TCP与UDP区别
-
TCP提供的是面向连接的、可靠的数据流传输;
UDP提供的是非面向连接的、不可靠的数据流传输。
-
TCP提供可靠的服务,通过TCP连接传送的数据,无差错、不丢失,不重复,按序到达;UDP尽最大努力交付,即不保证可靠交付。
-
TCP面向字节流;
UDP面向报文。
-
TCP连接只能是点到点的;
UDP支持一对一、一对多、多对一和多对多的交互通信。
-
TCP首部开销20字节;
UDP的首部开销小,只有8个字节。
-
TCP的逻辑通信信道是全双工的可靠信道;
UDP的逻辑通信信道是不可靠信道。
TCP定义
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
UDP定义
UDP (User Datagram Protocol 用户数据报协议)是OSI(Open System Interconnection开放式系统互联) 参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。
--------------------------------------------------------------
TCP 的三次握手

假设 A 为客户端,B 为服务器端。
-
首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
-
A 向 B 发送连接请求报文段,SYN=1,ACK=0,选择一个初始的序号 x。
-
B 收到连接请求报文段,如果同意建立连接,则向 A 发送连接确认报文段,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
-
A 收到 B 的连接确认报文段后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
-
B 收到 A 的确认后,连接建立。
三次握手的原因
第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
失效的连接请求是指,客户端发送的连接请求在网络中滞留,客户端因为没及时收到服务器端发送的连接确认,因此就重新发送了连接请求。滞留的连接请求并不是丢失,之后还是会到达服务器。如果不进行第三次握手,那么服务器会误认为客户端重新请求连接,然后打开了连接。但是并不是客户端真正打开这个连接,因此客户端不会给服务器发送数据,这个连接就白白浪费了。
TCP 的四次挥手

以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
-
A 发送连接释放报文段,FIN=1。
-
B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
-
当 B 要不再需要连接时,发送连接释放请求报文段,FIN=1。
-
A 收到后发出确认,进入 TIME-WAIT 状态,等待 2MSL 时间后释放连接。
-
B 收到 A 的确认后释放连接。
四次挥手的原因
客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。
TIME_WAIT
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
-
确保最后一个确认报文段能够到达。如果 B 没收到 A 发送来的确认报文段,那么就会重新发送连接释放请求报文段,A 等待一段时间就是为了处理这种情况的发生。
-
等待一段时间是为了让本连接持续时间内所产生的所有报文段都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文段。
---------------------------------------------------------------------------
TCP 滑动窗口

窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 32, 34, 35},其中 {31, 32} 按序到达,而 {34, 35} 就不是,因此只对字节 32 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
TCP 可靠传输
TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:
其中 RTTd 为偏差。
TCP 流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
TCP 拥塞控制
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接受,而拥塞控制是为了降低整个网络的拥塞程度。

TCP 主要通过四种算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量。注意拥塞窗口与发送方窗口的区别,拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
为了便于讨论,做如下假设:
- 接收方有足够大的接收缓存,因此不会发生流量控制;
- 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。

1. 慢开始与拥塞避免
发送的最初执行慢开始,令 cwnd=1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 ...
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
如果出现了超时,则令 ssthresh = cwnd/2,然后重新执行慢开始。
2. 快重传与快恢复
在接收方,要求每次接收到报文段都应该发送对已收到有序报文段的确认,例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认。
在发送方,如果收到三个重复确认,那么可以确认下一个报文段丢失,例如收到三个 M2 ,则 M3 丢失。此时执行快重传,立即重传下一个报文段。
在这种情况下,只是丢失个别报文段,而不是网络拥塞,因此执行快恢复,令 ssthresh = cwnd/2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。

