爬取网站:第一PPT(http://www.1ppt.com/) 此网站真的良心
老样子,先上最后成功的源码(在D盘创建一个PPT文件夹,直接将代码执行就可获取到PPT):
import requests
import urllib
import os
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
def getPPT(url):
f = requests.get(url,headers=headers) #发送GET请求
f.encoding = f.apparent_encoding #设置编码方式
soup1 = BeautifulSoup(f.text,'lxml') #使用lxml解析器解析
classHtml = soup1.find('div',class_="col_nav i_nav clearfix").select('a') #在html中查找标签为div,class属性为 col_nav...的代码块并获取所有的 a 标签
for i in classHtml[:56]: #只要前56个类别
classUrl = i['href'].split('/')[2] #将ppt模板类别关键词存到classUrl,i['href']表示获取i中href属性的值,split('/')[2]表示以'/'为分隔符区第二个值
if not os.path.isdir(r'D:PPT\'+i['title']): #判断有无此目录,两个\,第一个转义了第二个
os.mkdir(r'D:PPT\'+i['title']) #若无,创建此目录。
else:
continue #若有此目录,直接退出循环,就认为此类别已经下载完毕了
n = 0 #定义一个变量用来统计模板的个数
for y in range(1,15): #假设每个类别都有14页ppt(页数这一块找了很久,没找到全部获取的方法,只能采取此措施)
pagesUrl = url+i['href']+'/ppt_'+classUrl+'_'+str(y)+'.html' #获取每一页的URL
a = requests.get(pagesUrl,headers=headers)
if a.status_code != 404: #排除状态码为404的网页
soup2 = BeautifulSoup(a.text,'lxml')
for downppt in soup2.find('ul',class_='tplist').select('li > a'): #获取每一个模板下载界面的URL,find作用不再赘述,select('li > a')表示查看li标签下的a标签的内容
b = requests.get(url+downppt['href'],headers=headers) #获取最后的下载界面的html
b.encoding = b.apparent_encoding #设置编码类型
soup3 = BeautifulSoup(b.text,'lxml') #因为到了一个新的界面,要重新获取当前界面html
downList = soup3.find('ul',class_='downurllist').select('a') #获取下载PPT的URL
pptName = soup3.select('h1') #获取ppt模板名称
print('Downloading......')
try:
urllib.request.urlretrieve(downList[0]['href'],r'D:PPT\'+i['title']+'/'+pptName[0].get_text()+'.rar') #开始下载模板
print(i['title']+'type template download completed the '+str(n)+' few.'+pptName[0].get_text())
n += 1
except:
print(i['title']+'type download failed the '+str(n)+' few.')
n += 1
if __name__ == '__main__':
headers = {'user-agent':UserAgent().random} #定义请求头
getPPT('http://www.1ppt.com')
效果图:

逻辑其实挺简单的,代码也不算复杂。
代码基本都有注释,先一起捋一遍逻辑吧,逻辑搞清楚,代码不在话下。
1、首先网站首页:F12—>选择某个类别(比如科技模板)右击—>检查—>查看右侧的html代码

发现类别的URL保存在 <div class="col_nav" i_nav clearfix> 下的 <li> 标签里的 <a> 标签的 href 属性值中
于是想到用 BeautifulSoup 库的 find() 方法和 select() 方法
2、进入类别界面
同样:F12—>选择某个PPT(例如第一个)右击—>检查—>查看右侧html代码

照葫芦画瓢,继续获取进入下载界面的URL,方法同上
但在此页面需要注意的是,下边有选页标签:
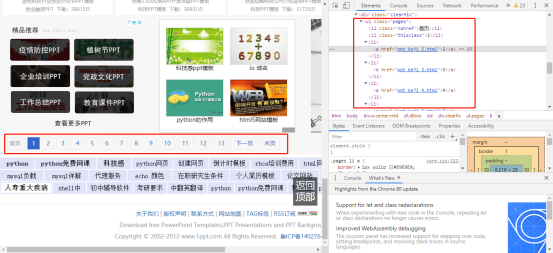
我暂时没有想到准确获取一共有多少页的方式,所以我在此代码中选择用range()函数来假设每个类别都有14页,然后再进行一步判断,看返回的http状态码是否为200。
3、进入具体PPT的下载界面
与上操作相同,获取最终PPT的下载URL
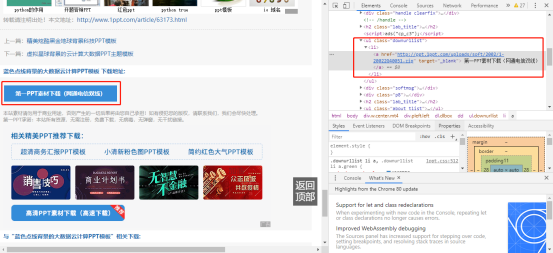
我在此代码中选择用 urllib 库来进行下载,最终将相对应类别的PPT放置同一文件夹中。
文件夹操作我是调用 os 库,具体代码还是往上翻一翻吧。
具体流程就这么几步了,剩下的就是循环 循环 再循环......
循环语句写好,就大功告成了!一起努力。