写在前面
我在学习Java NIO时,看到网上很多资料是从Reactor模式入手,当我继续深挖下去,意识到NIO的本质或许不只Reactor模式那么简单,那又是什么呢?
于是我决定从Linux的系统调用着手,想了解一下Linux系统怎么做到的并发I/O。
所以这篇文章,更多得是对最近学习Linux I/O知识的梳理和总结。
本文主要是想解答一下这样几个问题:
- 什么是非阻塞I/O
- 非阻塞I/O和异步I/O的区别
- epoll的工作原理
文件描述符
文件描述符是一个非负整数,用于标识一个打开的文件。
这里“文件”一词是更宽泛的概念,可以是进程中使用的任何类型的IO资源,例如常规文件,管道,Socket等。
通常,打开IO流的系统调用都会返回一个int类型的文件描述符。
例如下面分别是打开一个文件和创建一个Socket的系统调用。
int open(const char *pathname, int flags);
int socket(int domain, int type, int protocol);
(文件描述符File descriptor,在程序中一般简写为fd。)
阻塞模式(Blocking I/O)
默认的,Unix系统的所有文件描述符都是阻塞模式。这意味着有关I/O的操作(如read,write,open)都是阻塞的。
以从Linux终端窗口读取数据为例,如果你在程序中调用了read(),程序会一直阻塞,直到你确实敲键盘输入了字符。
这里的程序阻塞,更准确地讲,是系统内核把该进程设置成了睡眠状态,直到有数据输入才被唤醒。
TCP Socket通信也是一样的道理,如果你尝试着从socket中读取数据,read()会被阻塞,直到socket的另一端发送了数据。
可见,在阻塞模式下程序是不能并发操作的。
对于并发I/O,我们将讨论三个解决办法:
- 非阻塞模式
- I/O多路复用系统调用,select和epoll
- 多线程/多进程
非阻塞模式(Nonblocking I/O)
在打开一个文件时,设置flag参数为O_NONBLOCK,此标志位告诉操作系统对这个文件的操作应该是非阻塞的,或者说该文件描述符处于非阻塞模式。
int open(const char *pathname, int flags, mode_t mode);
这意味着两点:
- 如果这个文件不能立即打开,open()系统调用会返回一个错误码,而不是阻塞open()。
- 文件打开成功后,后续的I/O操作应该也是非阻塞的,例如如果不能立即完成read或write,返回错误码。
不能立即完成读写的原因可能是没有数据可读,或者缓存已满没有更多空间可以写。
(注意,非阻塞模式对常规文件无效,因为系统内核总能保证有足够的缓存让常规文件I/O不阻塞)
非阻塞模式仅仅是Unix系统中一个原始特性,只有它还不能让程序并发执行。还需要在应用程序中写一个死循环,不停的检测文件描述符的状态。
下面以并发访问两个文件描述符为例写一段伪代码。
先解释一下read()系统调用的几个参数:
int read(int fd, void *buffer, size_t count);
fd即读取的文件描述符buffer用于接收本次读取的数据count本次读取的最大字节数返回值实际读取的字节数,发生错误返回-1
ssize_t nbytes;
for (;;) {
//文件描述符1
if ((nbytes = read(fd1, buf, sizeof(buf))) < 0) {
if (errno != EWOULDBLOCK) {
//发生错误,且错误码为EWOULDBLOCK
//说明文件描述符fd1没有准备好read
}
} else {
handle_data(buf); //处理数据
}
//文件描述符2
if ((nbytes = read(fd2, buf, sizeof(buf))) < 0) {
if (errno != EWOULDBLOCK) {
//fd2不能read
}
} else {
handle_data(buf);
}
nanosleep(sleep_interval, NULL); //再次检测前睡眠片刻
}
以上实现了对两个文件并发IO,但有很明显的缺点:
- 循环的频次太低,会导致I/O的响应延迟。
- 循环的频次太高,当需要并发处理的文件很多时,每次循环都要检测所有文件,性能会变得很差(read()是系统调用)。
多进程/线程方式
并发处理多个I/O流还有一种更原始的方法,使用多进程或多线程,每个I/O流独占一个进程或线程,很容易理解。
