http://blog.csdn.net/u011889952/article/details/44813593
整数拆分问题的四种解法
整数划分问题是算法中的一个经典命题之一
所谓整数划分,是指把一个正整数n写成如下形式:
n=m1+m2+m3+....+mi;(其中mi为正整数,并且1<=mi<=n),则{m1,m2,m3,....,mi}为n的一个划分。
如果{m1,m2,m3,....,mi}中的最大值不超过m,即max{m1,m2,m3,....,mi} <= m,则称它属于n的一个m划分。这里我们记n的m划分的个数为f(n,m);
例如当n=4时,它有5个划分:{4}、{3,1}、{2,2}、{2,1,1}、{1,1,1,1};
注意:4=1+3和4=3+1被认为是同一个划分。
该问题是求出n的所有划分个数,即f(n,n)。下面我们考虑求f(n,m)的方法。
方法一:递归法
根据n和m的关系,考虑下面几种情况:
(1)当n=1时,不论m的值为多少(m>0),只有一种划分,即{1};
(2)当m=1时,不论n的值为多少(n>0),只有一种划分,即{1,1,....1,1,1};
(3)当n=m时,根据划分中是否包含n,可以分为两种情况:
(a)划分中包含n的情况,只有一个,即{n};
(b)划分中不包含n的情况,这时划分中最大的数字也一定比n小,即n的所有(n-1)划分;
因此,f(n,n) = 1 + f(n, n - 1)。
(4)当n<m时,由于划分中不可能出现负数,因此就相当于f(n,n);
(5)当n>m时,根据划分中是否包含m,可以分为两种情况:
(a)划分中包含m的情况,即{m,{x1,x2,x3,...,xi}},其中{x1,x2,x3,...,xi}的和为n-m,可能再次出现m,因此是(n-m)的m划分,因此这种划分个数为f(n-m, m);
(b)划分中不包含m的情况,则划分中所有值都比m小,即n的(m-1)划分,个数为f(n, m - 1);
因此,f(n,m) = f(n - m,m) + f(n, m - 1)。
综合以上各种情况,可以看出,上面的结论具有递归定义的特征,其中(1)和(2)属于回归条件,(3)和(4)属于特殊情况,而情况(5)为通用情况,属于递归的方法,其本质主要是通过减少n或m以达到回归条件,从而解决问题。
其递归表达式如下所示。
参考源码1.1(递归版本(较慢))
- #include <stdio.h>
- #define MAXNUM 100 //最高次数
- //递归法求解整数划分
- unsigned long GetPartitionCount(int n, int max)
- {
- if(n == 1 || max == 1)
- {
- return 1;
- }
- if(n < max)
- {
- return GetPartitionCount(n, n);
- }
- if(n == max)
- {
- return 1 + GetPartitionCount(n, n - 1);
- }
- else
- {
- return GetPartitionCount(n - max, max) + GetPartitionCount(n, max - 1);
- }
- }
- int main(int argc, char **argv)
- {
- int n;
- int m;
- unsigned long count;
- while(1)
- {
- scanf("%d", &n);
- if(n<=0)
- return 0;
- m=n;
- count = GetPartitionCount(n, m);
- printf("%d ",count);
- }
- return 0;
- }
方法二:动态规划
考虑到使用递归中,很多的子递归重复计算,这样不仅在时间开销特别大,这也是运算太慢的原因,比如算120的时候需要3秒中,计算130的时候需要27秒钟,在计算机200的时候....计算10分钟还没计算出来。。。鉴于此,可以使用动态规划的思想进行程序设计,原理如同上面一样,分成三种情况,只是使用一个数组来代替原有的递归,具体可以参看源码,源码中提供了两个版本 递归+记录版本和数组版本
2.1 递归加记录版本
此版本使用数组标记,如果之前计算过,则直接调用数组中内容,否则计算子递归,这样保证了每次计算一次,减少冗余量
源码如下:
- /*----------------------------------------------
- * Author :NEWPLAN
- * Date :2015-04-01
- * Email :xxxxxxx
- * Copyright:NEWPLAN
- -----------------------------------------------*/
- #include <iostream>
- #define MAXNUM 100 //最高次数
- unsigned long ww[MAXNUM*11][MAXNUM*11];
- unsigned long dynamic_GetPartitionCount(int n, int max);
- using namespace std;
- int main(int argc, char **argv)
- {
- int n;
- int m;
- unsigned long count;
- while(1)
- {
- cin>>n;
- cout<<dynamic_GetPartitionCount(n,n)<<endl;
- }
- return 0;
- }
- unsigned long dynamic_GetPartitionCount(int n, int max)
- {
- if(n == 1 || max == 1)
- {
- ww[n][max]=1;
- return 1;
- }
- if(n < max)
- {
- ww[n][n]=ww[n][n]? ww[n][n] : dynamic_GetPartitionCount(n, n);
- return ww[n][n];
- }
- if(n == max)
- {
- ww[n][max]=ww[n][n-1]?1+ww[n][n-1]:1 + dynamic_GetPartitionCount(n, n - 1);
- return ww[n][max];
- }
- else
- {
- ww[n][max]=ww[n - max][max]? (ww[n - max][max]) : dynamic_GetPartitionCount(n - max, max);
- ww[n][max]+=ww[n][max-1]? (ww[n][max-1]): dynamic_GetPartitionCount(n, max - 1);
- return ww[n][max];
- }
- }
2.2 数组标记法动态规划(从小到大)
考虑到计算ww[10][10]=ww[10][9]+1;所以在每次计算中都是用到之前的记录,这样就可以先从小到大计算出程序,使得计算较大数的时候调用已经计算出的较小的记录,程序直接是用循环就可以完成任务,避免了重复计算和空间栈的开销。
源码:
- /*----------------------------------------------
- * Author :NEWPLAN
- * Date :2015-04-01
- * Email :xxxxxxx
- * Copyright:NEWPLAN
- -----------------------------------------------*/
- #include <iostream>
- #define MAXNUM 100 //最高次数
- unsigned long ww[MAXNUM*11][MAXNUM*11];
- unsigned long dynamic_GetPartitionCount(int n, int max);
- using namespace std;
- int main(int argc, char **argv)
- {
- int n;
- int m;
- unsigned long count;
- while(1)
- {
- cin>>n;
- cout<<dynamic_GetPartitionCount(n,n)<<endl;
- }
- return 0;
- }
- unsigned long dynamic_GetPartitionCount(int n, int max)
- {
- for(int i=1;i<=n;i++)
- for(int j=1;j<=i;j++)
- {
- if(j==1|| i==1)
- {
- ww[i][j]=1;
- }
- else
- {
- if(j==i)
- ww[i][j]=ww[i][j-1]+1;
- else if((i-j)<j)
- ww[i][j]=ww[i-j][i-j]+ww[i][j-1];
- else
- ww[i][j]=ww[i-j][j]+ww[i][j-1];
- }
- }
- return ww[n][max];
- }
三种方法效果对比十分明显,在写此博客之前测试数据200,动态规划版本输入直接算出结果,现在这片博客写完了,,,使用递归的还没计算出结果。。。
方法三:母函数
下面我们从另一个角度,即“母函数”的角度来考虑这个问题。
所谓母函数,即为关于x的一个多项式G(x):
有G(x) = a0 + a1*x + a2*x^2 + a3*x^3 + ......
则我们称G(x)为序列(a0, a1, a2,.....)的母函数。关于母函数的思路我们不做更过分析。
我们从整数划分考虑,假设n的某个划分中,1的出现个数记为a1,2的个数记为a2,.....,i的个数记为ai,
显然有:ak <= n/k(0<= k <=n)
因此n的划分数f(n,n),也就是从1到n这n个数字抽取这样的组合,每个数字理论上可以无限重复出现,即个数随意,使它们的综合为n。显然,数字i可以有如下可能,出现0次(即不出现),1次,2次,......,k次等等。把数字i用(x^i)表示,出现k次的数字i用(x^(i*k))表示,不出现用1表示。
例如,数字2用x^2表示,2个2用x^4表示,3个2用x^6表示,k个2用x^2k表示。
则对于从1到N的所有可能组合结果我们可以表示为:
G(x) = ( 1 + x + x^2 + x^3 + ... + x^n)*(1 + x^2 + x^4 + x^6 + ....)....(1 + x^n)
= g(x,1)*g(x,2)*g(x,3)*....*g(x,n)
= a0 + a1*x + a2*x^2 +...+ an*x^n + ....//展开式
上面的表达式中,每个括号内的多项式代表了数字i的参与到划分中的所有可能情况。因此,该多项式展开后,由于x^a *x^b = x^(a+b),因此x^i就代表了i的划分,展开后(x^i)项的系数也就是i的所有划分个数,即f(n,n) = an。
由此我们找到了关于整数划分的母函数G(x);剩下的问题就是,我们需要求出G(x)的展开后的所有系数。
为此,我们首先要做多项式乘法,对于我们来说,并不困难。我们把一个关于x的多项式用一个整数数组a[]表示,a[i]代表x^i的系数,即:
g(x) = a[0] + a[1]x + a[2]x^2 + ... + a[n]x^n;
则关于多项式乘法的代码如下,其中数组a和数组b表示两个要相乘的多项式,结果存储到数组c中。
参考题目: HDU:1028:Ignatius and the Princess III
参考源码:
- #include <iostream>
- #include <string.h>
- #include <stdio.h>
- using namespace std;
- const int N=10005;
- int c1[N],c2[N];
- int main()
- {
- int n,i,j,k;
- while(cin>>n)
- {
- if(n==0) break;
- for(i=0;i<=n;i++)
- {
- c1[i]=1;
- c2[i]=0;
- }
- for(i=2;i<=n;i++)
- {
- for(j=0;j<=n;j++)
- for(k=0;k+j<=n;k+=i)
- c2[k+j]+=c1[j];
- for(j=0;j<=n;j++)
- {
- c1[j]=c2[j];
- c2[j]=0;
- }
- }
- cout<<c1[n]<<endl;
- }
- return 0;
- }
方法四:五边形数定理
设第n个五边形数为,那么
,即序列为:1,
5, 12, 22, 35, 51, 70, ...
对应图形如下:
设五边形数的生成函数为,那么有:
以上是五边形数的情况。下面是关于五边形数定理的内容:
五边形数定理是一个由欧拉发现的数学定理,描述欧拉函数展开式的特性。欧拉函数的展开式如下:
欧拉函数展开后,有些次方项被消去,只留下次方项为1, 2, 5, 7, 12, ...的项次,留下来的次方恰为广义五边形数。
五边形数和分割函数的关系
欧拉函数的倒数是分割函数的母函数,亦即:
其中
为k的分割函数。
上式配合五边形数定理,有:
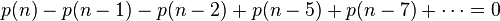
因此可得到分割函数p(n)的递归式:
例如n=10时,有: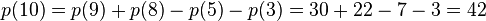
所以,通过上面递归式,我们可以很快速地计算n的整数划分方案数p(n)了