containsKey("b")); //containsValue(value)根据value判断集合是否存在该value System.out.println(map.containsValue(2)); //clear()清空集合map.clear() //遍历map集合,通过map.keySet()方法获取key的集合 Set<String> keys = map.keySet();//使用set接口存储map的key集合 //遍历map集合,二次取值,根据key取value for(String key : keys) { System.out.println("key: "+key+" value: "+map.get(key)); } System.out.println(); //通过map.entrySet()返回键值对所有的集合 //entrySet返回的键值对集合就是一个个的map集合,类似二维数组存储方式 Set<Entry<String,Integer>> entrySet = map.entrySet(); for(Entry<String,Integer> entry : entrySet) { System.out.println("key: "+entry.getKey()+" value: "+entry.getValue()); } System.out.println(); //遍历map集合的所有value //map.values()获取集合的所有value的元素,不包含key Collection<Integer> values = map.values(); for(Integer value : values) { System.out.print("value: "+value+" "); } System.out.println(); } }
HashMap和Hashtable

TreeMap

TreeMap和TreeSet差不多,都是有序。只有可重复/不可重复的区别。
import java.util.Map; import java.util.TreeMap; /** * * @author leak * TreeMap默认自然排序,数字比字母优先级高,先按照数字排完才到字母排序,是根据key排序 */ public class Test10 { public static void main(String[] args) { //TreeMap的自然排序是字典排序 Map<Integer,String> map = new TreeMap<Integer,String>(); map.put(4,"a"); map.put(2,"a"); map.put(3,"a"); map.put(1,"b"); System.out.println(map); //数字先排序完,再字母排序 Map<String,String> map1 = new TreeMap<String,String>(); map1.put("32","a"); map1.put("a","c"); map1.put("ab", "ds"); map1.put("11","1"); map1.put("d","a"); map1.put("1","b"); System.out.println(map1); //剩下的方法就不演示了,可以参照上面的TreeSet方法差不多 //定制排序 } }
map集合的key是唯一的,如果对同一个key进行赋值,后面的会覆盖前面的key赋值。
工具类Collections

例子
import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; public class Test11 { public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("b"); list.add("cd"); list.add("ca"); list.add("d"); list.add("1"); System.out.println("list集合根据插入顺序排序: "+list); //Collections.reverse(list)集合排序反转 Collections.reverse(list); System.out.println("颠倒排序: "+list); //Collections.shuffle(list)随机排序 Collections.shuffle(list); System.out.println("随机排序:"+list); //Collections.sort(stus,new Student())字典升序排序 Collections.sort(list); System.out.println("调用自然排序:"+list); //Collections.swap(list,arg1,arg2)交换list集合中的arg1和arg2的位置 ,元素交换 Collections.swap(list, 0, 4); System.out.println("调换了0和4的位置后: "+list); //下面测试定制排序 Student s1 = new Student(12,"si"); Student s2 = new Student(21,"ga"); Student s3 = new Student(54,"yi"); Student s4 = new Student(11,"di"); List<Student> stus = new ArrayList<Student>(); stus.add(s1); stus.add(s2); stus.add(s3); stus.add(s4); //下面遍历并没有按照年龄进行排序 //Student类明明实现了Comparator接口,但是TreeSet会根据年龄排序,为什么ArrayList就没有按照年龄排序呢 //TreeSet会自动调用定制排序,但是ArrayList不会自动调用定制排序 for(Student stu : stus) { System.out.println("age: "+stu.age+" name: "+stu.name); } //ArrayList调用定制排序需要使用Collections.sort(list,new XX())方法,才会调用定制排序进行年龄排序、 //补充:Collections.sort(list)只会调用默认的自然排序,上面多个一个参数的才是调用定制排序 Collections.sort(stus,new Student()); System.out.println("--------------------"); //下面遍历按照年龄进行排序,因为sort方法调用了定制排序 for(Student stu : stus) { System.out.println("age: "+stu.age+" name: "+stu.name); } } } //定制排序 class Student implements Comparator<Student>{ int age; String name; public Student() {} public Student(int age,String name) { this.age = age; this.name = name; } //根据年龄升序排序 @Override public int compare(Student o1, Student o2) { if(o1.age > o2.age) { return 1; } else if(o1.age < o2.age) { return -1; } else { return 0; } } }
补充:为什么ArrayList要使用sort(List,Comparator)才会调用定制排序,TreeSet会自动调用定制排序。
对比TreeSet和ArrayList不同代码区别:
TreeSet: Set<Person> set = new TreeSet<Person>(new Person());
ArrayList: List<Student> stus = new ArrayList<Student>(); Collections.sort(stus,new Student());
Collection的查找/替换

