kafka的消费者
@
内容大纲
深入学习kafka数据消费大致流程
创建并使用消费者
kafka消费者常用配置
1.重要概念
消费者和消费组
消费者负责订阅 Kafka 中的主题(Topic),并且从订阅的主题上拉取消息。
与其他一些消息中间件不同的是:在 Kafka 中还有一层消费组(Consumer Group)的概念,每个消费者都有一个对应的消费组。
同一个分区内的消息只能被同一个消费组中的一个消费者消费
消费者和消费组的简单使用
对消息中间件而言,一般有两种消息投递模式:点对点(P2P,Point-to-Point)模式和发布/订阅(Pub/Sub)模式。Kafka 也支持两种消息投递模式:
- 如果所有的消费者都在同一个消费组,消息会被均衡地投递给每一个消费者,即每条消息只会被一个消费者处理,点对点模式。
- 如果所有的消费者都在于不同的消费组,消息都会被广播给所有消费者,即每条消息会被所有的消费者处理,发布/订阅模式。
消费者在进行消费前需要指定其所属消费组的名称,这个可以通过消费者客户端参数 group.id 来配置,默认值为空字符串。
2. 消息接收
一个正常的消费逻辑需要具备以下几个步骤:
- 配置消费者客户端参数及创建相应的消费者实例。
- 订阅主题。
- 拉取消息并消费。
- 提交消费位移。
- 关闭消费者实例。
2.1 重要参数
2.2 订阅主题和分区
一个消费者可以订阅一个或多个主题,消费者消费订阅方式大致有3类:
如果没有订阅,那么订阅状态为 NONE。这三种状态是互斥的,在一个消费者中只能使用其中的一种
-
subscibe接收主题列表 (订阅状态:AUTO_TOPICS)
//同时订阅了topic1和topic2 consumer.subscribe(Arrays.asList(topic1,topic2));需要注意的是,以下方式是订阅了两次不同的主题,以最后一次为准
consumer.subscribe(Arrays.asList(topic1)); consumer.subscribe(Arrays.asList(topic2)); //最终只订阅了topic2 -
subscibe接收正则表达式(订阅状态:AUTO_PATTERN)
consumer.subscribe(Pattern.compile("topic-.*")); -
assign指定分区(订阅状态:USER_ASSIGNED)
//订阅指定的Topic的指定分区 consumer.assign(Arrays.asList(new TopicPartition("topic1", 0)));
2.3 位移提交
当消息从broker返回消费者时,broker并不跟踪消息是否被接收到;Kafka让消费者自身来管理消费的位移,并向消费者提供更新位移的接口,称为位移提交(commit)。
正常情况下,消费者会发送分区的commit到Kafka,Kafka进行记录。消费者启动或重启后都可通过位移提交知道从哪里继续消费。commit默认消费客户端是自动提交的,通常会设置为手动提交。
切记:消费者offset指的是消费者要消费的下一条消息的位移,而不是当前消费到哪里了。
消费者偏移量并不复杂,具体是记录消费者针对某个主题的消费进度的键值对:
- 键:Group id + 主题 + 分区号
- 值:offset值
kafka 0.9 之前,consumer默认将offset保存在zookeeper中,后续版本将offset的消费记录在一个topic中:_consumer_offset,默认有50个分区,每个分区默认1个副本,如下图:

这个主题除了放消费者消费偏移量之外还会存放其他类型消息,保存消费者组的注册消息和删除Group过期位移消息,而删除其实就是根据键来保留最近的消息。
(1)重复消费和消息丢失
当消费者宕机或者新消费者加入时,Kafka会进行重平衡,这会导致消费者负责之前并不属于它的分区。重平衡完成后,消费者会重新获取分区的位移,会出现以下两种情况。
- 假如一个消费者在重平衡前后都负责某个分区,如果提交位移比之前实际处理的消息位移要小,那么会导致消息重复消费
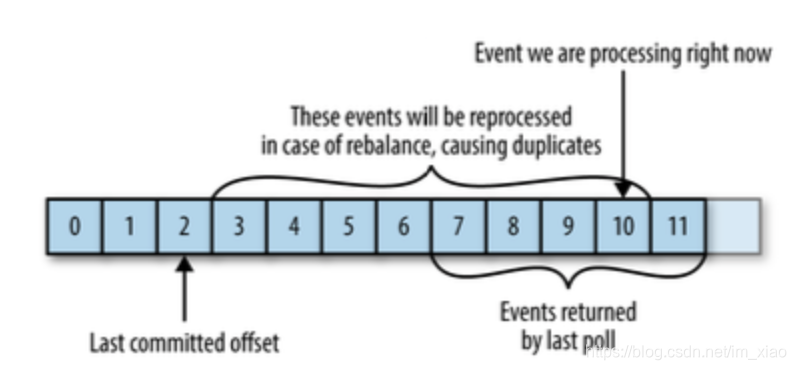
-
假如在重平衡前某个消费者拉取分区消息,在进行消息处理前提交了位移,但还没完成处理宕机了,然后Kafka进行重平衡,新的消费者负责此分区并读取提交位移,此时会“丢失”消息
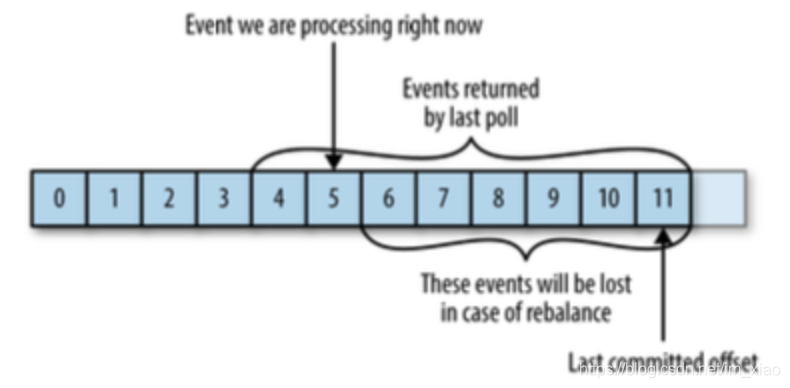
提交位移的方式会对应用有比较大的影响
(2)自动提交
这种方式消费者管理位移。由参数enable.auto.commit设置为true/false来控制,消费者会在poll方法调用后每隔5秒(由auto.commit.interval.ms指定)提交一次位移。
假如,某个消费者poll消息后,应用正在处理消息,在3秒后Kafka进行了重平衡,那么由于没有更新位移导致这部分消息会重复消费。
(3)手动同步提交和手动异步提交
手动提交需设置auto.commit.offset为false,通过调用commitSync()来主动提交位移,该方法会提交poll返回的最后位移。为了避免消息丢失,我们应当在完成业务逻辑后才提交位移,自动提交是间隔时间提交,不关注业务是否成功。而如果在处理消息时发生了重平衡,那么只有当前poll的消息会重复消费。
手动同步提交有一个缺点,那就是当发起提交调用时应用会阻塞。
为避免阻塞,可使用异步提交方式:commitAsync。异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
自动提交和手动提交的实战:
//通过设置true/false 进行开启和关闭自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
关闭后,如果不设置手动提交,每次重启或者启动消费者,都会从以往记录的最大offset开始重复消费
//手动同步提交方式
consumer.commitSync();
//手动异步提交方式
consumer.commitAsync();
//手动异步提交-完成后能获知结果
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
System.out.println("当前offset:"+record.offset());
}
});
2.4 指定位移提交
kafka消费者可以通过提交指定的位移进行消费。从指定的位置开始消费
指定位移方法:
//指定topic partition 和offset
consumer.seek(newTopicPartition(topic,partition),offset);
其中,由于消费者固定未指定消费分区,均是由消费者组分配,指定的主题和分区和消费者分配到的分区可能不一致,因此可通过assignment方法获取分区
//获取消费者的topic和partition集合
Set<TopicPartition> topicPartitionSet = consumer.assignment();
while(topicPartitionSet == null && topicPartitionSet.size() ==0){
//一般需要先poll才能获取到集合
consumer.poll(Duration.ofMillis(5000));
topicPartitionSet = consumer.assignment();
}
System.out.println("主题和分区:"+topicPartitionSet);
for(TopicPartition topicPartition : topicPartitionSet){
//指定分区消费
consumer.seek(topicPartition,2);
}
2.5 再均衡监听器
再均衡(Rebalance):在Kafka中,当有新消费者加入或者订阅的topic数发生变化时,会触发Rebalance机制,Rebalance顾名思义就是重新均衡消费者消费,在同一个消费者组当中,分区的所有权从一个消费者转移到另外一个消费者。再均衡期间,消费者是无法拉取消息的。
前面说过,再均衡期间可能会触发消息重复消费或者消息丢失,kafka提供了再均衡监听器,帮助处理这种情况:
ConsumerRebalanceListener接口提供两个方法
//方法会在再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管分区的消费者就知道该从哪里读取了。
public void onPartitionsRevoked(Collection<TopicPartition> partitions);
//方法会在重新分配分区之后和消费者开始读取消息之前被调用。
public void onPartitionsAssigned(Collection<TopicPartition> partitions);
实例代码:
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
//订阅主题 collection 订阅的时候,实现匿名接口,再均衡监听器
consumer.subscribe(Collections.singleton(TOPIC),new ConsumerRebalanceListener(){
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("再均衡之前提交偏移量");
consumer.commitSync(currentOffsets);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("再均衡后开始重新消费了");
}
});
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(5000));
for(ConsumerRecord<String,String> record:records){
//记录当前消费情况,当发生再均衡时,触发监听器提交消费情况,下一个消费者就能知道从哪儿开始消费
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata"));
consumer.commitAsync(currentOffsets,null);
}
}
2.6 消费者拦截器
生产者有拦截器,对应的,消费者也有拦截器。
同样的,需kafka提供接口用于实现:ConsumerInterceptor
共有四个方法:
//消息消费前拦截
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records);
//提交位移前拦截
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
//关闭消费者拦截
public void close();
//配置生效前拦截
public void configure(Map<String, ?> configs);
使用拦截器也很简单,配置里加入拦截器即可:
properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,MyConsumerInterceptor.class.getName());
示例:
public class MyConsumerInterceptor implements ConsumerInterceptor<String,String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
System.out.println("消费消息之前被拦截");
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
System.out.println("提交消费位移之前被拦截");
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
Set<String> set = configs.keySet();
set.forEach((e)-> System.out.println(e));
}
}
public class MyConsumer {
private static final String BROKERLIST = "172.23.7.12:9092";
private static final String TOPIC = "mytopic";
private static final String GROUPID = "group.demo";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,BROKERLIST);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,GROUPID);
//添加监听器
properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
MyConsumerInterceptor.class.getName());
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton(TOPIC));
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(5000));
for(ConsumerRecord<String,String> record:records){
System.out.println(record.topic()+" ---> "+record.value());
}
}
}
}