搭建rabbitmq的高可用集群,分三步走:
1)搭建rabbitmq集群:
多机集群搭建
1.安装单机版的 教程:《Linux下安装rabbitmq》
(安装rpm包或者源码包,这里简单介绍下安装rpm包)
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.1/rabbitmq-server-3.5.1-1.noarch.rpm rpm -i --nodeps rabbitmq-server-3.5.1-1.noarch.rpm 3、安装RabbitMQ rpm -ivh rabbitmq-server-3.5.1-1.noarch.rpm 或 $$$ rpm -ivh --nodeps --force rabbitmq-server-3.5.1-1.noarch.rpm 启动RabbitMQ: /etc/init.d/rabbitmq-server start 或 service rabbitmq-service start 打开web管理插件 rabbitmq-plugins enable rabbitmq_management 管理界面地址:http://127.0.0.1:15672/ MQ新建用户 rabbitmqctl add_user admin admin 授权 rabbitmqctl set_user_tags admin administrator rabbitmqctl set_permissions -p "/" admin".*" ".*" ".*"
注意:不同于单机多节点的情况,在多机环境,如果要在cluster集群内部署多个节点,需要注意两个方面:
1)保证需要部署的这几个节点在同一个局域网内
2)需要有相同的Erlang Cookie,否则不能进行通信,为保证cookie的完全一致,采用从一个节点copy的方式,下面就会使用这种方式
2.要搭建集群,先将之前单机版中历史记录干掉,删除rabbitmq/var/lib/rabbitmq/mnesia下的所有内容。
3.分别在192.168.1.103 192.168.1.104 192.168.1.105节点上安装rabbitmq server。
4.在浏览器访问每一个rabbitmq实例,是够可以显示登录页面,如果显示成功,继续往下进行。
5.设置不同节点间同一认证的Erlang Cookie
将192.168.1.103上的rabbitmq/var/lib/rabbitmq/.erlang.cookie中的内容复制到192.168.1.104和192.168.1.105上的rabbitmq/var/lib/rabbitmq/.erlang.cookie文件中,
即三台服务器必须具有相同的cookie,如果不相同的话,无法搭建集群
注意:
官方在介绍集群的文档中提到过.erlang.cookie一般会存在这两个地址:第一个是$home/.erlang.cookie也就是/root 目录下,
第二个地方就是/var/lib/rabbitmq/.erlang.cookie。
如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在$home目录下,也就是$home/.erlang.cookie。
如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。
6.分别在三个节点的/etc/hosts下设置相同的配置信息,然后重启机器
192.168.1.103 rabbit1
192.168.1.104 rabbit2
192.168.1.105 rabbit3
重启之后[root@localhost ~]# 改为[root@rabbit1 ~]# hostname就会生效
7.使用 -detached运行各节点
rabbitmq-server -detached
8.创建集群
1)rabbit1为主节点,另外两个为从节点搭建,主节点不用动,只在两个从节点运行如下命令,我这里只举一个节点(rabbit2)的例子,rabbit3执行相同的命令
[root@rabbit2 rabbitmq]# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@rabbit2 ...
[root@rabbit2 rabbitmq]# rabbitmqctl reset
Resetting node rabbit@rabbit2 ...
[root@rabbit2 rabbitmq]# rabbitmqctl join_cluster rabbit@rabbit1
Clustering node rabbit@rabbit2 with rabbit@rabbit1 ...
[root@rabbit2 rabbitmq]# rabbitmqctl start_app
Starting node rabbit@rabbit2 ...
2)使用rabbitmqctl cluster_status查看集群状态
[root@rabbit2 rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit2">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit2,[]}]}]
9.我这里创建完成之后,之前的admin用户无法使用了,重新添加用户,参考之前搭建单机版的命令
10.使用刚才的账号密码登录,出现界面,表示成功。
二)安装haproxy
.Haproxy负载代理
1)在192.168.1.101和192.168.1.102节点上安装haproxy
yum install haproxy
2)修改/etc/haproxy/haproxy.cfg为以下内容,全覆盖,修改对应的端口号
#--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global log 127.0.0.1 local2 chroot /var/lib/haproxy # 改变当前工作目录 pidfile /var/run/haproxy.pid # haproxy的pid存放路径,启动进程的用户必须有权限访问此文件 maxconn 4000 # 最大连接数,默认4000 user haproxy # 默认用户 group haproxy # 默认组 daemon # 创建1个进程进入deamon模式运行。此参数要求将运行模式设置为daemon stats socket /var/lib/haproxy/stats # 创建监控所用的套接字目录 #--------------------------------------------------------------------- # defaults settings #--------------------------------------------------------------------- # 注意:因为要使用tcp的负载,屏蔽掉与http相关的默认配置 defaults mode http # 默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK log global # option httplog # 采用http日志格式 option dontlognull # 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器 # option http-server-close # 每次请求完毕后主动关闭http通道 # option forwardfor except 127.0.0.0/8 # 如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip