1、互斥锁(排他锁)
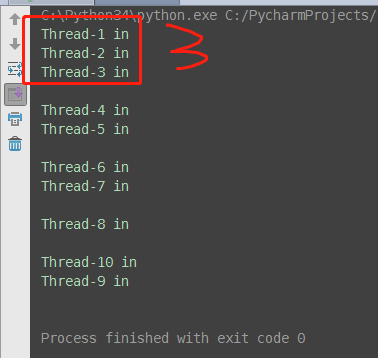
(1)不加锁的情况下
并发控制问题:多个事务并发执行,可能产生操作冲突,出现下面的3种情况
- 丢失修改错误
- 不能重复读错误
- 读脏数据错误
# mutex from threading import Thread import time n = 100 def task(): global n temp = n time.sleep(0.1) n = temp - 1 print(n) if __name__ == '__main__': t_l = [] for i in range(100): t = Thread(target=task) t_l.append(t) t.start() for t in t_l: t.join() print('主done', n)

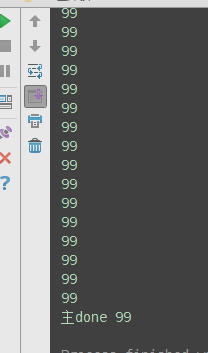
from threading import Thread,Lock import os,time def work(): global n lock.acquire() temp=n time.sleep(0.1) n=temp-1 lock.release() if __name__ == '__main__': lock=Lock() n=100 l=[] for i in range(100): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全,不加锁则结果可能为99
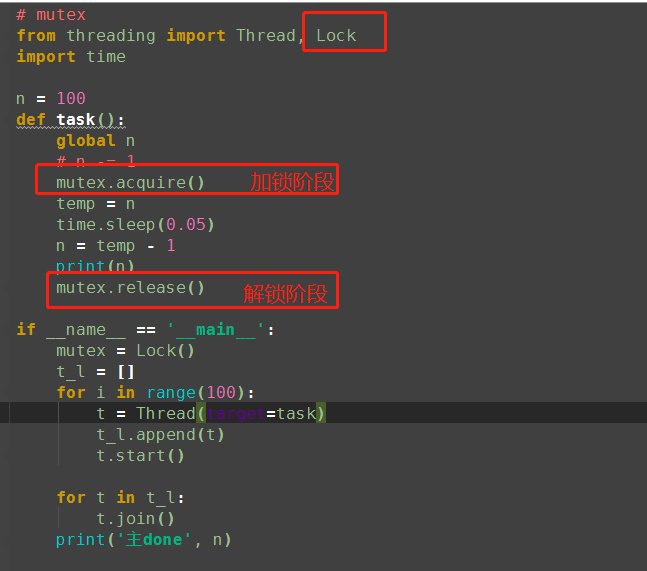
(2)、添加互斥锁(排他锁)
锁: 排它锁(可以修改数据)
共享锁(只可以读数据)


2、GIL全局解释器锁
参考博客: http://www.cnblogs.com/venicid/p/7975892.html

GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。

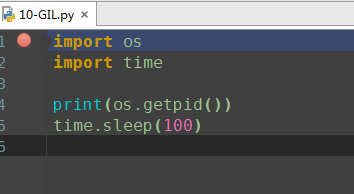
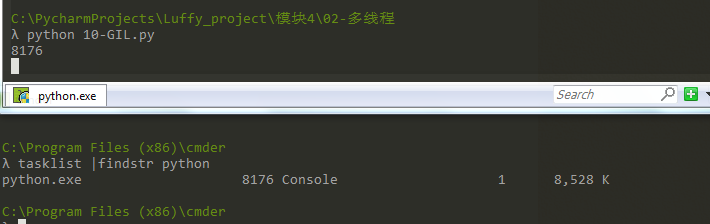
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问
1、所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
2、所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
3、GIL与Lock
GIL 与Lock是两把锁,保护的数据不一样, 前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据), 后者是保护用户自己开发的应用程序的数据

