freopen stdout 真的更快?
在一次数独作业中,我发现大部分同学提交的代码中都使用 freopen 来将 stdout 重新指向目标文件进行文件输出操作。我感到十分好奇,关于 freopen 我几乎从未用过,也很少在其它地方看到别人使用,也就是说至少我的认知里该函数不是个常用函数。再来点数据支持:
- 关于
fopen在 Google 中的搜索结果有636万条
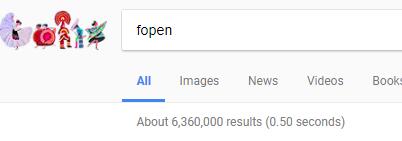
- 关于
freopen在 Google 中的搜索结果有35.7万条,少了一个数量级!
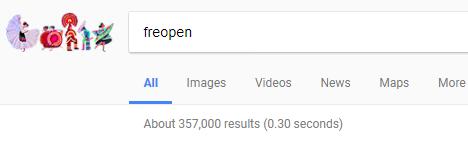
所以我想同学们是不是从哪里道听途说了这种用法的好处,或者在某些环境下先入为主而习惯使用 freopen 。我尝试在班级群中发出疑问,果然两个原因都有:
助教 L 说:
我看部分同学的说法是:非常快
能够把文件输出的速度提升到极致
同学 H 说:
以前我记得做c++作业的时候,有这样的,然后我不懂怎么弄,大神就教我可以这样输出到文件,至于为什么。。。我去他宿舍问一下
同学 C 说:
。。。noip都用freopen
关于习惯问题,这里不做展开。只是简单提一下,freopen 重定向 stdout 会让一个普通程序的输出变得麻烦,比如同时读写若干个文件,同时要输出到 console 等。
关于性能问题,这个道听途说就十分不妥,都是做技术的,这样的小问题很容易动手验证,那我们就干一小票试试。
测试环境:Windows 10 / Visual Studio 2015
- 首先,来个函数,对一个连续写入操作计时:
clock_t do_write(FILE* fp, char* data, size_t len) {
// The clock() function returns an approximation of processor time used by the program.
// The value returned is the CPU time used so far as a clock_t;
// to get the number of seconds used, divide by CLOCKS_PER_SEC.
clock_t clock_begin, clock_end;
clock_begin = clock();
for (int i = 0; i < 1000; ++i) {
auto n = fwrite(data, len, 1, fp);
assert(n == 1);
}
fflush(fp);
clock_end = clock();
return clock_end - clock_begin;
}
关于 clock 计时请看以上代码注释
- 然后我们分别以
freopen,fopen打开文件,并且写入 1000MB 看看并输出耗时:
int main() {
auto data = new char[1048576]; // 1MB
// initialize the buffer
for (int i = 0; i < 1048576; ++i)
data[i] = i;
clock_t elapsed;
auto fp_reopen = freopen("data_freopen.bin", "wb", stdout);
assert(fp_reopen != nullptr);
elapsed = do_write(fp_reopen, data, 1048576);
// redirect stdout to console
#ifdef _WIN32
freopen("CONOUT$", "w", stdout);
#else
freopen("/dev/tty", "w", stdout);
#endif
printf("write with freopen clocks elapsed: %zu
", elapsed);
auto fp = fopen("data_fopen.bin", "wb");
assert(fp != nullptr);
elapsed = do_write(fp, data, 1048576);
fclose(fp);
printf("write with fopen clocks elapsed: %zu
", elapsed);
delete[] data;
}
测试输出:
write with freopen clocks elapsed: 1644
write with fopen clocks elapsed: 8855
好家伙,果然快很多!但是!为!什!么!?
难道是两种方式打开文件的缓存机制不同?
- 那行,让它们使用同样的缓存:
setvbuf 可以办到!如果不了解,请看这里:http://en.cppreference.com/w/c/io/setvbuf
auto cache = new char[512 * 1024];
auto fp_reopen = freopen("data_freopen.bin", "wb", stdout);
assert(fp_reopen != nullptr);
setvbuf(fp_reopen, cache, _IOFBF, 512 * 1024);
...
auto fp = fopen("data_fopen.bin", "wb");
assert(fp != nullptr);
setvbuf(fp, cache, _IOFBF, 512 * 1024);
...
}
测试输出:
write with freopen clocks elapsed: 1761
write with fopen clocks elapsed: 9146
依!然!如!此!呆坐中。。。
- 连续写入大量数据
- 设置相同的缓存机制
还能有什么影响呢?
- runtime library
- 操作系统
- 文件系统
- 磁盘硬件
想想我们拷贝大文件的现象,一般都是起步很快,然后会下降到一个较稳定的值上下徘徊,这个原因比较明显,系统及硬件都提供了一定的缓存。
- 刚开始缓存空闲,数据都飞快写入缓存
- 同时缓存也不停地在刷入磁盘
- 因为连续写入大量数据,磁盘本身很慢,缓存逐渐被填满,这时候写入缓存也需要等待(现象就是写入速度下降到刷磁盘的速度)
那行了,我们测试是写2个文件,一个先一个后,并且是连续操作,也就是说先写的文件优先享受了缓存带来的好处,后写的文件没有了这个优势。思考完,做个验证:
// 先测 fopen
auto fp = fopen("data_fopen.bin", "wb");
assert(fp != nullptr);
setvbuf(fp, cache, _IOFBF, 512 * 1024);
elapsed = do_write(fp, data, 1048576);
fclose(fp);
printf("write with fopen clocks elapsed: %zu
", elapsed);
// 再测 freopen
auto fp_reopen = freopen("data_freopen.bin", "wb", stdout);
assert(fp_reopen != nullptr);
setvbuf(fp_reopen, cache, _IOFBF, 512 * 1024);
elapsed = do_write(fp_reopen, data, 1048576);
// redirect stdout to console
#ifdef _WIN32
freopen("CONOUT$", "w", stdout);
#else
freopen("/dev/tty", "w", stdout);
#endif
printf("write with freopen clocks elapsed: %zu
", elapsed);
测试输出:
write with fopen clocks elapsed: 1561
write with freopen clocks elapsed: 9267
哈哈!答案揭晓! freopen stdout 并没有性能上的优势!
- 进一步做验证,我们依然按照
freopen,fopen的顺序来测试,但是在两次测试中间加上sleep让缓存能空闲出来。这里就不贴代码了,直接上结果:
write with freopen clocks elapsed: 2326
write with fopen clocks elapsed: 2519
结论
要动手验证!验证!验证!而不是道听途说!
Linux也做过测试,结论也一样!
参考
刘未鹏 - 遇到问题为什么应该自己动手