【咬尾中断】
在处理器在响应某些异常时,如果又发生其他异常,但它们优先级不够高,则它们会被阻塞。
那么,在当前的异常执行返回后,系统处理悬起的异常时,倘若还是先POP,然后又把POP处理的内容PUSH回去,那么就白白浪费CPU时间了。因此,Cortex-M3不会再POP这些寄存器,而是继续使用上一个异常已经PUSH好的结果,消除POP和PUSH操作的耗时。
这么一来,看上去好像后一个异常把前一个的尾巴要掉了,前前后后只执行了一次PUSH/POP操作。于是,这两个异常之间的“时间沟”就变窄了很多,如图所示:

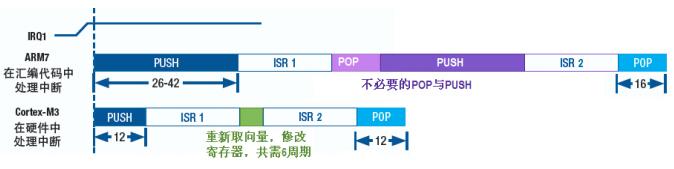
和常规中断处理(ARM7)的比较:
【晚到中断】
Cortex-M3的中断处理还有另一个机制,它强调了优先级的作用,这就是“晚到的异常处理”。
当Cortex-M3对某异常的响应序列还处在早期:入栈的阶段,尚未执行其他服务程序时。如果此时收到了更高优先级异常的请求,则本次入栈就成了高优先级中断做的了。入栈后,将执行高优先级的异常服务程序。可见,高优先级的异常虽然来晚了,却因为优先级高使得服务程序可以被先处理,低优先级异常的入栈操作则变成了为高优先级异常的入栈。
比如,若在响应某低优先级异常#1的早起,检测到了高优先级异常#2,则只要#2没有太晚,就能以“晚到中断”的方式处理,在入栈完毕后执行ISR#2。如图所示:

如果异常#2来得太晚,以至于已经执行了ISR#1的指令,则按普通的抢占处理,这会需要更多的处理器时间和额外32字节的堆栈空间。在ISR#2执行完毕后,则以“咬尾中断”的方式来启动ISR#1的执行。
参考摘录:
《Cortex-M内核系列和STM32-讲座2教程.pdf》
《ARM Cortex-M3权威指南.pdf》