1.总体框架
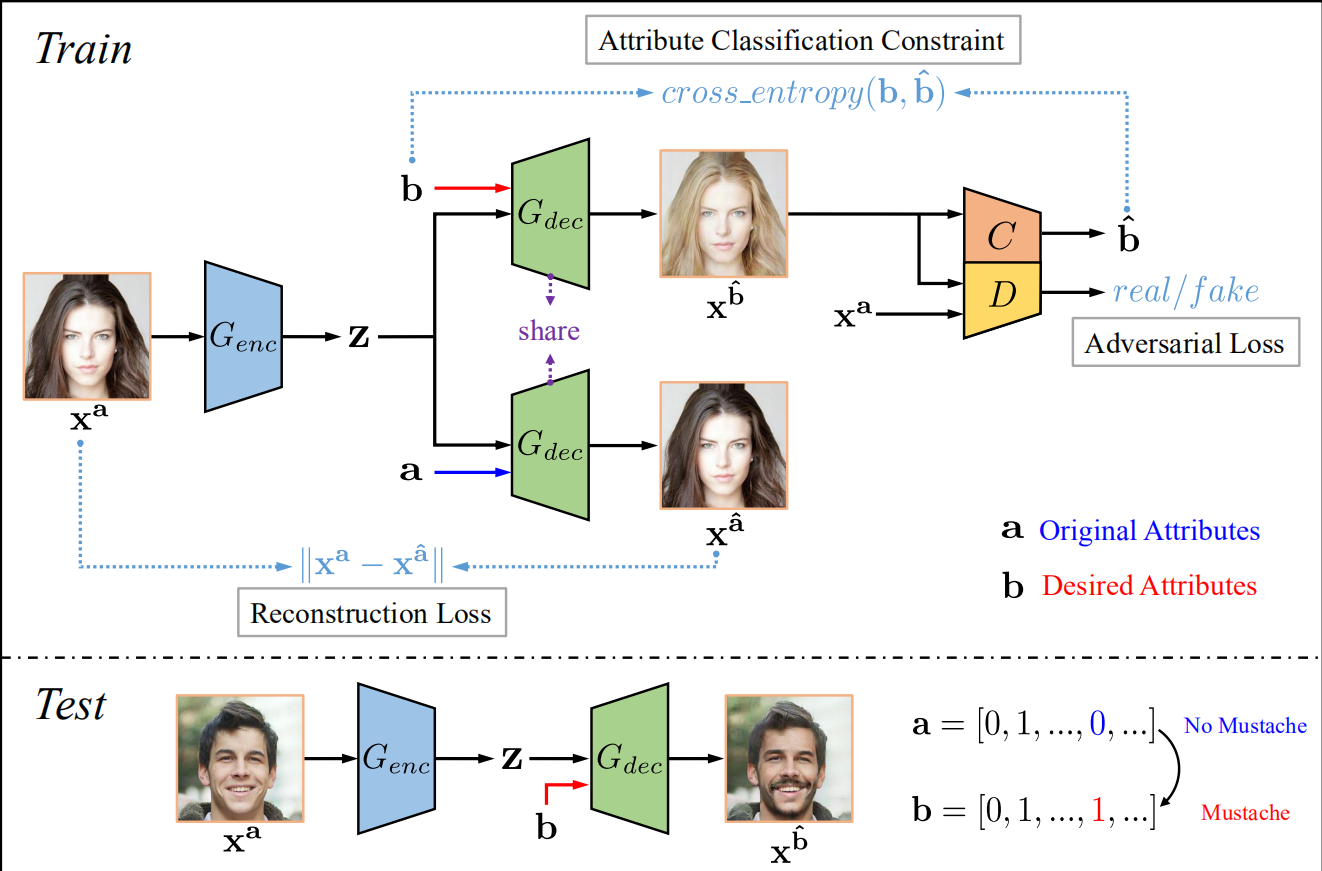
上面的过程用详细描述即是
Test阶段:


Train阶段:
由于我们无法得知编辑后的image,所以显而易见人脸属性编辑是一个无监督问题,而对于我们的xa需要获得关于b的属性,故利用attribute classififier来约束生成的xb使其获得了b属性;同时adversarial learning可以用来保证生成图片的真实性;此外,我们在进行人脸属性编辑的时候还需要保证只更改了我们需要编辑的属性,所以引入了reconstruction learning。
Reconstruction Loss

关于重建过程,即
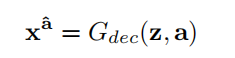
这里希望生成的xa^能尽量等于之前未编码的xa,就是一个encoder-decoder结构。
表示为
![]()
Attribute Classifification Constraint
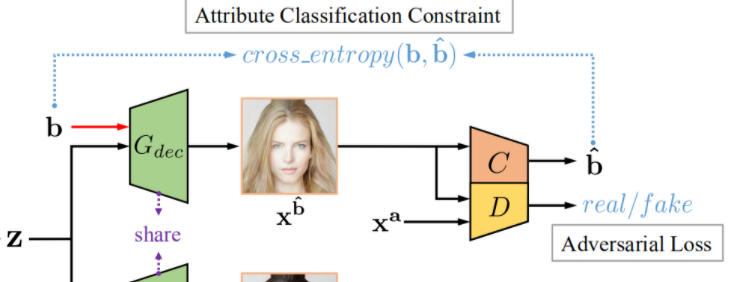
为了使生成的xb^确实拥有b属性,我们设置判别器C来鉴别,

(7)式代表最小化所有属性上的二进制交叉熵总和,(8)式为该交叉熵具体表达式。该属性分类器在原始图像上训练其属性:
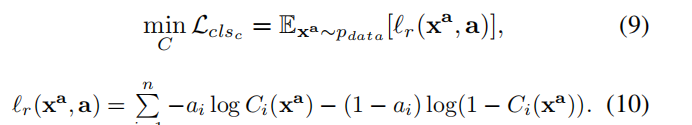
这两个式子的解释和(7)(8)类似。
Adversarial Loss
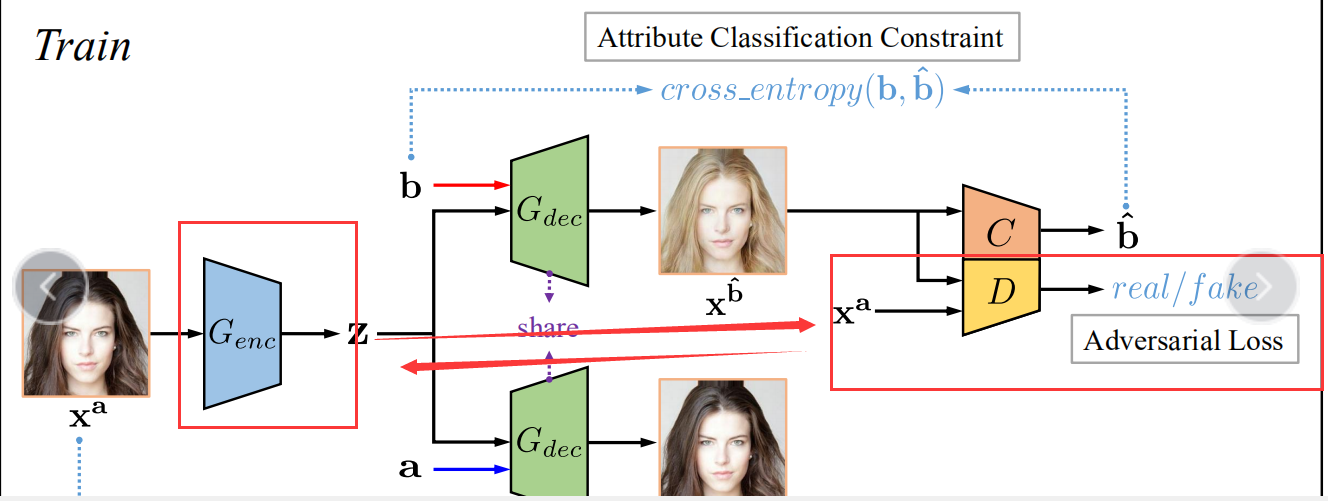
引入鉴别器和生成器之间的对抗过程使得生成的图片尽量真实,下面的表示借鉴了WGAN
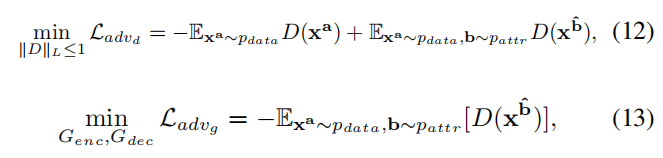
总体目标
结合上面的三种损失,解编码器要优化的目标如下
![]()
判别器和属性分类器要优化的目标如下:
![]()
属性样式操纵的扩展
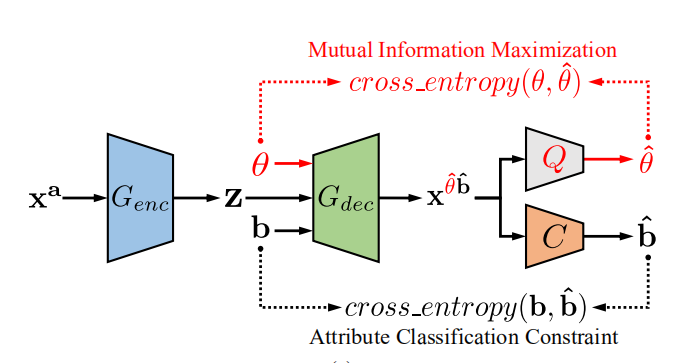
我们生活中可能更关心某人“戴的是什么颜色的眼镜”而非“有没有戴眼镜”。因此这里增添了一个参数theta,用来控制我们编辑的属性。
这时候我们属性编辑的方程就表示为:
![]()
我们要优化下面的互信息使其最大化
![]()
2.网络代码(带注释)
import torch import torch.nn as nn from nn import LinearBlock, Conv2dBlock, ConvTranspose2dBlock from torchsummary import summary # This architecture is for images of 128x128 # In the original AttGAN, slim.conv2d uses padding 'same' MAX_DIM = 64 * 16 # 1024 class Generator(nn.Module): def __init__(self, enc_dim=64, enc_layers=5, enc_norm_fn='batchnorm', enc_acti_fn='lrelu', dec_dim=64, dec_layers=5, dec_norm_fn='batchnorm', dec_acti_fn='relu', n_attrs=13, shortcut_layers=1, inject_layers=0, img_size=128): super(Generator, self).__init__() self.shortcut_layers = min(shortcut_layers, dec_layers - 1) self.inject_layers = min(inject_layers, dec_layers - 1) self.f_size = img_size // 2**enc_layers # f_size = 4 for 128x128 layers = [] n_in = 3 for i in range(enc_layers): n_out = min(enc_dim * 2**i, MAX_DIM) layers += [Conv2dBlock( n_in, n_out, (4, 4), stride=2, padding=1, norm_fn=enc_norm_fn, acti_fn=enc_acti_fn )] #batchnorm lrelu # Conv2d - 1[4, 64, 64, 