废话不多说,进入正题!
本文重点在于:对富文本图片的导出(基础的freemarker+word模板导出这里不做详细解说哈)
参考文章:http://www.cnblogs.com/liaofeifight/p/5484891.html
(ps:大神的东西太深奥~~懵逼了
一周才搞定,为了方便后来在更加简单,清晰的学习,楼主写下这篇博客,感谢大神给了我个完善和进步的机会,也希望后来在继续完善)
先说一下思路:由于我们是要用word来解析带图片的富文本(说白了就是解析一段html,当然这段html代码是包含img标签:图片),so...传统的word模板导出(word另存为xml,在修改后缀为ftl)是行不通的,因为他解析不了html代码(至少我目前没有找到这方便的解决方案,大神勿喷~),这样的话我就要换用一种模板来处理这个模板:word模板另存为mht格式,再修改后缀为ftl。剩下的就是后台操作了,找到你存富文本的字段(html代码)获取里面的img标签,找到图片,并把图片解析为base64字符串,填充到我们只做的模板上就ok了,大体思路就这样了
一、模板制作(这个很重要)
提示:这里模板用office word来做,不要用wps
创建word文件: ,我这里用第二个content来显示我们要的富文本,然后将我们的word文件另存为mht文件,
,我这里用第二个content来显示我们要的富文本,然后将我们的word文件另存为mht文件,
最后我们就拿到我们要的mht模板了,这仅仅是个开始...各位看官往下看
打开我们的mht文件并处理:在我们的文件里面找到下面这些东西,如果没有找到呢?....这个问题,我就只有呵呵了
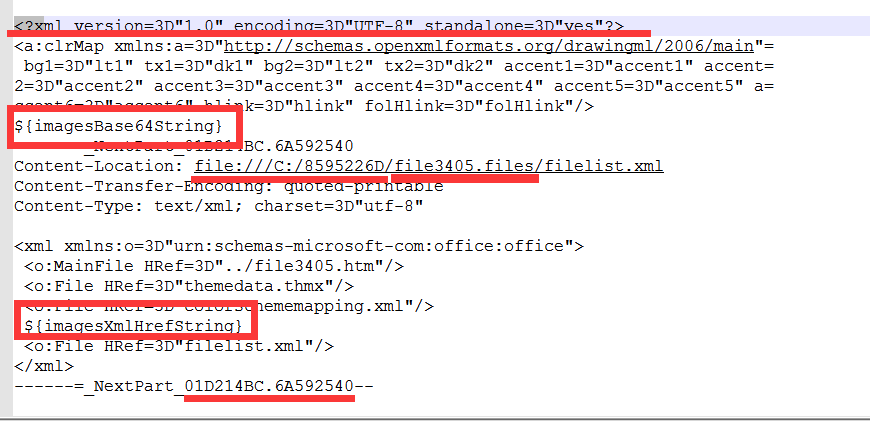
${imagesBase64String} 和 ${imagesXmlHrefString}这两个是我们手动加进去的,简析富文本图片的核心就在这里(反正我也是蒙的~)

全文检索gb2312把他改成utf-8,同时需要加上3D前缀,对应着格式来改 一般就这两种:
<meta http-equiv=3DContent-Type content=3D"text/html; charset=3Dutf-8">和Content-Type: text/html; charset=3D"utf-8"

提示:所有的都要改成utf-8(你不改也是可以的)
然后保存一下,再把文件的后缀名改成ftl格式的就ok了(模板处理到此结束)
二、解析html

这个大家不陌生吧?陌生的自己打脸去,下面的那三个我依然懵逼
handler.handledHtml(false);
String bodyBlock = handler.getHandledDocBodyBlock();
data.put("content", bodyBlock); 处理后的html代码块
data.put("imagesXmlHrefString", xmlimaHref);
data.put("imagesBase64String", handledBase64Block); 这两个大家还有印象吧?没错就是我们之前手动在mht模板里加的那两货!
三、填充模板
String docFilePath = "d:\temp.doc"; System.out.println(docFilePath); File f = new File(docFilePath); OutputStream out; try { out = new FileOutputStream(f); WordGeneratorWithFreemarker.createDoc(data, "temp.ftl", out); } catch (FileNotFoundException e) { } catch (MalformedTemplateNameException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }
四、导出word(带富文本图的哟)
public static void createDoc(Map<String, Object> dataMap,String templateName, OutputStream out)throws Exception { Template t = configuration.getTemplate(templateName); t.setEncoding("utf-8"); WordHtmlGeneratorHelper.handleAllObject(dataMap); try { Writer w = new OutputStreamWriter(out,Charset.forName("utf-8")); t.process(dataMap, w); w.close(); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex); } }
五、测试(main)
public static void main(String[] args) throws Exception { HashMap<String, Object> data = new HashMap<String, Object>(); StringBuilder sb = new StringBuilder(); sb.append("<div>"); sb.append("<img style='height:100px;200px;display:block;' src='F:\aaa.png' />"); sb.append("<img style='height:100px;200px;display:block;' src='F:\bbb.png' />"); sb.append("</br><span>中国梦,幸福梦!</span>"); sb.append("</div>"); RichHtmlHandler handler = new RichHtmlHandler(sb.toString()); handler.setDocSrcLocationPrex("file:///C:/8595226D"); handler.setDocSrcParent("file3405.files"); handler.setNextPartId("01D214BC.6A592540"); handler.setShapeidPrex("_x56fe__x7247__x0020"); handler.setSpidPrex("_x0000_i"); handler.setTypeid("#_x0000_t75"); handler.handledHtml(false); String bodyBlock = handler.getHandledDocBodyBlock(); System.out.println("bodyBlock: "+bodyBlock); String handledBase64Block = ""; if (handler.getDocBase64BlockResults() != null && handler.getDocBase64BlockResults().size() > 0) { for (String item : handler.getDocBase64BlockResults()) { handledBase64Block += item + " "; } } data.put("imagesBase64String", handledBase64Block); String xmlimaHref = ""; if (handler.getXmlImgRefs() != null && handler.getXmlImgRefs().size() > 0) { for (String item : handler.getXmlImgRefs()) { xmlimaHref += item + " "; } } data.put("imagesXmlHrefString", xmlimaHref); data.put("name", "张三"); data.put("content", bodyBlock); String docFilePath = "d:\temp.doc"; System.out.println(docFilePath); File f = new File(docFilePath); OutputStream out; try { out = new FileOutputStream(f); WordGeneratorWithFreemarker.createDoc(data, "temp.ftl", out); } catch (FileNotFoundException e) { } catch (MalformedTemplateNameException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
查看结果:

到此~导出word带富文本图片的功能就借宿了,详细代码我放在附件里面(这里着重讲mht模板的一些改动,处理富文本的java代码我就没有单独贴出来了哈,demo里面有哦)
有完整的demo,大家放心不会像我一样懵逼一周了 哈哈
开玩笑的~!话说我从开始到完整的做出来 还是花了5天左右的时间,
再次感谢参考的文章:http://www.cnblogs.com/liaofeifight/p/5484891.html
最后在再给大家扩展一下:一个word 出现多个富文本,并且每个富文本有多个图片的思路:
String old_handledBase64Block = ""; if(data.containsKey("imagesBase64String")){ old_handledBase64Block = (String) data.get("imagesBase64String"); handledBase64Block = old_handledBase64Block + handledBase64Block; } data.put("imagesBase64String", handledBase64Block);
简单说一下 ,其实就是在处理下一个富文本的时候 要拿到上一个富文本里面处理中的"imagesBase64String" 再把它累加起来,
不然后面的会给前面的覆盖掉~"imagesXmlHrefString"这个也是一样的

各位看官!搞懂这个是不是觉得单纯的图片导出太简单了哇 哈哈(话说我还没用过单纯的图片导出)