也有很多缺点:
- 在任何时刻,都可能有大量的线程处于空闲状态,造成资源浪费。
- 线程是占内存的,不可能创建太多的工作线程。
- 线程/进程的上下文切换也会带来很大的性能开销。
在互联网早期流量比较小,很多服务采用的这种方式,但是它只适用于低并发的服务器。
上面讨论了非阻塞模式和多进程两个方式,在高并发场景都不太好用。
这时,我们就需要Unix的I/O多路复用了。
I/O多路复用(I/O Multiplexing)
类Unix系统有多个实现了I/O多路复用的系统调用,Unix系统的select和poll,Linux的epoll,以及BSD的kqueue。
他们的底层工作原理相似:首先告诉系统内核你想监控哪些文件描述符的哪些事件(典型的read和write事件),然后用户程序被阻塞,直到你感兴趣的事件发生(事件驱动模型)。
Unix的I/O多路复用机制不关心文件描述符是否处于非阻塞模式,你可以把所有文件描述符设置为阻塞模式,epoll和select不会受影响。
这一点很重要!非阻塞模式和I/O多路复用,这两个方法都可以实现并发I/O,但是本质上他们是相互独立的两个解决问题思路,互不依赖。
多路复用实现的并发I/O,有时被称为异步I/O(asynchronous I/O)。但是有人也把这种方式称为非阻塞I/O,通过见面的内容,我们知道这种称呼是错误的。
epoll的工作原理
epoll是event poll的简写,是Linux内核提供的一种由事件驱动的I/O通知机制。(注意epoll是Linux特有的,其他类Unix系统可能没有实现。)
另外,epoll本身并不是一个系统调用,而是一组系统调用的统称。
这组系统调用包括:
- epoll_create()系统调用
- epoll_ctl()系统调用
- epoll_wait()系统调用
epoll_create()
方法签名:int epoll_create(int size)
该系统调用用于创建一个epoll实例,该实例存在于系统内核空间。
epoll实例会初始化一个列表,用于存储用户程序感兴趣的文件描述符,下文简称interest list,参数size即为这个列表的初始大小(可以动态扩展)。返回值是epoll实例的文件描述符。
epoll_ctl()
使用epoll_ctl()可以对interest list增删改(ctl应该是control的缩写)
方法签名:int epoll_ctl(int epfd, int op, int fd, struct epoll_event *ev)
参数说明:
epfd: 即epoll_create()创建的epoll实例的文件描述符op: 枚举值,指定操作类型,例如EPOLL_CTL_ADD添加一个文件描述符ev: 结构体类型,是对该文件描述符的设置。
ev参数最重要的是ev.events字段可以添加感兴趣的事件,例如添加了read事件,表示该文件可以read的时候,通知应用程序。
epoll_wait()
用户程序调用该方法获取ready的文件描述符。
继续之前先解释一下文件描述符什么时候ready?
即使在文件描述符处于阻塞模式(没有设置O_NONBLOCK)的情况下,对该文件描述符的readwrite等操作扔不会阻塞,就说该文件描述符ready。
方法签名:int epoll_wait(int epfd, struct epoll_event *evlist, int maxevents, int timeout);
参数说明:
- epfd: epoll实例的文件描述符
- evlist: 用于接收ready的文件描述符,该数组由用户程序分配。
- maxevents: 一次调用返回的最大事件数量
- timeout: epoll_wait系统调用的超时时间,0表示不阻塞,无事件发生立即返回。-1一直阻塞,直到有事件发生。大于0表示超时返回。
为了对epoll的并发I/O编程有个感性的认识,我们来写一段伪代码
epfd = epoll_create(EPOLL_QUEUE_LEN); //创建epoll实例
static struct epoll_event ev;
int client_sock;
ev.events = EPOLLIN | EPOLLPRI | EPOLLERR | EPOLLHUP; //声明感兴趣的事件
ev.data.fd = client_sock; //文件描述符指向一个Socket连接
//添加要监控的文件描述符和事件类型到interest list
