get方式得到网页的信息
#coding=utf-8
#pip install requests
#直接get到网页的信息
import requests
from bs4 import BeautifulSoup
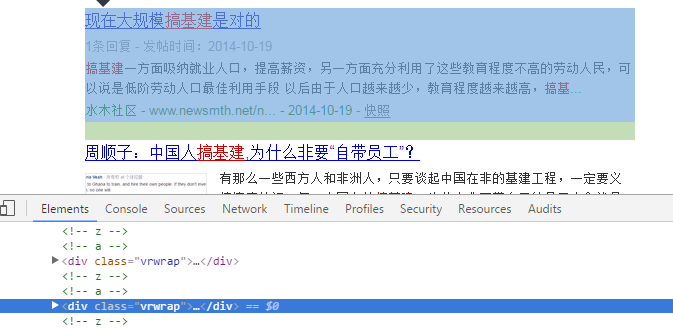
response = requests.get('https://www.sogou.com/web?query=搞基建')
print(response.text) #打印搜索出来的全部信息
#从 response.text 找出 <div class = 'wrwrap> </div>
soup = BeautifulSoup(response.text,'html.parser')
new_list = soup.find_all(name='div',class_='vrwrap')
print(new_list)
#可以继续从 <div class = 'wrwrap> </div> 继续查找
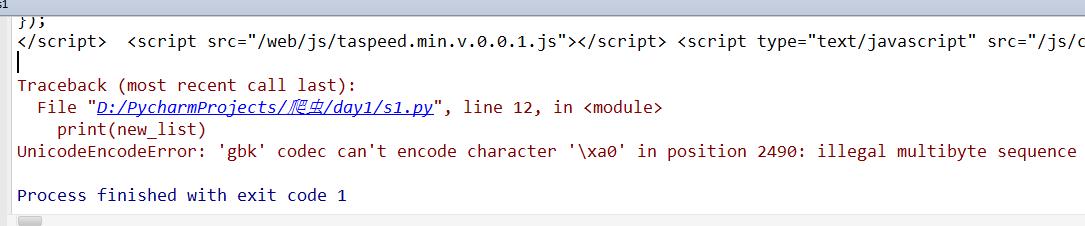
1.错误代码
Traceback (most recent call last):
File "D:/PycharmProjects/爬虫/day1/s1.py", line 12, in <module>
print(new_list)
UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position 2490: illegal multibyte sequence
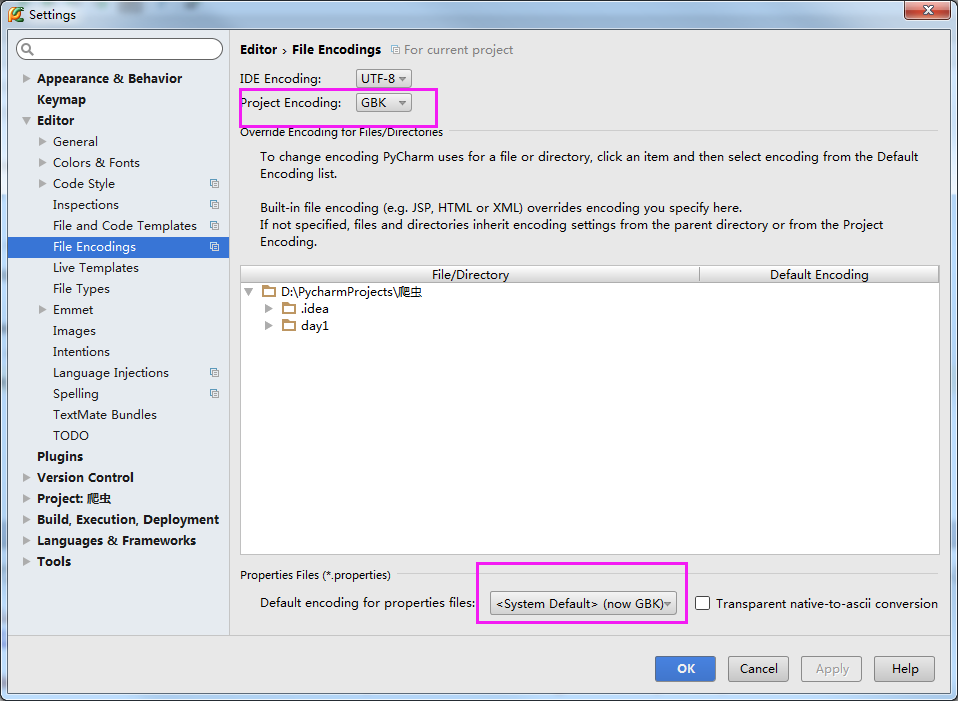
2.编码格式不对
3.全部改为utf-8
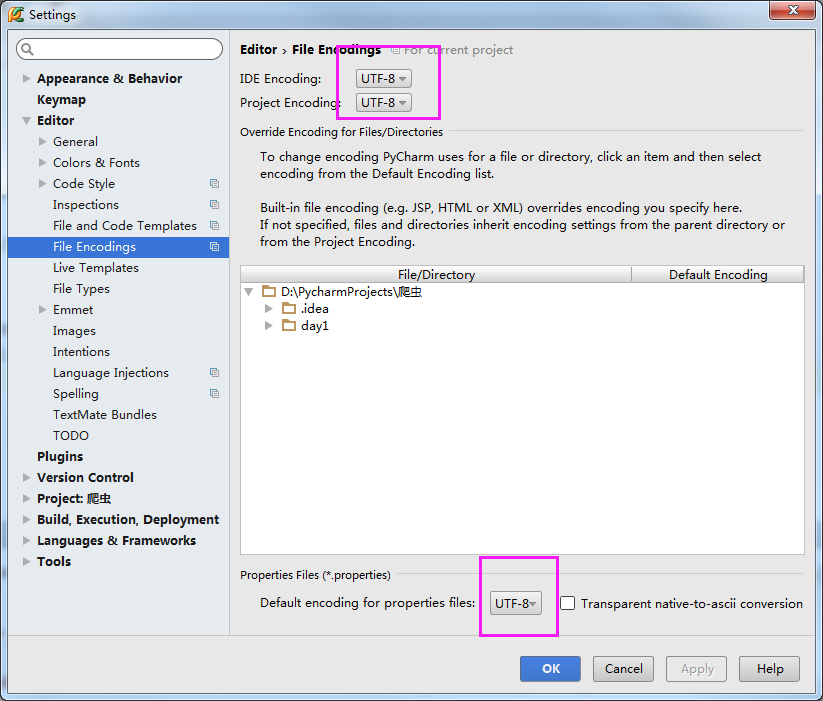
4.执行成功
