一、 神经网络引入
我们将从计算机视觉直观的问题入手,提出引入非线性分类器的必要性。首先,我们希望计算机能够识别图片中的车。显然,这个问题对于计算机来说是很困难的,因为它只能看到像素点的数值。
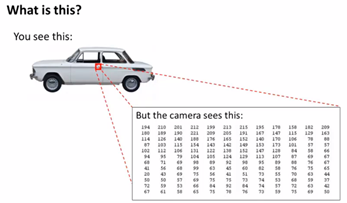
应用机器学习,我们需要做的就是提供大量带标签的图片作为训练集,有的图片是一辆车,有的图片不是一辆车,最终我们希望我们给出一张图片,计算机可以准确地告诉我们这是不是一辆车。

显然这需要一个非线性分类模型。相对于Logistic模型,神经网络被证明是更好的非线性分类模型。
1. 神经元结构
下面我们来看单独的一个神经元:
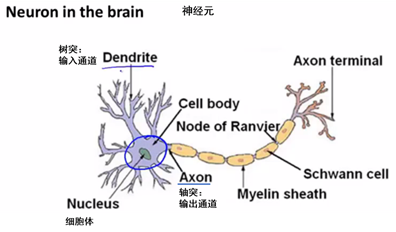
这是我们人体的神经元结构,神经元是一个基本的信息计算单元,神经元之间输出与输入通道依次相互连接完成信息的传递,我们在计算机中模拟这种复杂的结构与信息传递机制,下面是一个非常简单的人工神经网络模型的例子。

这是一个单个神经元,在绘制神经网络时,通常只绘制输入节点![]() ,必要时增加一个额外的节点
,必要时增加一个额外的节点![]() ,这个
,这个![]() 节点有时被称作偏置单元或偏置神经元。另外,在神经网络描述中,我们使用术语“激活函数”(表示为
节点有时被称作偏置单元或偏置神经元。另外,在神经网络描述中,我们使用术语“激活函数”(表示为![]() )、“权重”,代替“模型”(Sigmoid)和“参数”(theta)。神经网络实际上就是多个神经元连接在一起的集合。
)、“权重”,代替“模型”(Sigmoid)和“参数”(theta)。神经网络实际上就是多个神经元连接在一起的集合。
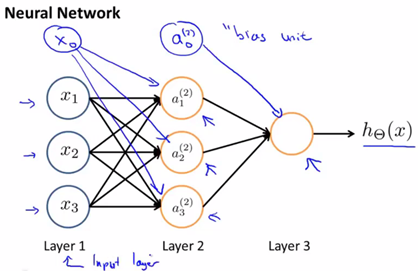
第一层称为输入层,最后一层称为输出层,因为它输出假设(hyoptheses)的最终计算结果,中间层称为隐藏层因为在监督学习中,我们看不到中间层的输出与输出是什么。
强调一些重要参数:

![]() :第 j 层的第 i 个神经元或单元的激活项
:第 j 层的第 i 个神经元或单元的激活项
![]() :权重(矩阵),它控制从第 j 层到第 j+1 层的权重 map。
:权重(矩阵),它控制从第 j 层到第 j+1 层的权重 map。
![]() 控制着从三个输入单元到三个隐藏单元的映射参数矩阵,
控制着从三个输入单元到三个隐藏单元的映射参数矩阵,![]() 。如果一个神经网络在第 j 层有
。如果一个神经网络在第 j 层有![]() 个单元,在 j+1 层有
个单元,在 j+1 层有![]() 个单元,则
个单元,则![]() 的维度为
的维度为![]() 。
。
2. 矢量化
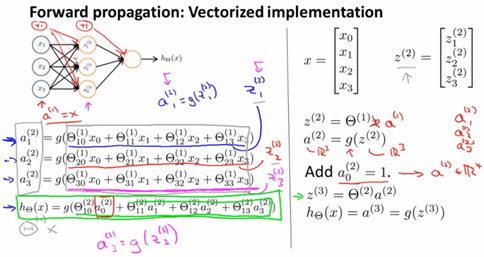
对应图中所做标记:
- 我们给出定义:
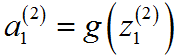 其中上标 (2) 代表,它们与神经网络的第二层相关,此处 z 表达式为输入值的加权线性组合。
其中上标 (2) 代表,它们与神经网络的第二层相关,此处 z 表达式为输入值的加权线性组合。 - 如图右,将
 向量化表示后,我们可以将
向量化表示后,我们可以将 表示成
表示成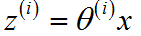 ,在此基础上对
,在此基础上对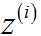 的每个元素求
的每个元素求 函数值得到