64] # BatchNorm2d - 2[4, 64, 64, 64] # LeakyReLU - 3[4, 64, 64, 64] #一共重复了五次,卷积层 n_in = n_out self.enc_layers = nn.ModuleList(layers) layers = [] n_in = n_in + n_attrs # 1024 + 13 for i in range(dec_layers): if i < dec_layers - 1: n_out = min(dec_dim * 2**(dec_layers-i-1), MAX_DIM) layers += [ConvTranspose2dBlock( n_in, n_out, (4, 4), stride=2, padding=1, norm_fn=dec_norm_fn, acti_fn=dec_acti_fn )] # ConvTranspose2d-21 [4, 1024, 8, 8] 16,990,208 # BatchNorm2d-22 [4, 1024, 8, 8] 2,048 # ReLU-23 [4, 1024, 8, 8] # ConvTranspose2dBlock-24 [4, 1024, 8, 8] #四层反卷积层 n_in = n_out n_in = n_in + n_in//2 if self.shortcut_layers > i else n_in n_in = n_in + n_attrs if self.inject_layers > i else n_in else: layers += [ConvTranspose2dBlock( n_in, 3, (4, 4), stride=2, padding=1, norm_fn='none', acti_fn='tanh' )] #最后一层反卷积层 # ConvTranspose2dBlock-36 [4, 128, 64, 64] 0 # ConvTranspose2d-37 [4, 3, 128, 128] 6,147 # Tanh-38 [4, 3, 128, 128] 0 # ConvTranspose2dBlock-39 self.dec_layers = nn.ModuleList(layers) def encode(self, x): z = x zs = [] for layer in self.enc_layers: z = layer(z) zs.append(z) return zs def decode(self, zs, a): a_tile = a.view(a.size(0), -1, 1, 1).repeat(1, 1, self.f_size, self.f_size) z = torch.cat([zs[-1], a_tile], dim=1) for i, layer in enumerate(self.dec_layers): z = layer(z) if self.shortcut_layers > i: # Concat 1024 with 512 z = torch.cat([z, zs[len(self.dec_layers) - 2 - i]], dim=1) if self.inject_layers > i: a_tile = a.view(a.size(0), -1, 1, 1) .repeat(1, 1, self.f_size * 2**(i+1), self.f_size * 2**(i+1)) z = torch.cat([z, a_tile], dim=1) return z def forward(self, x, a=None, mode='enc-dec'): if mode == 'enc-dec': assert a is not None, 'No given attribute.' return self.decode(self.encode(x), a) if mode == 'enc': return self.encode(x) if mode == 'dec': assert a is not None, 'No given attribute.' return self.decode(x, a) raise Exception('Unrecognized mode: ' + mode) class Discriminators(nn.Module): # No instancenorm in fcs in source code, which is different from paper. def __init__(self, dim=64, norm_fn='instancenorm', acti_fn='lrelu', fc_dim=1024, fc_norm_fn='none', fc_acti_fn='lrelu', n_layers=5, img_size=128): super(Discriminators, self).__init__() self.f_size = img_size // 2**n_layers layers = [] n_in = 3 for i in range(n_layers): n_out = min(dim * 2**i, MAX_DIM) layers += [Conv2dBlock( n_in, n_out, (4, 4), stride=2, padding=1, norm_fn=norm_fn, acti_fn=acti_fn )] # Conv2d - 1[4, 64, 64, 64] # InstanceNorm2d - 2[4, 64, 64, 64] # LeakyReLU - 3[4, 64, 64, 64] # Conv2dBlock - 4[4, 64, 64, 64] #五层卷积 n_in = n_out self.conv = nn.Sequential(*layers) self.fc_adv = nn.Sequential( LinearBlock(1024 * self.f_size * self.f_size, fc_dim, fc_norm_fn, fc_acti_fn), # Linear-21 [4, 1024] # ReLU-22 [4, 1024] #全连接+RELU LinearBlock(fc_dim, 1, 'none', 'none') # Linear-24 [4, 1] #单个全连接 ) #上面是对抗损失 self.fc_cls = nn.Sequential( LinearBlock(1024 * self.f_size * self.f_size, fc_dim, fc_norm_fn, fc_acti_fn), LinearBlock(fc_dim, 13, 'none', 'none') ) #属性分类 #和上面对抗网络的形式一样 def forward(self, x): h = self.conv(x) h = h.view(h.size(0), -1) return self.fc_adv(h), self.fc_cls(h) import torch.autograd as autograd import torch.nn.functional as F import torch.optim as optim # multilabel_soft_margin_loss = sigmoid + binary_cross_entropy class AttGAN(): def __init__(self, args): self.mode = args.mode self.gpu = args.gpu self.multi_gpu = args.multi_gpu if 'multi_gpu' in args else False self.lambda_1 = args.lambda_1 self.lambda_2 = args.lambda_2 self.lambda_3 = args.lambda_3 self.lambda_gp = args.lambda_gp self.G = Generator( args.enc_dim, args.enc_layers, args.enc_norm, args.enc_acti, args.dec_dim, args.dec_layers, args.dec_norm, args.dec_acti, args.n_attrs, args.shortcut_layers, args.inject_layers, args.img_size ) self.G.train() if self.gpu: self.G.cuda() summary(self.G, [(3, args.img_size, args.img_size), (args.n_attrs, 1, 1)], batch_size=4, device='cuda' if args.gpu else 'cpu') self.D = Discriminators( args.dis_dim, args.dis_norm, args.dis_acti, args.dis_fc_dim, args.dis_fc_norm, args.dis_fc_acti, args.dis_layers, args.img_size ) self.D.train() if self.gpu: self.D.cuda() summary(self.D, [(3, args.img_size, args.img_size)], batch_size=4, device='cuda' if args.gpu else 'cpu') if self.multi_gpu: self.G = nn.DataParallel(self.G) self.D = nn.DataParallel(self.D) self.optim_G = optim.Adam(self.G.parameters(), lr=args.lr, betas=args.betas) self.optim_D = optim.Adam(self.D.parameters(), lr=args.lr, betas=args.betas) def set_lr(self, lr): for g in self.optim_G.param_groups: g['lr'] = lr for g in self.optim_D.param_groups: g['lr'] = lr def trainG(self, img_a, att_a, att_a_, att_b, att_b_): for p in self.D.parameters(): p.requires_grad = False zs_a = self.G(img_a, mode='enc') img_fake = self.G(zs_a, att_b_, mode='dec') img_recon = self.G(zs_a, att_a_, mode='dec') d_fake, dc_fake = self.D(img_fake) if self.mode == 'wgan': gf_loss = -d_fake.mean() if self.mode == 'lsgan': # mean_squared_error gf_loss = F.mse_loss(d_fake, torch.ones_like(d_fake)) if self.mode == 'dcgan': # sigmoid_cross_entropy gf_loss = F.binary_cross_entropy_with_logits(d_fake, torch.ones_like(d_fake)) gc_loss = F.binary_cross_entropy_with_logits(dc_fake, att_b) gr_loss = F.l1_loss(img_recon, img_a) g_loss = gf_loss + self.lambda_2 * gc_loss + self.lambda_1 * gr_loss self.optim_G.zero_grad() g_loss.backward() self.optim_G.step() errG = { 'g_loss': g_loss.item(), 'gf_loss': gf_loss.item(), 'gc_loss': gc_loss.item(), 'gr_loss': gr_loss.item() } return errG def trainD(self, img_a, att_a, att_a_, att_b, att_b_): for p in self.D.parameters(): p.requires_grad = True img_fake = self.G(img_a, att_b_).detach() d_real, dc_real = self.D(img_a) d_fake, dc_fake = self.D(img_fake) def gradient_penalty(f, real, fake=None): def interpolate(a, b=None): if b is None: # interpolation in DRAGAN beta = torch.rand_like(a) b = a + 0.5 * a.var().sqrt() * beta alpha = torch.rand(a.size(0), 1, 1, 1) alpha = alpha.cuda() if