//真实环境中,可能需要添加成百上千个这种事件。
int res = epoll_ctl(epfd, EPOLL_CTL_ADD, client_sock, &ev);
while (1) {
int nfds = epoll_wait(epfd, events, MAX_EVENTS_PER_RUN, TIMEOUT);//获取ready的事件,可能有多个
if (nfds < 0) die("Error in epoll_wait!"); //发生错误,退出程序
for(int i = 0; i < nfds; i++) { //遍历处理每一个已ready的socket
int fd = events[i].data.fd;
handle_io_on_socket(fd);
}
}
从伪代码中可以看到,基于epoll的I/O多路复用的时间复杂度只有O(n),其中n是ready的事件数量。
时间复杂度不会随着interest list的增加而线性增长,这使得epoll有很好的扩展性。
试想一个高并发服务器同一时刻可能需要监控成千上万甚至更多的socket连接,
如果使用文章开始介绍的非阻塞模式,每一次循环都要对全部的socket连接进行测试,吞吐量可想而知。
但是epoll的压力只与socket通信的繁忙程度有关。
另外提一下,Unix中的poll()和select()有着更差的时间复杂度和空间复杂度,篇幅受限这里不展开说了。
最后,结合图片了解一下epoll的内部结构(图片出处见文章最后)
1.进程483通过epoll_create()创建一个epoll实例,该实例存在于内核空间。
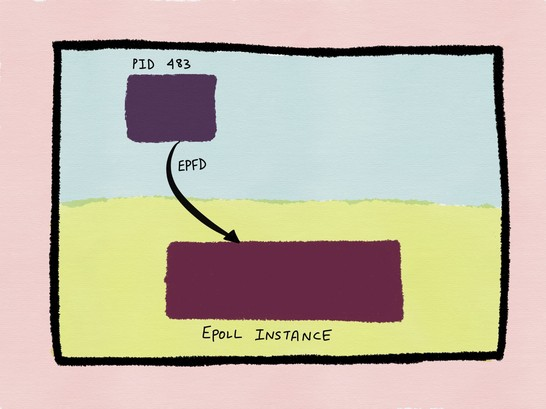
2.进程483通过epoll_ctl()系统调用,添加五个感兴趣的文件描述符到interest list。
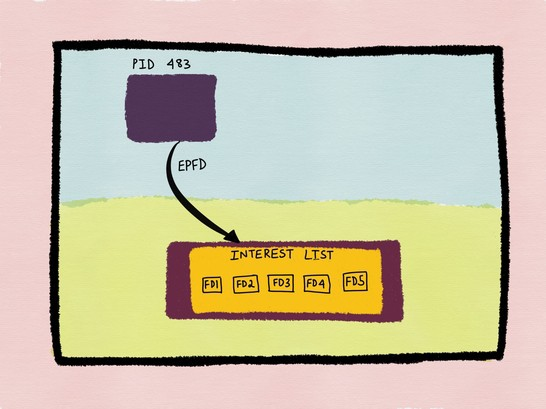
3.当有文件描述符ready时,系统内核会把该文件描述符添加到ready list,ready list是interest list的子集。
事件发生后添加到ready list,这个过程是内核完成的。

4. 用户程序调用epoll_wait()时,内核会把ready list返回给用户程序。
写在最后
博主的主力语言是Java,对C一知半解,如文章有理解错误的地方,感谢指正。
学习途中翻阅了很多资料,其中对我帮助最大的是《The Linux Programming Interface》,作者是Linux man-pages的维护者,具有一定的权威性。
这本书并没有像书名一样停留在Linux API层面,而是穿插着讲解了很多原理性的知识,有几个知识点讲的可谓醍醐灌顶。
无论你用的什么语言,这本书都非常值得一读。
其他资料就比较杂乱了,像维基百科、man手册、个人博客都有,链接都放在下面了。
希望本文对你有所帮助。
参考内容
- 《The Linux Programming Interface》英文版 4.3章节、5.9章节、 56.2章节、63.1章节、63.2.3章节 (核心参考)
- man7关于O_NONBLOCK的权威说明:http://man7.org/linux/man-pages/man2/open.2.html (
里面有提到,设置O_NONBLOCK与否对select和epoll没有影响。)- 很清晰的解释了非阻塞模式和多路复用的区别和联系:https://eklitzke.org/blocking-io-nonblocking-io-and-epoll
- 介绍了epoll的工作原理和内部数据结构(本文中的图片来源):https://medium.com/@copyconstruct/the-method-to-epolls-madness-d9d2d6378642
- 对《The Linux Programming Interface》,epoll章节的读书笔记:https://jvns.ca/blog/2017/06/03/async-io-on-linux--select--poll--and-epoll/
- 一个epoll编程的小demo : https://kovyrin.net/2006/04/13/epoll-asynchronous-network-programming/
- 关于epoll和poll性能的讨论: https://www.win.tue.nl/~aeb/linux/lk/lk-12.html