函数值得到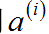 ,所以它们的维度相同。
,所以它们的维度相同。 - 将表示成
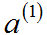 。
。 - 现在我们经计算得到了
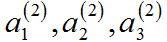 的值,还需添加偏置单元
的值,还需添加偏置单元 。
。 - 特别地
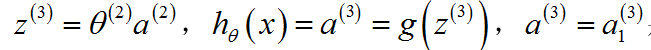 是输出层唯一的单元,是一个实数。
是输出层唯一的单元,是一个实数。
这个计算![]() 的过程,被称为“向前传播”,因为我们从输入单元的激活项开始,进行向前传播给隐藏层,计算隐藏层的激活项,继续向前传播并计算输出层的激活项。这种从输入层到隐藏层再到输出层的过程叫做向前传播。
的过程,被称为“向前传播”,因为我们从输入单元的激活项开始,进行向前传播给隐藏层,计算隐藏层的激活项,继续向前传播并计算输出层的激活项。这种从输入层到隐藏层再到输出层的过程叫做向前传播。
4. 例:用神经网络进行简单计算:
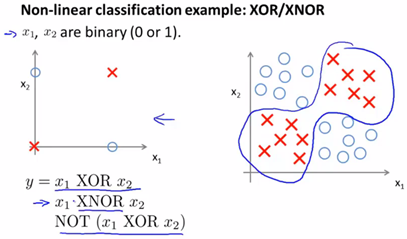
我们希望学习一个非线性的决策边界来区分正负样本,神经网络将怎样做到呢?我们将右侧复杂的数据简化为左侧仅有四个样本的情况。我们需要计算目标函数![]() 或者
或者![]() (前者取反)。
(前者取反)。
![]() ,当两个式子中恰好有一个为真时,表达式为真。
,当两个式子中恰好有一个为真时,表达式为真。
![]() ,当两个式子同时为真或同时为假时,表达式为真。
,当两个式子同时为真或同时为假时,表达式为真。
我们该建立一个怎样的神经网络来你和这样的训练集呢?
为了能拟合XNOR运算,我们从能够拟合AND运算的网络入手,首先我们划出一个简单的神经网络模型,赋值权重,如下图左侧。
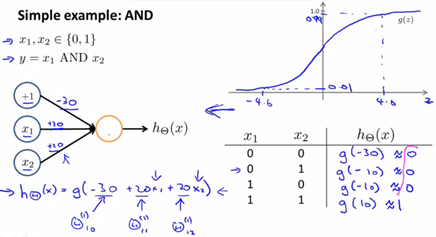
将右下方表格所列出![]() 的值一一带入,对应 g(z) 图像,得到假设函数的值。观察发现,
的值一一带入,对应 g(z) 图像,得到假设函数的值。观察发现,![]() 。通过写出上图右下这样的真值表,我们就能看到神经网络所计算的逻辑函数取值情况。下面的过程实现了逻辑或运算:
。通过写出上图右下这样的真值表,我们就能看到神经网络所计算的逻辑函数取值情况。下面的过程实现了逻辑或运算:

逻辑非运算:
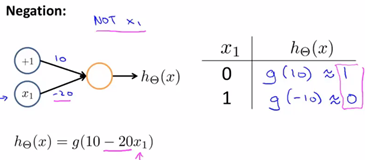
这三个例子为我们展示了一个单个神经元的神经网络,是如何实现计算单一的逻辑操作,如![]() 。下面我们将看到一个多层的神经网络模型是如何被用来计算更复杂的函数的。
。下面我们将看到一个多层的神经网络模型是如何被用来计算更复杂的函数的。
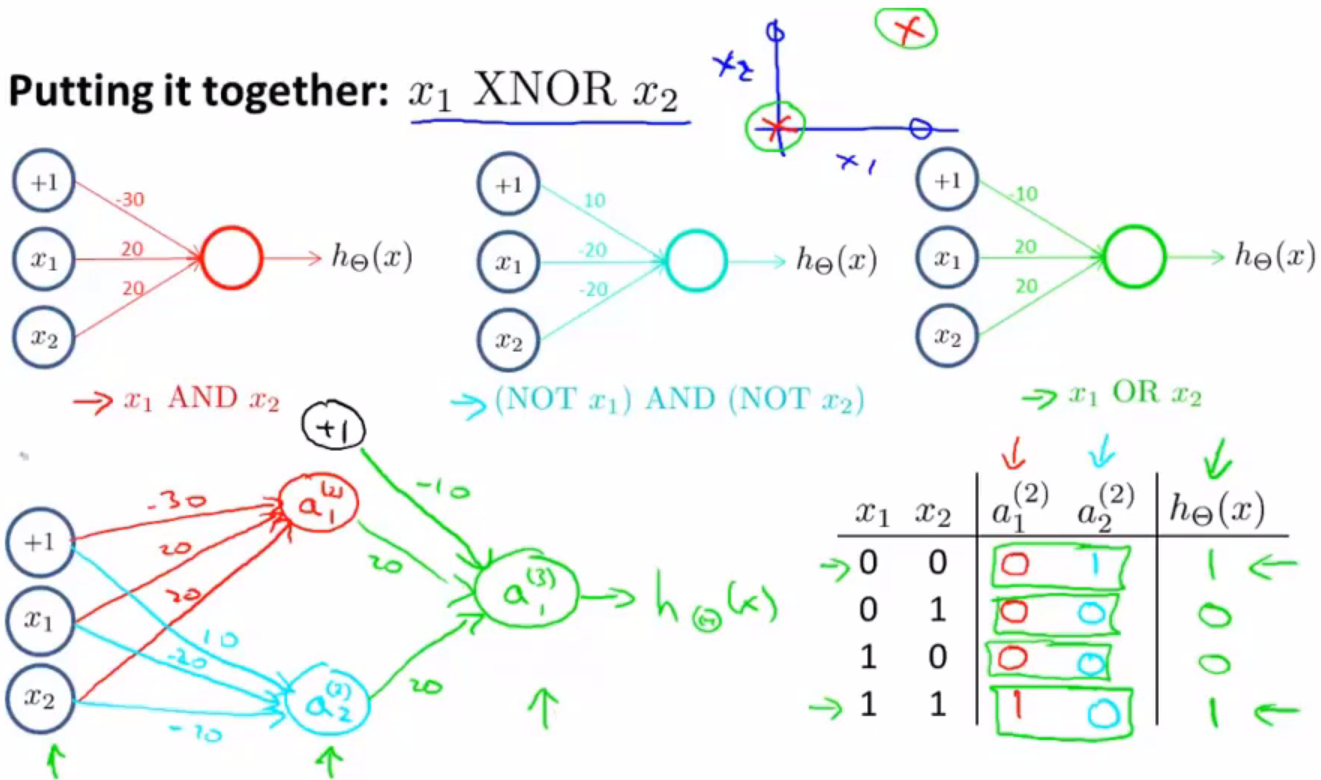
最后根据真值表我们可以得出,这个神经网络最终会得到一个非线性的决策边界,用以计算XNOR函数。
二、实践:多分类问题:
如果我们需要识别一张图片的内容是一个人、一辆小汽车、一个摩托还是一辆货车,我们可能会建立如下模型,其中输出层组成一个四维向量,由值为1的元素位置可以看出分类结果。
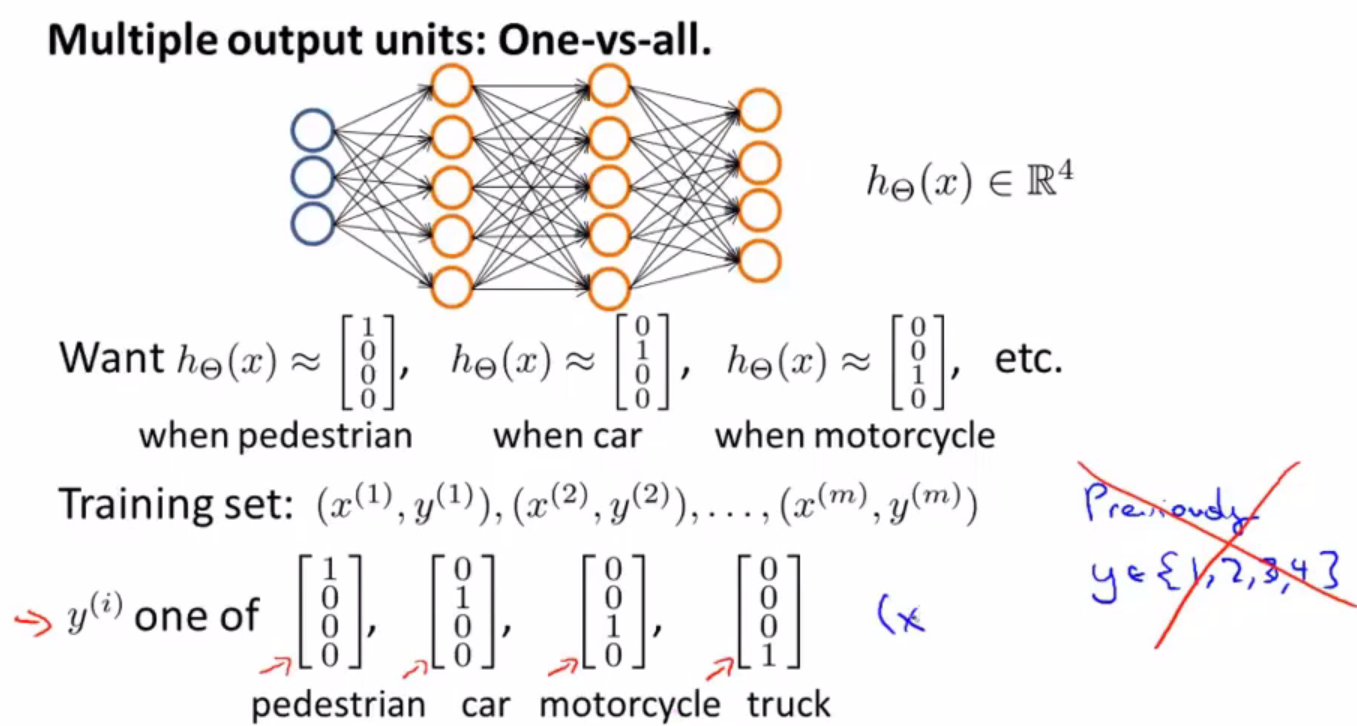
至此我们对于神经网络有了基本的一些了解,然而感觉在知识的衔接和神经网络发展的历程还不是很清晰,下面的博文中有着特别好的讲解,使我们加深理解。