self.gpu else alpha inter = a + alpha * (b - a) return inter x = interpolate(real, fake).requires_grad_(True) pred = f(x) if isinstance(pred, tuple): pred = pred[0] grad = autograd.grad( outputs=pred, inputs=x, grad_outputs=torch.ones_like(pred), create_graph=True, retain_graph=True, only_inputs=True )[0] grad = grad.view(grad.size(0), -1) norm = grad.norm(2, dim=1) gp = ((norm - 1.0) ** 2).mean() return gp if self.mode == 'wgan': wd = d_real.mean() - d_fake.mean() df_loss = -wd df_gp = gradient_penalty(self.D, img_a, img_fake) if self.mode == 'lsgan': # mean_squared_error df_loss = F.mse_loss(d_real, torch.ones_like(d_fake)) + F.mse_loss(d_fake, torch.zeros_like(d_fake)) df_gp = gradient_penalty(self.D, img_a) if self.mode == 'dcgan': # sigmoid_cross_entropy df_loss = F.binary_cross_entropy_with_logits(d_real, torch.ones_like(d_real)) + F.binary_cross_entropy_with_logits(d_fake, torch.zeros_like(d_fake)) df_gp = gradient_penalty(self.D, img_a) dc_loss = F.binary_cross_entropy_with_logits(dc_real, att_a) d_loss = df_loss + self.lambda_gp * df_gp + self.lambda_3 * dc_loss self.optim_D.zero_grad() d_loss.backward() self.optim_D.step() errD = { 'd_loss': d_loss.item(), 'df_loss': df_loss.item(), 'df_gp': df_gp.item(), 'dc_loss': dc_loss.item() } return errD def train(self): self.G.train() self.D.train() def eval(self): self.G.eval() self.D.eval() def save(self, path): states = { 'G': self.G.state_dict(), 'D': self.D.state_dict(), 'optim_G': self.optim_G.state_dict(), 'optim_D': self.optim_D.state_dict() } torch.save(states, path) def load(self, path): states = torch.load(path, map_location=lambda storage, loc: storage) if 'G' in states: self.G.load_state_dict(states['G']) if 'D' in states: self.D.load_state_dict(states['D']) if 'optim_G' in states: self.optim_G.load_state_dict(states['optim_G']) if 'optim_D' in states: self.optim_D.load_state_dict(states['optim_D']) def saveG(self, path): states = { 'G': self.G.state_dict() } torch.save(states, path)