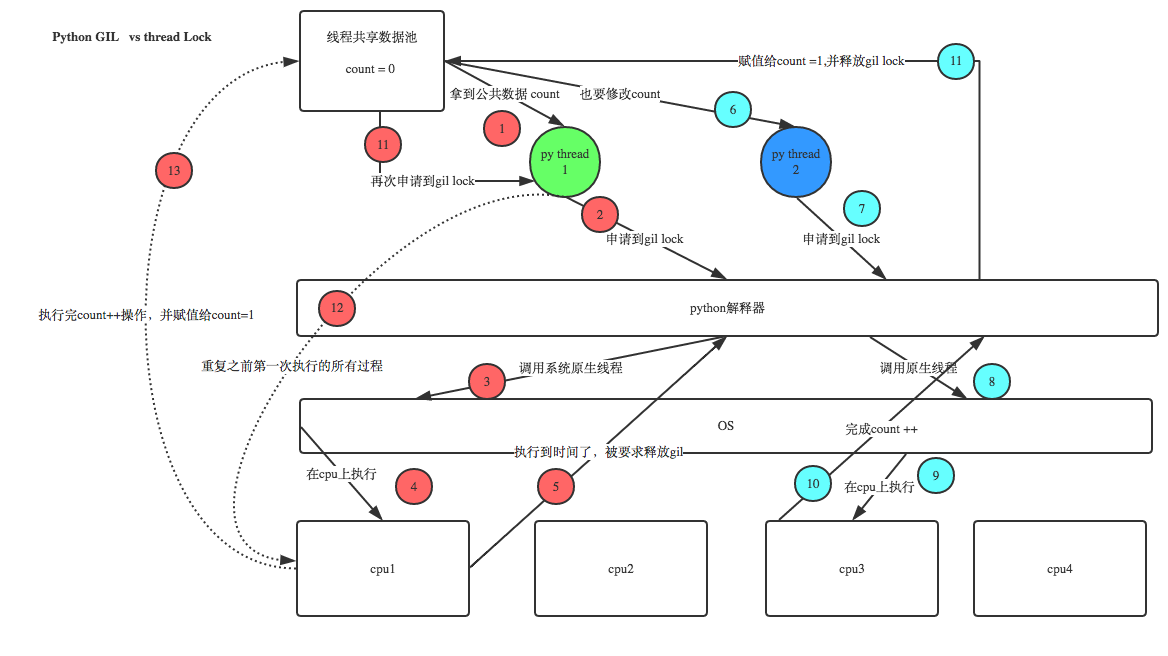
1、100个线程去抢GIL锁,即抢执行权限 2、肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire() 3、极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL 4、直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程

4、GIL与多线程

要解决这个问题,我们需要在几个点上达成一致: 1、cpu到底是用来做计算的,还是用来做I/O的? 2、多cpu,意味着可以有多个核并行完成计算,所以多核提升的是计算性能 3、每个cpu一旦遇到I/O阻塞,仍然需要等待,所以多核对I/O操作没什么用处

结论: 1、对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用 2、当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O, 所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地
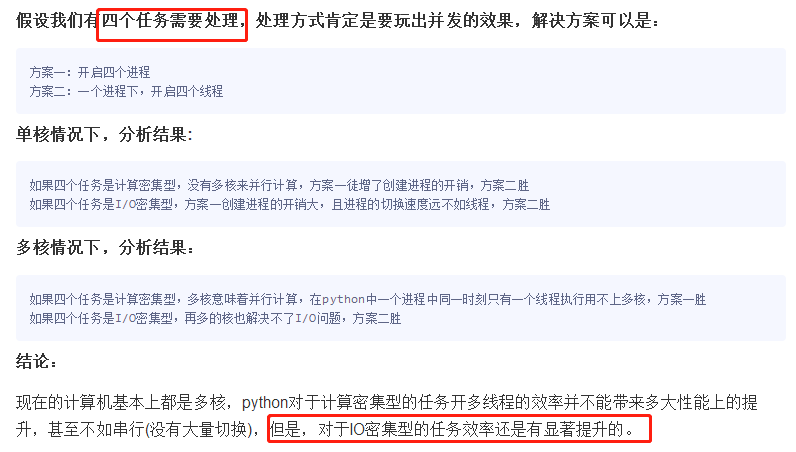
5、多线程性能测试
计算密集型、io密集型
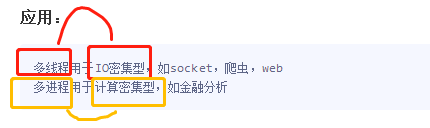
- 如果并发的多个任务是计算密集型:多进程效率高
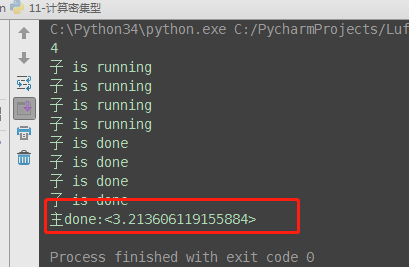
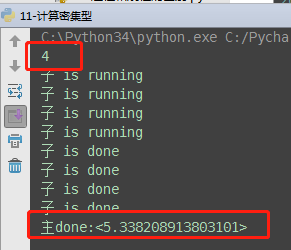
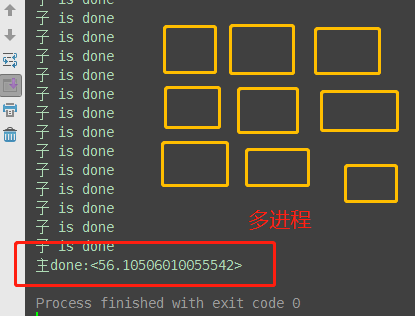
# 计算密集型:多进程执行效率高 from multiprocessing import Process from threading import Thread import time import os def task(): print('子 is running') ret = 0 for i in range(10000000): ret *= i print('子 is done') if __name__ == '__main__': print(os.cpu_count()) # 查看电脑cup内核数量:本机为4核 start_time = time.time() # 开启四个进程 p_list = [] for i in range(4): p = Process(target=task) # 耗时3.21s # p = Thread(target=task) 耗时5.38秒 p_list.append(p) p.start() # 等待4个进程执行完成 for p in p_list: p.join() end_time = time.time() print('主done:<%s>' % (end_time-start_time))
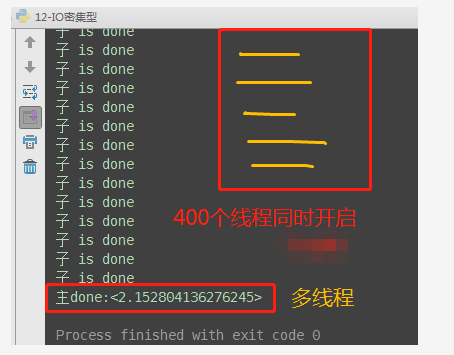
- 如果并发的多个任务是I/O密集型:多线程效率高
# io密集型:多线程执行效率高 from multiprocessing import Process from threading import Thread import time import os def task(): print('子 is running') time.sleep(2) print('子 is done') if __name__ == '__main__': print(os.cpu_count()) # 查看电脑cup内核数量:本机为4核 start_time = time.time() # 开启400个进程 p_list = [] for i in range(400): p = Process(target=task) # 耗时56s,大部分时间浪费在创建进程上 # p = Thread(target=task) # 耗时2.15秒 p_list.append(p) p.start() for p in p_list: p.join() end_time = time.time() print('主done:<%s>' % (end_time-start_time))

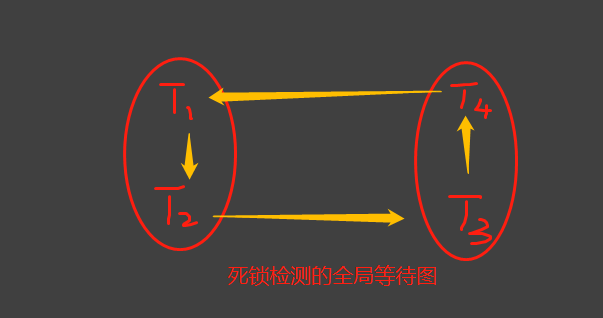
6、死锁

from threading import Thread, Lock import time lockA = Lock() lockB = Lock() class Mythread(Thread): def run(self): self.task_a() self.task_b() def task_a(self): lockA.acquire() print('%s 拿到A锁1' % self.name) lockB.acquire() print('%s 拿到B锁1' % self.name) lockB.release() lockA.release() def task_b(self): lockB.acquire() print('%s 拿到B锁' % self.name) lockA.acquire() print('%s 拿到A锁' % self.name) lockA.release() lockB.release() if __name__ == '__main__': for i in range(10): t = Mythread() t.start()


7、递归锁
#一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止




from threading import Thread, RLock import time lockA = lockB = RLock() # 递归锁 # 递归锁可以连续acquire多次,每acquire一次计数器+1,只有计数器为0时,才能被抢到 class Mythread(Thread): def run(self): self.task_a() self.task_b() def task_a(self): lockA.acquire() print('%s 拿到A锁1' % self.name) lockB.acquire() print('%s 拿到B锁1' % self.name) lockB.release() lockA.release() def task_b(self): lockB.acquire() print('%s 拿到B锁' % self.name) lockA.acquire() print('%s 拿到A锁' % self.name) lockA.release() lockB.release() if __name__ == '__main__': for i in range(10): t = Mythread() t.start()
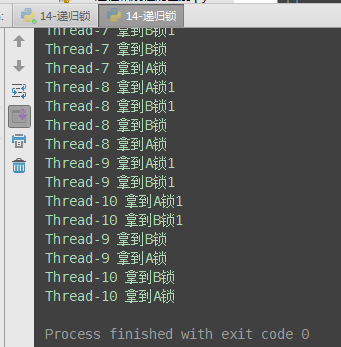
8、信号量