------------------------------------------------------------------------------------------------------
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
cookie 和session 的联系:
session是通过cookie来工作的
session和cookie之间是通过$_COOKIE['PHPSESSID']来联系的,通过$_COOKIE['PHPSESSID']可以知道session的id,从而获取到其他的信息。
-----------------------------------------------------------------------------------------------------------------------
hashMap为啥初始化容量为2的次幂
hashMap源码获取元素的位置:
static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
解释:
h:为插入元素的hashcode
length:为map的容量大小
&:与操作 比如 1101 & 1011=1001
如果length为2的次幂 则length-1 转化为二进制必定是11111……的形式,在于h的二进制与操作效率会非常的快,
而且空间不浪费;如果length不是2的次幂,比如length为15,则length-1为14,对应的二进制为1110,在于h与操作,
最后一位都为0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,
空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,
这意味着进一步增加了碰撞的几率,减慢了查询的效率!这样就会造成空间的浪费
---------------------------------------------------------------------
完全函数依赖
在一张表中,若 X → Y,且对于 X 的任何一个真子集(假如属性组 X 包含超过一个属性的话),X ' → Y 不成立,那么我们称 Y 对于 X 完全函数依赖,记作 X F→ Y。(那个F应该写在箭头的正上方,没办法打出来……,正确的写法如图1)
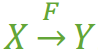
设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K(这个“完全”不要漏了),那么我们称 K 为候选码,简称为码。在实际中我们通常可以理解为:假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。(实际应用中为了方便,通常选择其中的一个码作为主码)


-------------------------------------------------------------------------
-
内连接:指连接结果仅包含符合连接条件的行,参与连接的两个表都应该符合连接条件。
-
外连接:连接结果不仅包含符合连接条件的行同时也包含自身不符合条件的行。包括左外连接、右外连接和全外连接。
----------------------------------------------------------------------------
==和equals()的区别
1)对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;
如果作用于引用类型的变量,则比较的是所指向的对象的地址
2)对于equals方法,注意:equals方法不能作用于基本数据类型的变量
如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
-----------------------------------------------------------
1 String、StringBuffer与StringBuilder区别
(1)区别
- String内容不可变,StringBuffer和StringBuilder内容可变;
- StringBuilder非线程安全(单线程使用),String与StringBuffer线程安全(多线程使用);
- 如果程序不是多线程的,那么使用StringBuilder效率高于StringBuffer。
(2)String 字符串常量;
/** Strings are constant; their values cannot be changed after they
* are created. String buffers support mutable strings.
* Because String objects are immutable they can be shared.
* 字符串是不变的,他们的值在创造后不能改变。
* 字符串缓冲区支持可变字符串,因为字符串对象是不可变的,所以它们可以共享。
*
* @see StringBuffer
* @see StringBuilder
* @see Charset
* @since 1.0
*/
public final class String implements Serializable, Comparable<String>, CharSequence {
private static final long serialVersionUID = -6849794470754667710L;
private static final char REPLACEMENT_CHAR = (char) 0xfffd;这句话总结归纳了String的两个最重要的特点:
- String是值不可变的常量,是线程安全的(can be shared)。
- String类使用了final修饰符,String类是不可继承的。
(3)StringBuffer字符串变量(线程安全)是一个容器,最终会通过toString方法变成字符串;
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, Appendable, CharSequence
{
/**
* Constructs a string buffer with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuffer() {
super(16);
}
public synchronized StringBuffer append(int i) {
super.append(i);
return this;
}
public synchronized StringBuffer delete(int start, int end) {
super.delete(start, end);
return this;
}
}(4)StringBuilder 字符串变量(非线程安全)。
public final class StringBuilder extends AbstractStringBuilder implements java.io.Serializable, Appendable, CharSequence {
public StringBuilder() {
super(16);
}
public StringBuilder append(String str) {
super.append(str);
return this;
}
public StringBuilder delete(int start, int end) {
super.delete(start, end);
return this;
}
}2 String与StringBuffer区别
2.1 在修改时对象自身是否可变(主要区别)
(1) String在修改时不会改变对象自身
在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String 。
String str = "abc";//地址str1
str = "def";//地址str2
(2) StringBuffer在修改时会改变对象自身
每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。StringBuffer 上的主要操作是 append 和 insert 方法。
StringBuffer strBuffer = new StringBuffer("abc");//地址strBuffer,值是abc
strBuffer.append("def");//地址strBuffer,值是abcdef
2.2 是否可变测试
2.2.1 测试代码
public class MyTest {
public static void main(String[] args) {
String str = "abc";
StringBuffer strBuffer = new StringBuffer();
strBuffer.append("def");
System.out.println(a.getClass() + "@" + str.hashCode());
System.out.println(b.getClass() + "@" + strBuffer.hashCode());
str = "aaa";
strBuffer.append("bbb");
System.out.println(a.getClass() + "@" + str.hashCode());
System.out.println(b.getClass() + "@" + strBuffer.hashCode());
}
}2.2.2 结果
小结:String的地址已改变,对象已经改变为另一个;StringBuffer地址不变,还是同样的对象。

2.3 初始化区别
(1)String
StringBuffer s = null;
StringBuffer s = “abc”; (2)StringBuffer
StringBuffer s = null; //结果警告:Null pointer access: The variable result can only be null at this locationStringBuffer s = new StringBuffer();//StringBuffer对象是一个空的对象
StringBuffer s = new StringBuffer(“abc”);//创建带有内容的StringBuffer对象,对象的内容就是字符串”abc”2.4 StringBuffer对象和String对象之间的互转
StringBuffer和String属于不同的类型,也不能直接进行强制类型转换。StringBuffer对象和String对象之间的互转的代码如下:
String s = “abc”;
StringBuffer sb1 = new StringBuffer(“123”);
StringBuffer sb2 = new StringBuffer(s); //String转换为StringBuffer
String s1 = sb1.toString(); //StringBuffer转换为String2.5 StringBuffer相对String偏重
StringBuffer类中的方法主要偏重于对于字符串的变化,例如追加、插入和删除等,常用方法有:append方法、insert方法、deleteCharAt方法、reverse方法等。
2.6 总结
(1)如果要操作少量的数据用 String;
(2)(多线程下)经常需要对一个字符串进行修改,例如追加、插入和删除等操作,使用StringBuffer要更加适合一些。
3 StringBuffer与StringBuilder区别
3.1 StringBuilder是可变的对象,是5.0新增的
此类提供一个与StringBuffer兼容的 API,但不保证同步。该类被设计用作StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。
3.2 线程安全性
(1) StringBuffer:线程安全的;
(2) StringBuilder:线程非安全的。
4 String,StringBuffer与StringBuilder速度区别
4.1 在大部分情况下,StringBuffer > String
由于String对象不可变,重复新建对象;StringBuffer对象可变。
4.2 StringBuilder > StringBuffer
当我们在字符串缓冲去被多个线程使用是,JVM不能保证StringBuilder的操作是安全的,虽然他的速度最快,但是可以保证StringBuffer是可以正确操作的。当然大多数情况下就是我们是在单线程下进行的操作,所以大多数情况下是建议用StringBuilder而不用StringBuffer的。
4.3 特殊情况, String > StringBuffer
//String效率是远要比StringBuffer快的:
String S1 = “This is only a” + “ simple” + “ test”;
StringBuffer Sb = new StringBuilder(“This is only a”).append(“simple”).append(“ test”);//String速度是非常慢的:
String S2 = “This is only a”;
String S3 = “ simple”;
String S4 = “ test”;
String S1 = S2 +S3 + S4;5 总结
(1)如果要操作少量的数据用 String;
(2)多线程操作字符串缓冲区下操作大量数据 StringBuffer;
(3)单线程操作字符串缓冲区下操作大量数据 StringBuilder。
-----------------------------------
详解重写equals()方法就必须重写hashCode()方法的原因
从Object类的hashCode()和equals()方法讲起:
最近看了Object类的源码,对hashCode() 和equals()方法有了更深的认识。重写equals()方法就必须重写hashCode()方法的原因,从源头Object类讲起就更好理解了。
先来看Object关于hashCode()和equals()的源码:
- public native int hashCode();
- public boolean equals(Object obj) {
- return (this == obj);
- }
光从代码中我们可以知道,hashCode()方法是一个本地native方法,返回的是对象引用中存储的对象的内存地址,而equals方法是利用==来比较的也是对象的内存地址。从上边我们可以看出,hashCode方法和equals方法是一致的。还有最关键的一点,我们来看Object类中关于hashCode()方法的注释:
简单的翻译一下就是,hashCode方法一般的规定是:
- 1.在 Java 应用程序执行期间,在对同一对象多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是将对象进行 equals 比较时所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
- 2.如果根据 equals(Object) 方法,两个对象是相等的,那么对这两个对象中的每个对象调用 hashCode 方法都必须生成相同的整数结果。
- 3.如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法不 要求一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
再简单的翻译一下第二三点就是:hashCode()和equals()保持一致,如果equals方法返回true,那么两个对象的hasCode()返回值必须一样。如果equals方法返回false,hashcode可以不一样,但是这样不利于哈希表的性能,一般我们也不要这样做。重写equals()方法就必须重写hashCode()方法的原因也就显而易见了。
假设两个对象,重写了其equals方法,其相等条件是属性相等,就返回true。如果不重写hashcode方法,其返回的依然是两个对象的内存地址值,必然不相等。这就出现了equals方法相等,但是hashcode不相等的情况。这不符合hashcode的规则。下边,会介绍在集合框架中,这种情况会导致的严重问题。
Object类到底有哪些方法
1.clone方法
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
2.getClass方法
final方法,获得运行时类型。
3.toString方法
该方法用得比较多,一般子类都有覆盖。
4.finalize方法
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
5.equals方法
该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。
6.hashCode方法
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
一般必须满足obj1.equals(obj2)==true。可以推出obj1.hash-Code()==obj2.hashCode(),但是hashCode相等不一定就满足equals。不过为了提高效率,应该尽量使上面两个条件接近等价。
7.wait方法
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(longtimeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
(1)其他线程调用了该对象的notify方法。
(2)其他线程调用了该对象的notifyAll方法。
(3)其他线程调用了interrupt中断该线程。
(4)时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
8.notify方法
该方法唤醒在该对象上等待的某个线程。
9.notifyAll方法
该方法唤醒在该对象上等待的所有线程。
---------------------------------------------------------------
Java中创建线程主要有三种方式:
一、继承Thread类创建线程类
(1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
(2)创建Thread子类的实例,即创建了线程对象。
(3)调用线程对象的start()方法来启动该线程。
- package com.thread;
- public class FirstThreadTest extends Thread{
- int i = 0;
- //重写run方法,run方法的方法体就是现场执行体
- public void run()
- {
- for(;i<100;i++){
- System.out.println(getName()+" "+i);
- }
- }
- public static void main(String[] args)
- {
- for(int i = 0;i< 100;i++)
- {
- System.out.println(Thread.currentThread().getName()+" : "+i);
- if(i==20)
- {
- new FirstThreadTest().start();
- new FirstThreadTest().start();
- }
- }
- }
- }
上述代码中Thread.currentThread()方法返回当前正在执行的线程对象。GetName()方法返回调用该方法的线程的名字。
二、通过Runnable接口创建线程类
(1)定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
(2)创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
(3)调用线程对象的start()方法来启动该线程。
示例代码为:
- package com.thread;
- public class RunnableThreadTest implements Runnable
- {
- private int i;
- public void run()
- {
- for(i = 0;i <100;i++)
- {
- System.out.println(Thread.currentThread().getName()+" "+i);
- }
- }
- public static void main(String[] args)
- {
- for(int i = 0;i < 100;i++)
- {
- System.out.println(Thread.currentThread().getName()+" "+i);
- if(i==20)
- {
- RunnableThreadTest rtt = new RunnableThreadTest();
- new Thread(rtt,"新线程1").start();
- new Thread(rtt,"新线程2").start();
- }
- }
- }
- }
三、通过Callable和Future创建线程
(1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
(3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
实例代码:
- package com.thread;
- import java.util.concurrent.Callable;
- import java.util.concurrent.ExecutionException;
- import java.util.concurrent.FutureTask;
- public class CallableThreadTest implements Callable<Integer>
- {
- public static void main(String[] args)
- {
- CallableThreadTest ctt = new CallableThreadTest();
- FutureTask<Integer> ft = new FutureTask<>(ctt);
- for(int i = 0;i < 100;i++)
- {
- System.out.println(Thread.currentThread().getName()+" 的循环变量i的值"+i);
- if(i==20)
- {
- new Thread(ft,"有返回值的线程").start();
- }
- }
- try
- {
- System.out.println("子线程的返回值:"+ft.get());
- } catch (InterruptedException e)
- {
- e.printStackTrace();
- } catch (ExecutionException e)
- {
- e.printStackTrace();
- }
- }
- @Override
- public Integer call() throws Exception
- {
- int i = 0;
- for(;i<100;i++)
- {
- System.out.println(Thread.currentThread().getName()+" "+i);
- }
- return i;
- }
- }
二、创建线程的三种方式的对比
采用实现Runnable、Callable接口的方式创见多线程时,优势是:
线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
劣势是:
编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
使用继承Thread类的方式创建多线程时优势是:
编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。
劣势是:
线程类已经继承了Thread类,所以不能再继承其他父类。