https://www.cnblogs.com/subconscious/p/5058741.html
编程作业:多元分类与神经网络
用Logistic回归和神经网络识别手写数字(0-9)
训练集为5000个20 x 20-pixel 的手写数字,读入格式化后的数据(矩阵X),每一行为一个图片的400个像素。结合课堂作业一章详细的英文讲解以及,文件资料中对每一个函数完成功能的英文注释,我们可以较容易地完成代码编写。首先看一下需要完成的四个函数:
lrCostFunction.m Regularized logistic regression
oneVsAll.m One-vs-all classifier training
predictOneVsAll.m One-vs-all classifier prediction
predict.m Neural network prediction function
我们先来可以看一下部分训练集长什么样子:

首先,第一个函数lrCostFunction.m 文件看着无比眼熟,没错这个和上一篇的costfunctionReg.m 是一模一样的。计算代价函数和梯度,使用向量化的思想简化计算,包含正则化项。
function [J, grad] = lrCostFunction(theta, X, y, lambda) %LRCOSTFUNCTION Compute cost and gradient for logistic regression with %regularization % J = LRCOSTFUNCTION(theta, X, y, lambda) computes the cost of using % theta as the parameter for regularized logistic regression and the % gradient of the cost w.r.t. to the parameters. m = length(y); % number of training examples J = 0; grad = zeros(size(theta)); J = 1/m * (-y' * log(sigmoid(X*theta)) - (1 - y') * log(1 - sigmoid(X * theta))) + lambda/2/m*sum(theta(2:end).^2); grad(1,:) = 1/m * (X(:, 1)' * (sigmoid(X*theta) - y)); grad(2:size(theta), :) = 1/m * (X(:, 2:size(theta))' * (sigmoid(X*theta) - y))... + lambda/m*theta(2:size(theta), :); grad = grad(:); end
在Logistic课程笔记中,我们了解到一对多问题的基本概念就是把多个分类转化为二元分类的问题。分类的过程实际上是求出该样本属于每一个类的概率,而函数oneVsAll.m 的作用就是求出这10次预测产生10组 值,每一组作为一行,以矩阵的形式返回。
