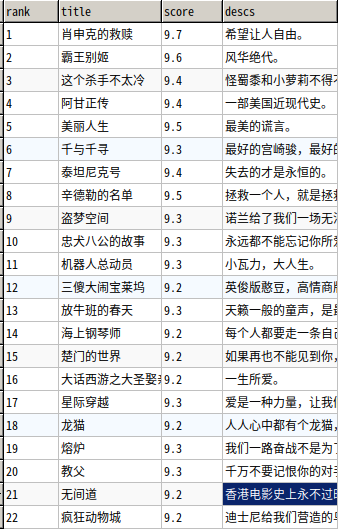
# -*- coding:utf-8 -*-
"""获取时光影评电影"""
import requests
from bs4 import BeautifulSoup
from datetime import datetime,timedelta
import pymysql
#用来操作数据库的类
class MySqlCommand(object):
#类的初始化
def __init__(self):
self.host = "127.0.0.1"
self.port = 3306 #端口号
self.user = "root" #用户名
self.password = "" #密码
self.db = "" #库
self.table = "" #表
#连接数据库
def connectMysql(self):
try:
self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,
passwd=self.password,db=self.db,charset='utf8')
self.cursor = self.conn.cursor()
return self.cursor,self.conn
except:
print('connect mysql error.')
#获取指定开始排行的电影url
def get_url(root_url,start):
return root_url+"?start="+str(start)+"&"
def get_review(page_url):
"""获取电影相关的信息"""
cursor,db = MySqlCommand().connectMysql()
#creat_table = """CREATTE TABLE douban(id INT (11) NOT NULL AUTO_INCREMENT PRIMARY KEY,rank VARCHAR(128),title VARCHAR(128),score VARCHAR(128),descs VARCHAR(128))"""
creat_table =("CREATE TABLE douban("
"rank varchar(255),"
"title varchar(255),"
"score varchar(255),"
"descs varchar(255))")
cursor.execute("DROP TABLE IF EXISTS douban")
cursor.execute(creat_table)
movies_list = []
reponse = requests.get(page_url)
soup =BeautifulSoup(reponse.text,'lxml')
soup = soup.find("ol","grid_view")
dict ={}
for tag_li in soup.find_all("li"):
dict = {}
dict['rank'] = tag_li.find("em").string
dict['title'] = tag_li.find_all("span","title")[0].string
dict['score'] = tag_li.find("span","rating_num").string
if tag_li.find("span","inq"):
dict['desc'] =tag_li.find("span","inq").string
else:
dict['desc'] = '无评词'
cursor.execute("INSERT INTO douban(rank,title,score,descs)
VALUES(%s,%s,%s,%s)",
(dict['rank'],dict['title'],dict['score'],dict['desc']))
db.commit()
db.close()
#movies_list.append(dict)
#return movies_list
if __name__ == '__main__':
root_url = "https://movie.douban.com/top250"
start =0
movies_list =get_review(get_url(root_url,start))
# for movies in movies_list:
# print(movies)
结果: