受限词汇量:我们不能把全部的所有词汇都汇总起来,这个集合太大了。我们只能选一些。
受计算复杂度的限制,仅能使用有限的词汇量。

这里有几种方法:
- 未登录词替换 unknown key replace :在后处理阶段,单独翻译未登录词
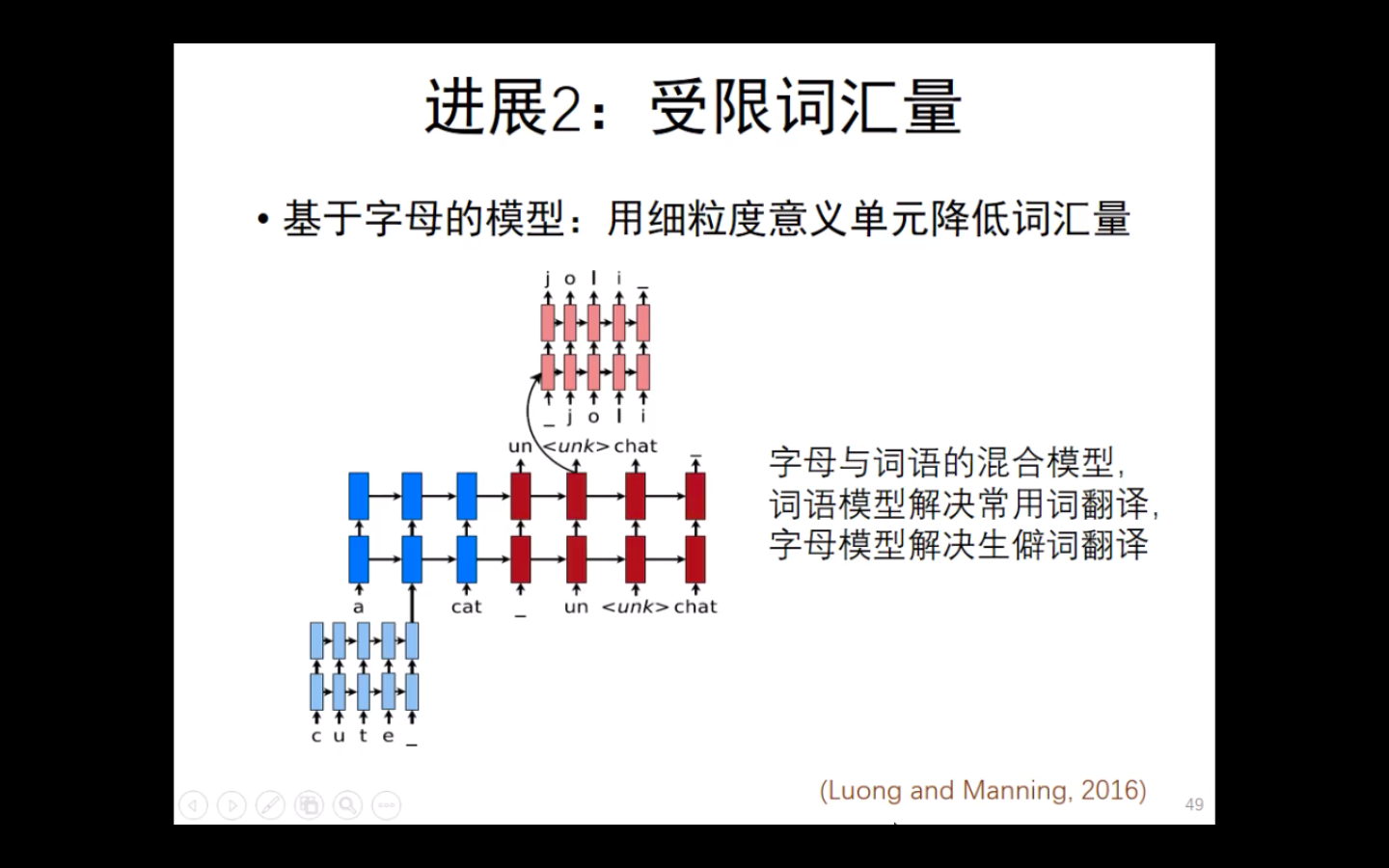
- 基于字母的模型。用更细粒度单元降低词汇量。