function [all_theta] = oneVsAll(X, y, num_labels, lambda) m = size(X, 1); n = size(X, 2); all_theta = zeros(num_labels, n + 1); X = [ones(m, 1) X]; % ======================================== % Instructions: You should complete the following code to train num_labels % logistic regression classifiers with regularization % parameter lambda. % % Hint: theta(:) will return a column vector. % % Hint: You can use y == c to obtain a vector of 1's and 0's that tell you % whether the ground truth is true/false for this class % ========================================= options = optimset('GradObj', 'on', 'MaxIter', 400); for i = 1 : num_labels [all_theta(i,:), J, exit_flag] = ... fminunc(@(t)(lrCostFunction(t, X, (y==i), lambda)), all_theta(i,:)', options); end end
有了这些 值,我们就有了训练好的分类器,接下来可以预测一个图片是什么数字了。我们可以先分别算出将该图片判断为10类中每一类的概率(用sigmoid函数计算概率),取最大值对应的类别作为判别结果。
function p = predictOneVsAll(all_theta, X) m = size(X, 1); num_labels = size(all_theta, 1); p = zeros(size(X, 1), 1); X = [ones(m, 1) X]; [M,p]=max(sigmoid(X * all_theta'),[],2);%在第2维方向上取最大值,结果/每行最大值的列位置。 end
运行ex3.m最终得到训练集预测准确率为96.46%。
%ex3.m partof input_layer_size = 400; % 20x20 Input Images of Digits num_labels = 10; % 10 labels, from 1 to 10 % (note that we have mapped "0" to label 10) %% =========== Part 1: Loading and Visualizing Data ============= % Load Training Data load('ex3data1.mat'); % training data stored in arrays X, y m = size(X, 1); %% ============ Part 2b: One-vs-All Training ============ fprintf(' Training One-vs-All Logistic Regression... ') lambda = 0.1; [all_theta] = oneVsAll(X, y, num_labels, lambda); %% ================ Part 3: Predict for One-Vs-All ================ pred = predictOneVsAll(all_theta, X); fprintf(' Training Set Accuracy: %f ', mean(double(pred == y)) * 100);
