本文将针对spark中的Driver和Executor讲起,简述了spark的运行流程,部署模式以及内部任务调度机制,希望针对spark任务执行过程进行尽可能好理解的解析
1.两个重要的主角
在spark中,有两个重要的主角是绕不开的,driver和executor,他们的结构呈一主多从模式,driver就是那个单身狗,控制欲很强,权利也很大,每天独自一人没别的事,就想法设法的指挥着手下一堆executor到处干活。他们分工明确,组织结构简单,共同支撑起了spark强大的计算引擎。
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。Driver 在 Spark 作业执行时主要负责:
1. 将代码逻辑转化为任务;
2. 在 Executor 之间调度任务(job);
3. 跟踪 Executor 的执行情况(task)。
Executor
Spark 执行器节点,负责在 Spark 作业中运行具体任务,任务之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。Executor 有两个核心功能:
1. 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程;
2. 通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Spark 运行流程
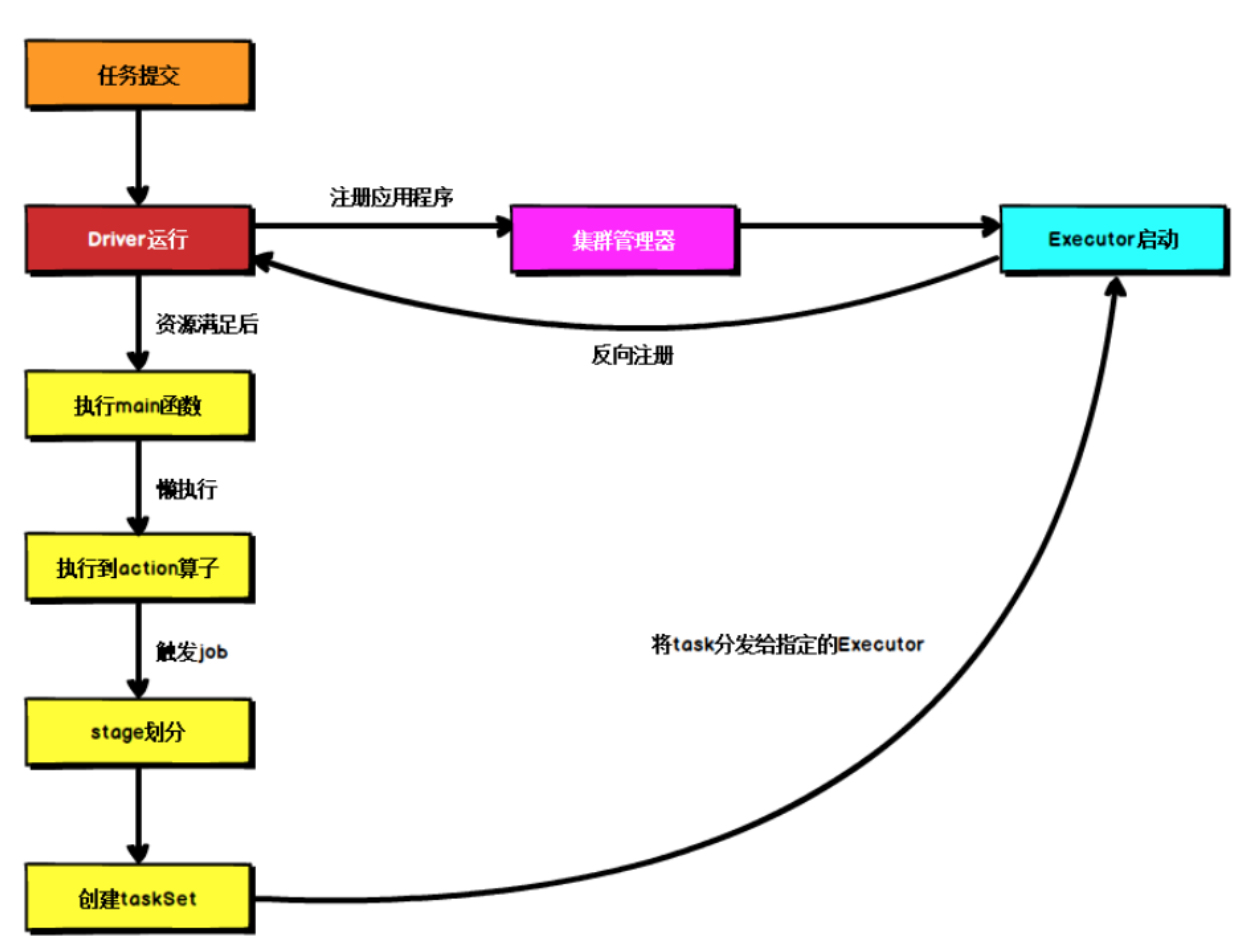
不论spark以何种方式部署,在任务提交后,都先启动Driver,然后Driver向集群管理器注册应用程序,之后集群管理器根据此任务的配置文件分配Executor并启动,然后Driver等待资源满足,执行 main 函数,Spark的查询为懒执行,当执行到 action 算子时才开始真正执行,开始反向推算,根据宽依赖进行 stage 的划分,随后每一个 stage 对应一个 taskset,一个taskset 中有多个 task,task 会被分发到指定的 Executor 去执行,在任务执行的过程中,Executor 也会不断与 Driver 进行通信,报告任务运行情况。
2.spark的部署模式
2.1 spark部署类型
Spark共支持3种集群管理器,Standalone,Mesos和Yarn
- Standalone:
独立模式,Spark 原生的最简单的一个集群管理器。 它可以运行在各种操作系统上,自带完整的服务,无需依赖任何其他资源管理系统,使用 Standalone 可以很方便地搭建一个集群。
-
Apache Mesos
Mesos也是一个强大的分布式资源管理框架,是以与Linux内核同样的原则而创建的,允许多种不同的框架部署在其上
-
Hadoop Yarn
Hadoop生态下的统一资源管理机制,在上面可以运行多套计算框架,如mapreduce、spark 等,根据 driver 在集群中的位置不同,部署模式可以分为 yarn-client 和 yarn-cluster。
Spark 的运行模式取决于传递给 SparkContext 的 MASTER 环境变量的值,spark在yarn上部署:
- yarn-client:Driver在本地,Executor在Yarn集群,配置:
--deploy-mode client - yarn-cluster:Driver和Executor都在Yarn集群,配置:
--deploy-mode cluster
- yarn-client:Driver在本地,Executor在Yarn集群,配置:
2.2 Yarn模式下的运行机制
当前流行的工作模式均是将spark提交到Yarn上,所以这里我们针对spark on Yarn做一下详细了解。
- yarn-client 模式
在YARNClient模式下,Driver在任务提交的本地机器上运行,Driver会向ResourceManager申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后
ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册。另外一条线,Driver自身资源满足的情况下,Driver开始执行main函数,之后执行Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,Executor注册完成后,Driver将task分发到各个Executor上执行。

- yarn-cluster
在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster,随后 ResourceManager 分配 container,在合适的 NodeManager上启动 ApplicationMaster,此时的ApplicationMaster 就是 Driver。
Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager会分配container,然后在合适的 NodeManager 上启动 Executor 进程,Executor 进程启动后会向 Driver 反向注册。另外一条线,Driver自身资源满足的情况下,开始执行main函数,之后执行Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,Executor注册完成后,Driver将task分发到各个Executor上执行。

3.Spark 任务调度
Driver会根据用户程序准备任务,并向Executor分发任务,在这儿有几个Spark的概念需要先介绍一下:
-
Job:以Action算子为界,遇到一个Action方法就触发一个Job
-
Stage:Job的子集,一个job至少有一个stage,以shuffle(即RDD宽依赖)为界,一个shuffle划分一个stage
-
Task: Stage 的子集,以并行度(分区数)来衡量,分区数是多少,则有多少
个 task。
spark在具体任务的调度中,总的分两路进行:Stage级别调度和Task级别调度。Spark RDD通过转换(Transactions)算子,形成了血缘关系图DAG,最后通过行动(Action)算子,触发Job并调度执行。
DAGScheduler负责Stage级的调度,主要是将DAG切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行
3.1 Spark Stage级调度
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来处理。
DAGScheduler主要做两个部分的事情:
- 切分stage
DAGScheduler会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是:从后往前,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,遇到一个shuffle就划分一个Stage。无shuffle的称为窄依赖,窄依赖之间的RDD被划分到同一个Stage中。划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据。
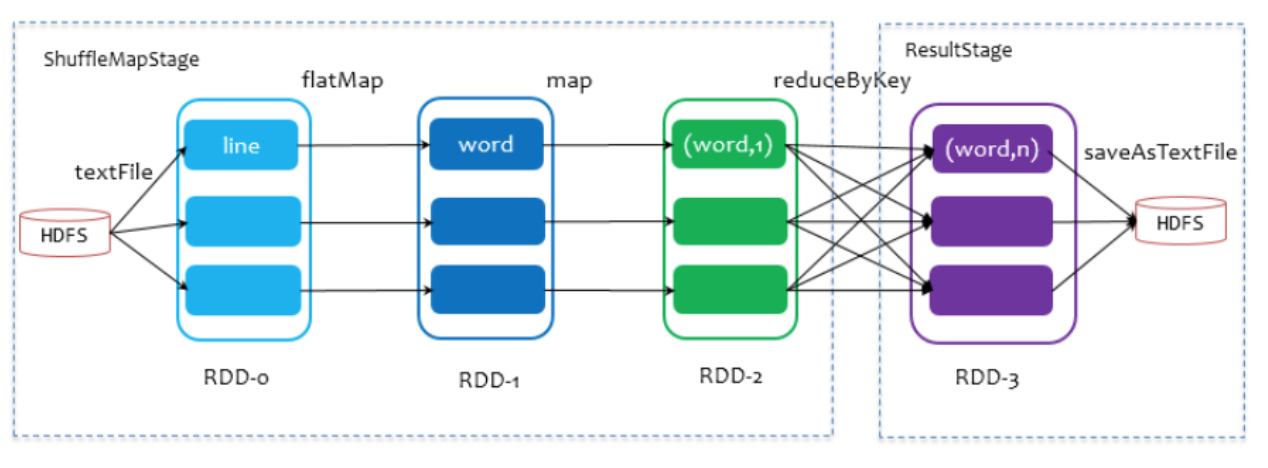
stage任务调度本身是一个反向的深度遍历算法,以下图wordcount为例。此处只有saveAsTextFile为行动算子,该 Job 由 RDD-3 和 saveAsTextFile方法组成,根据依赖关系回溯,知道回溯至没有依赖的RDD-0。回溯过程中,RDD-2和RDD-3存在reduceByKey的shuffle,会划分stage,由于RDD-3在最后一个stage,即划为ResultStage,RDD-2,RDD-1,RDD-0,这些依赖之间的转换算子flatMap,map没有shuffle,因为他们之间是窄依赖,划分为ShuffleMapStage。
- 打包Taskset提交Stage
一个Stage如果没有父Stage,那么从该Stage开始提交,父Stage执行完毕才能提交子Stage。Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面TaskScheduler会监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
3.2 Spark Task 级调度
SparkTask的调度是由TaskScheduler来完成,TaskScheduler将接收的TaskSet封装为TaskSetManager加入到调度队列中。同一时间可能存在多个TaskSetManager,一个TaskSetManager对应一个TaskSet,而一个TaskSet含有n多个task信息,这些task都是同一个stage的。
TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,SchedulerBackend会监控到有资源后,会询问TaskScheduler有没有任务要运行,TaskScheduler会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行。
TaskSetManager按照一定的调度规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的运行状态
3.3 失败重试和白名单
对于运行失败的Task,TaskSetManager会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中等待重新执行,当重试次数过允许的最大次数,整个Application失败。在记录Task失败次数过程中,TaskSetManager还会记录它上一次失败所在的ExecutorId和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。