- 子词:BPE 合并高频字符串对实现子词切分。
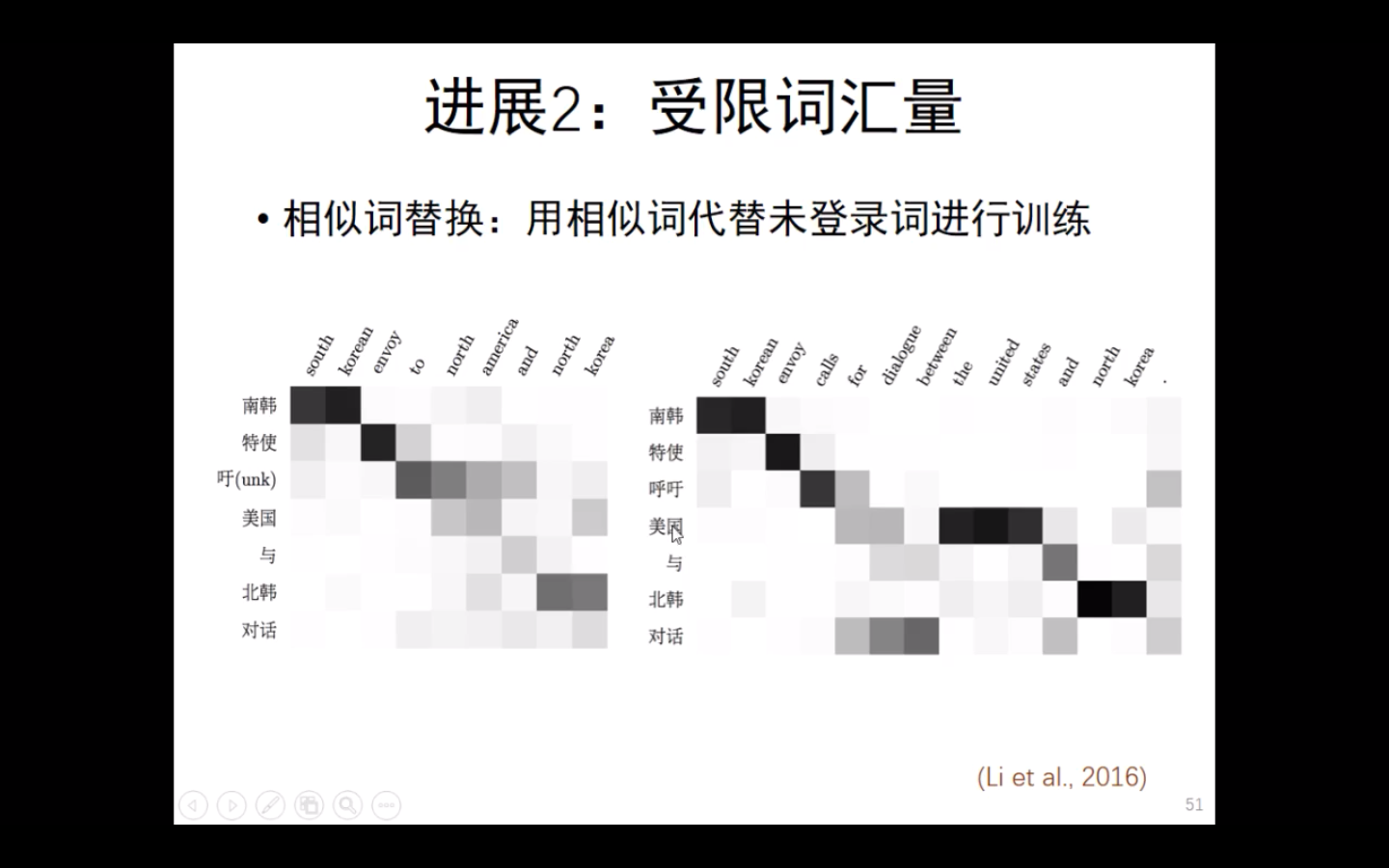
- 相似词替换:用相似词代替未登录词进行训练


——————————————————————————————————————————————————————————————
先验约束是什么呢?