下一个部分就是将刚刚学到的多元分类运用到神经网络中啦!主要工作是建立一个三层的神经网络,而且作业里已经有了Theta1 和 Theta2, 分别是 25*401 和 10*26 的矩阵(Theta矩阵的维度为 。先来看一下我们需要建立的三层神经网络模型:
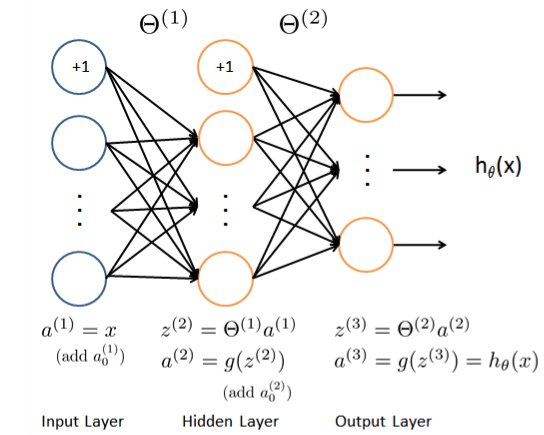
根据图示。结合上面矢量化部分所讲的计算过程,完成predict.m函数的功能,注意添加偏置单元和矢量化过程。
function p = predict(Theta1, Theta2, X) %PREDICT Predict the label of an input given a trained neural network % p = PREDICT(Theta1, Theta2, X) outputs the predicted label of X given the % trained weights of a neural network (Theta1, Theta2) m = size(X, 1); num_labels = size(Theta2, 1); p = zeros(size(X, 1), 1); a1 = [ones(m, 1) X]; a2 = [ones(m, 1) sigmoid(a1*Theta1')]; [x, p] = max(sigmoid(a2*Theta2'), [], 2); end
结果 Training Set Accuracy: 97.520000
最后一段代码我们可以拿出每一张图片来看程序将其识别,就还挺有趣的。
% To give you an idea of the network's output, you can also run % through the examples one at the a time to see what it is predicting. % Randomly permute examples rp = randperm(m); for i = 1:m % Display fprintf(' Displaying Example Image '); displayData(X(rp(i), :)); pred = predict(Theta1, Theta2, X(rp(i),:)); fprintf(' Neural Network Prediction: %d (digit %d) ', pred, mod(pred, 10)); % Pause with quit option s = input('Paused - press enter to continue, q to exit:','s'); if s == 'q' break end end
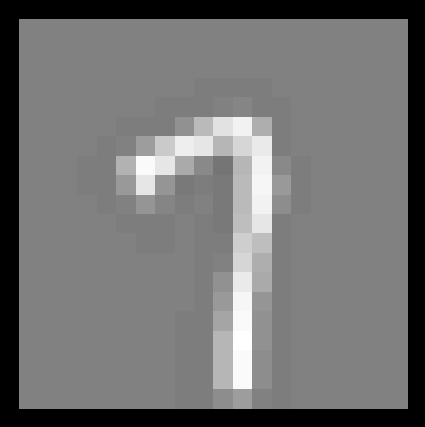

Neural Network Prediction: 7 (digit 7) Neural Network Prediction: 6 (digit 6)
总结:学过本章的课程,通过自己简单的动手实践,对神经网络的基本结构、完成其功能的工作方式有了初步的认识(即拿到权重矩阵如何去预测样本),在下一章会进一步去学习如何去进行神经网络的训练得到权重矩阵。