例子
import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; public class Test12 { public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("b"); list.add("ca"); list.add("ca"); list.add("d"); list.add("b"); list.add("1"); //下面测试定制排序 Student1 s1 = new Student1(12,"si"); Student1 s2 = new Student1(21,"ga"); Student1 s3 = new Student1(54,"yi"); Student1 s4 = new Student1(11,"di"); List<Student1> stus = new ArrayList<Student1>(); stus.add(s1); stus.add(s2); stus.add(s3); stus.add(s4); //Collections.sort(stus,new Student())字典升序排序 Collections.sort(list); System.out.println("调用自然排序:"+list); //Collections.max(list)获取集合中最大的元素 String max = Collections.max(list); System.out.println("自然排序最大元素:"+max); //Collections.min(list)获取集合最小的元素 String min = Collections.min(list); System.out.println("自然排序最小元素:"+min); //排序 Collections.sort(stus,new Student1()); System.out.println("--------------------"); //下面遍历按照年龄进行排序,因为sort方法调用了定制排序 for(Student1 stu : stus) { System.out.println("age: "+stu.age+" name: "+stu.name); } //Collections.max(list,class);获取集合中定制类中最大的元素 Student1 max2 = Collections.max(stus,new Student1()); System.out.println("定制排序最大元素:"+max2.age+" "+max2.name); //Collections.min(list,class);获取集合中定制类中最小的元素 Student1 min2 = Collections.min(stus,new Student1()); System.out.println("定制排序的最小元素: "+min2.age+" "+min2.name); //Collections.frequency(集合, 元素)统计元素在集合中出现的次数 Object arg = "b"; int i = Collections.frequency(list,arg); System.out.println(arg+"元素出现的次数:"+i); //Collections.replaceAll(集合,旧元素,新元素);注意是替换全部,不是一个元素 System.out.println("替换前的集合:"+list); Collections.replaceAll(list, "b","bb"); System.out.println("替换后的集合:"+list); } } //定制排序 class Student1 implements Comparator<Student1>{ int age; String name; public Student1() {} public Student1(int age,String name) { this.age = age; this.name = name; } //根据年龄升序排序 @Override public int compare(Student1 o1, Student1 o2) { if(o1.age > o2.age) { return 1; } else if(o1.age < o2.age) { return -1; } else { return 0; } } }
同步控制
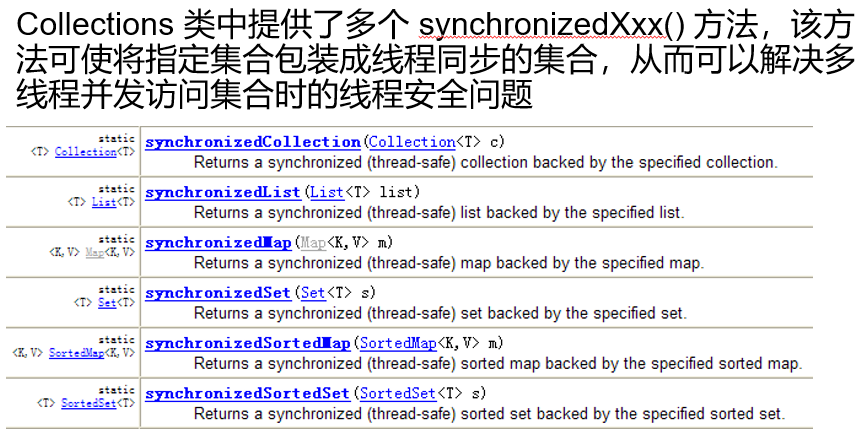
这里暂时不演示,等到多线程的时候。