神经网络是数据驱动的,先验知识即数据以外的知识。
- 先验约束

覆盖率的约束:不应该重复翻译,也不能漏翻

注意力机制中的结构化约束,从神经网络自身进行约束,对函数约束

一致性训练:翻译的正向和反向的结果大致是一致的,具有互补性。

________________________________________________________________________________________________________________________________________________________________________
对于神经网络而言,极大似然估计越大越好。

exposure bias问题:
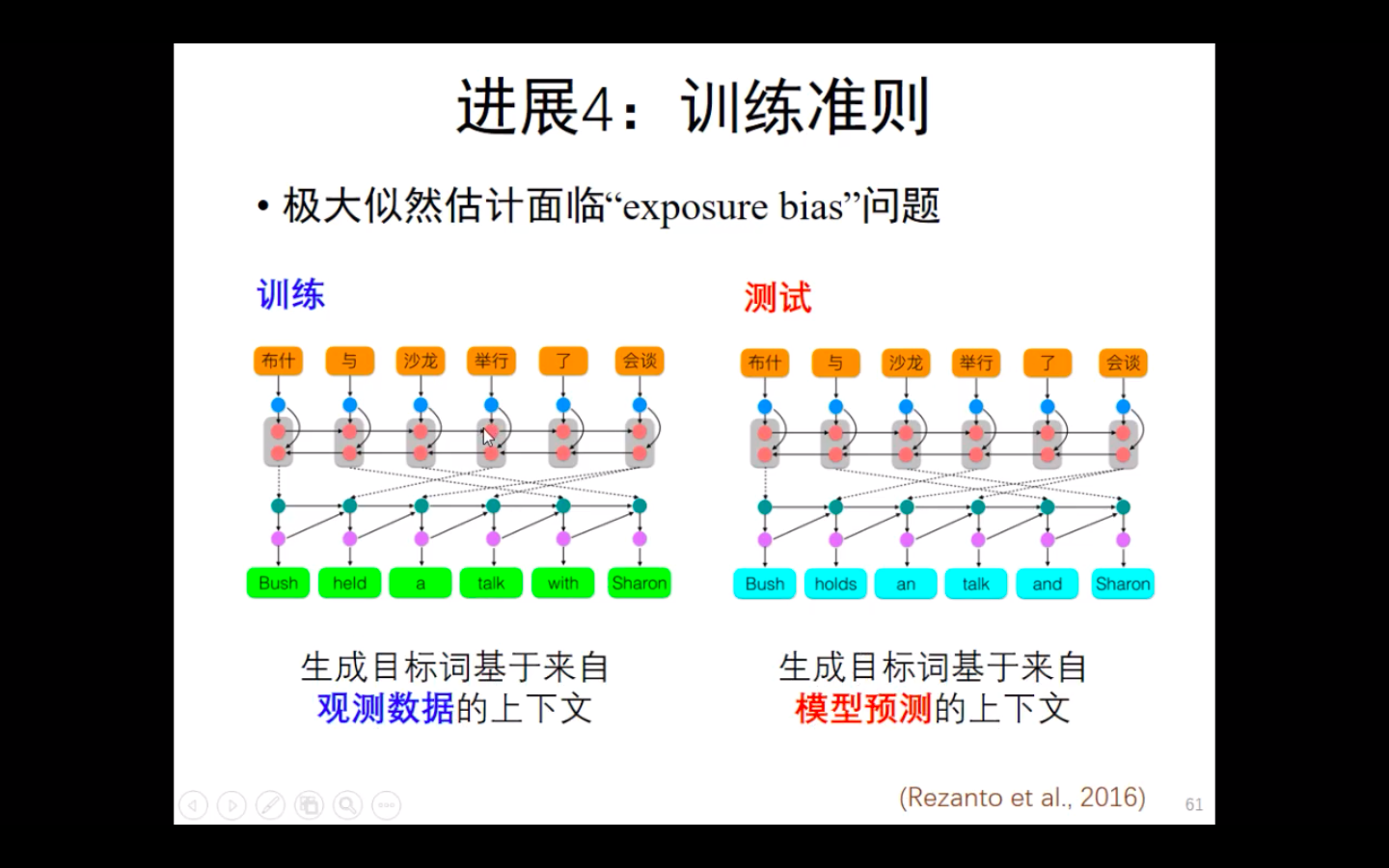
即在观测数据中,生成每一个目标词之前的所有词都是正确的。
而模型预测的生成词不能保证之前的每一个词是正确的。
————————————————————————
词级损失函数:
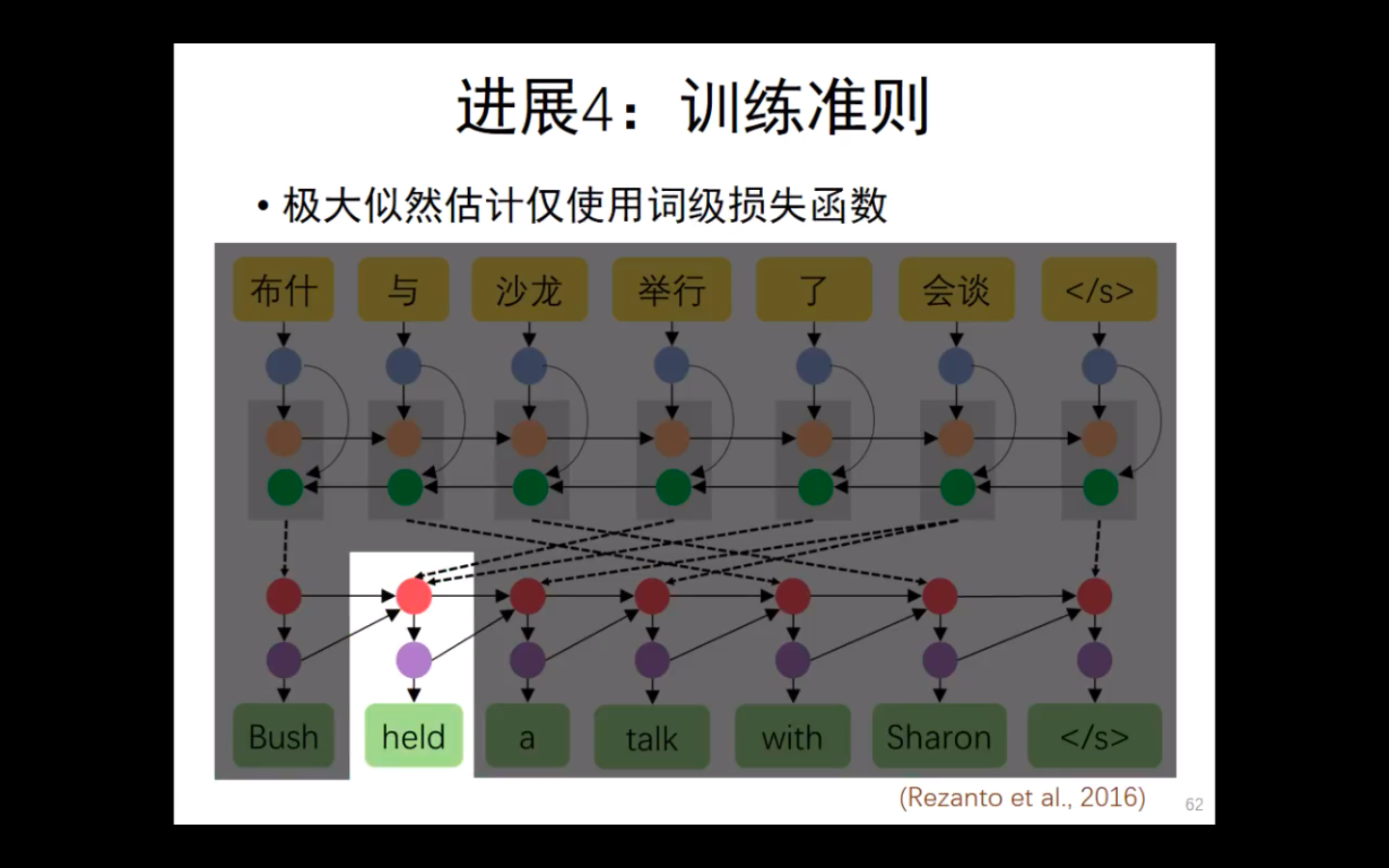
极大似然估计,只对每一个词,使用损失函数。它并不会考虑语序等
--------------
最小风险训练

柱搜索优化
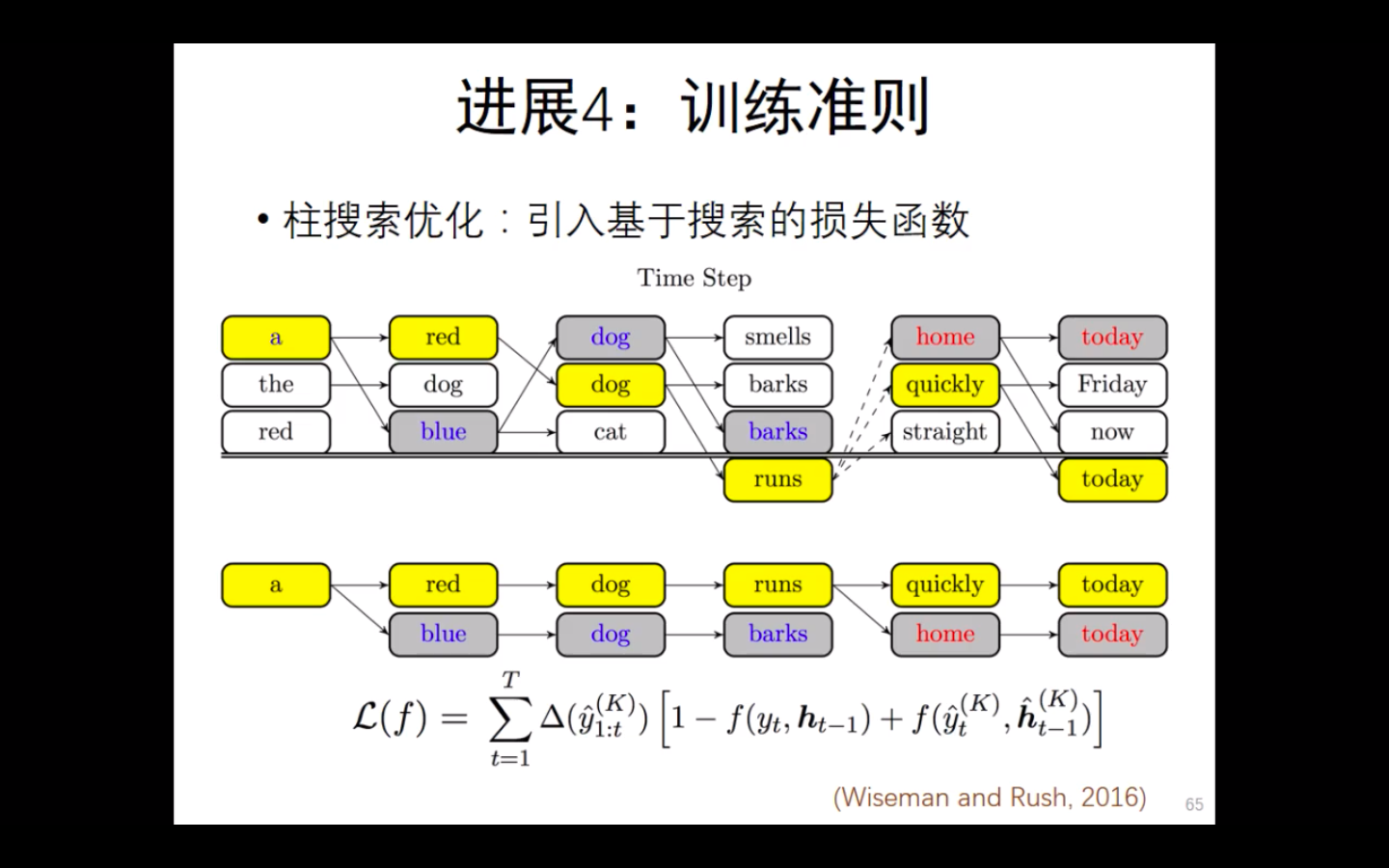
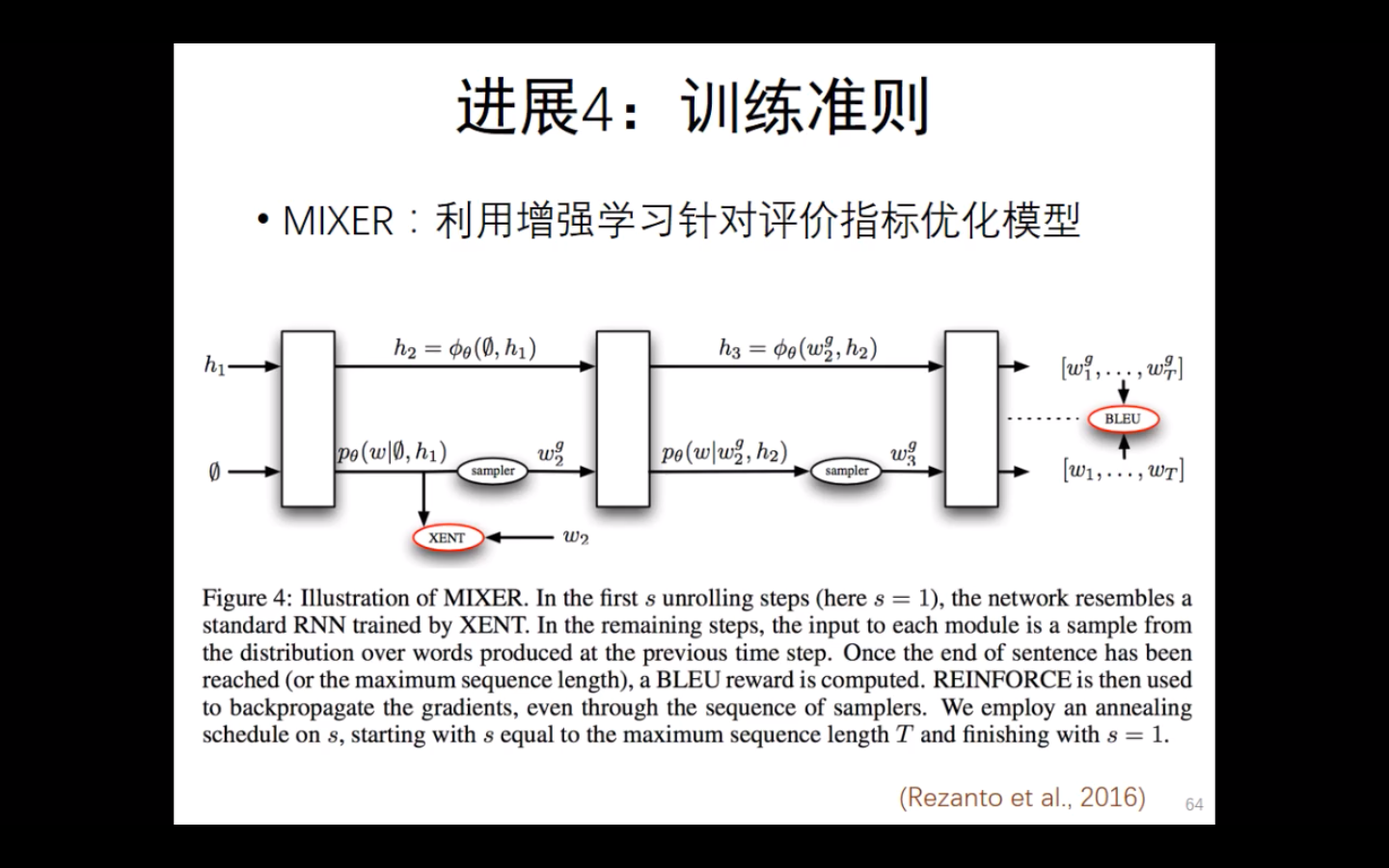
MIXER: 利用增强学习针对评价指标优化模型。