option redispatch # serverId对应的服务器挂掉后,强制定向到其他健康的服务器 retries 3 # 3次连接失败就认为服务不可用,也可以通过后面设置 # timeout http-request 10s timeout queue 1m timeout connect 10s # 连接超时时间 timeout client 1m # 客户端连接超时时间 timeout server 1m # 服务器端连接超时时间 # timeout http-keep-alive 10s timeout check 10s maxconn 3000 # 最大连接数 ###################### 打开haproxy的监测界面############################### listen status bind 0.0.0.0:9188 mode http stats enable stats refresh 30s stats uri /stats #设置haproxy监控地址为http://localhost:9188/stats stats auth admin:123456 #添加用户名密码认证 stats realm (Haproxy statistic) stats admin if TRUE ######################监听rabbitmq的web操作页面############################ listen rabbitmq_admin bind 0.0.0.0:15670 server rabbit1 192.168.1.102:15672 server rabbit2 192.168.1.101:15672 server rabbit3 192.168.1.101:15673 #######################监听rabbimq_cluster ################################# listen rabbitmq_cluster bind 0.0.0.0:5670 mode tcp balance roundrobin #负载均衡算法(#banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数) server rabbit1 192.168.1.102:5672 check inter 5000 rise 2 fall 2 #check inter 2000 是检测心跳频率 server rabbit2 192.168.1.101:5672 check inter 5000 rise 2 fall 2 #rise 2是2次正确认为服务器可用 server rabbit3 192.168.1.101:5673 check inter 5000 rise 2 fall 2 #fall 2是2次失败认为服务器不可用
3)启动haproxy
haproxy -f /etc/haproxy/haproxy.cfg
service haproxy restart#重启
service haproxy stop#停止
4)两个ip分别访问以下地址,出现以下页面证明没错
浏览器访问:192.168.0.101:15670 和 192.168.0.101:9188/stats
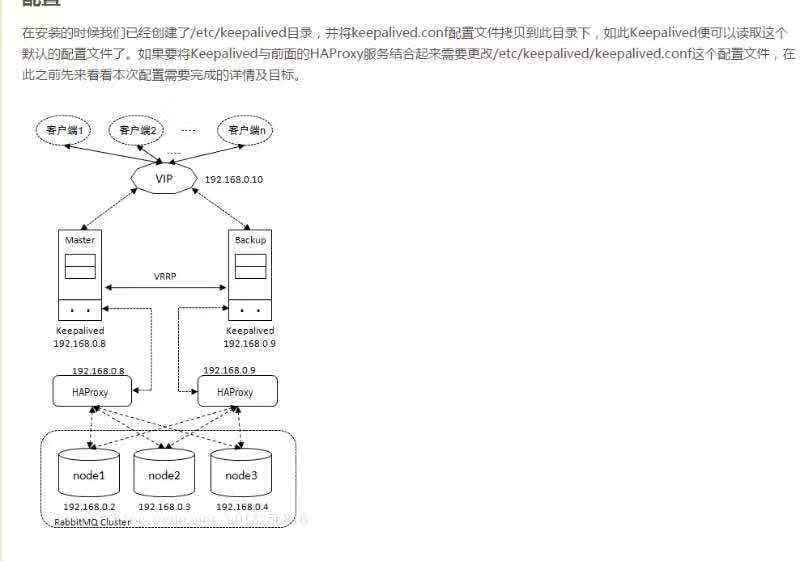
三)安装配置keepalived
1)安装keepalived
yum install keepalived
chkconfig --add keepalived#设置开机启动,可以不用设置
2)修改/etc/keepalived/keepalived.conf配置文件,主机和备机稍有不同,已经在配置文件中声明,请详细阅读!
#Keepalived配置文件
global_defs { router_id NodeA #路由ID, 主备的ID不能相同 } #自定义监控脚本 vrrp_script chk_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 5 weight 2 } vrrp_instance VI_1 { state MASTER #Keepalived的角色。Master表示主服务器,从服务器设置为BACKUP interface eth0 #指定监测网卡 virtual_router_id 1 priority 100 #优先级,BACKUP机器上的优先级要小于这个值 advert_int 1 #设置主备之间的检查时间,单位为s authentication { #定义验证类型和密码 auth_type PASS auth_pass root123 } track_script { chk_haproxy } virtual_ipaddress { #VIP地址,可以设置多个: 192.168.0.10 } }
Backup中的配置大致和Master中的相同,不过需要修改global_defs{}的router_id,比如置为NodeB;其次要修改vrrp_instance VI_1{}中的state为BACKUP;最后要将priority设置为小于100的值。注意Master和Backup中的virtual_router_id要保持一致。下面简要的展示下Backup的配置:
global_defs { router_id NodeB } vrrp_script chk_haproxy { ... } vrrp_instance VI_1 { state BACKUP ... priority 50 ... }
为了防止HAProxy服务挂了,但是Keepalived却还在正常工作而没有切换到Backup上,所以这里需要编写一个脚本来检测HAProxy服务的状态。当HAProxy服务挂掉之后该脚本会自动重启HAProxy的服务,如果不成功则关闭Keepalived服务,如此便可以切换到Backup继续工作。这个脚本就对应了上面配置中vrrp_script chk_haproxy{}的script对应的值,/etc/keepalived/check_haproxy.sh的内容如代码清单所示。
#!/bin/bash if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then haproxy -f /etc/haproxy/haproxy.cfg fi sleep 2 if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then service keepalived stop fi
3)启动服务
因为是为了实现haproxy的高可用,启动时需要顺序启动:
(1) 启动两个节点的haproxy:
haproxy -f /etc/haproxy/haproxy.cfg
(2) 启动keeepalived:先启动master节点,后启动BACKUP节点
keepalived start
如此配置好之后,使用service keepalived start命令启动192.168.0.8和192.168.0.9中的Keepalived服务即可。之后客户端的应用可以通过192.168.0.10这个IP地址来接通RabbitMQ服务。
Master启动之后可以通过ip add show命令查看添加的VIP(加粗部分,Backup节点是没有VIP的):
参考文章: https://blog.csdn.net/qq_34021712/article/details/72634167
https://blog.csdn.net/u013256816/article/details/77171017