开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的。前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个页面抓取然后自动存到EXCEL中。今天完成了第一个页面的处理,抓取到了所有的二级链接。
要爬取初始网页:http://www.zizzs.com/zt/zzzsjz2017/###
任务:将招生简章中2017对应的二级页面的招生计划整理到EXCEL
初始目标:爬取http://www.zizzs.com/zt/zzzsjz2017/### 中招生简章2017年对应的二级链接,爬取到二级链接之后再接着往下爬取二级页面的表格,并存到EXCEL中.
我打算用BeautifulSoup来解析网页页面.
BeautifulSoup是Python中的一个HTML/XML解析器,通过定位HTML标签来格式化和组织复杂网络. 它可以很好的处理不规范标记并生成剖析树(parse tree),提供简单又常用的导航(navigating),搜索以及修改剖析树的操作.
中文文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
首先看下我要爬取的网页源码:

可以看见我要爬取的表格在图中红框圈住的页面中. 可以用BeautifulSoup的find()方法使用标签和属性定位这个表格.
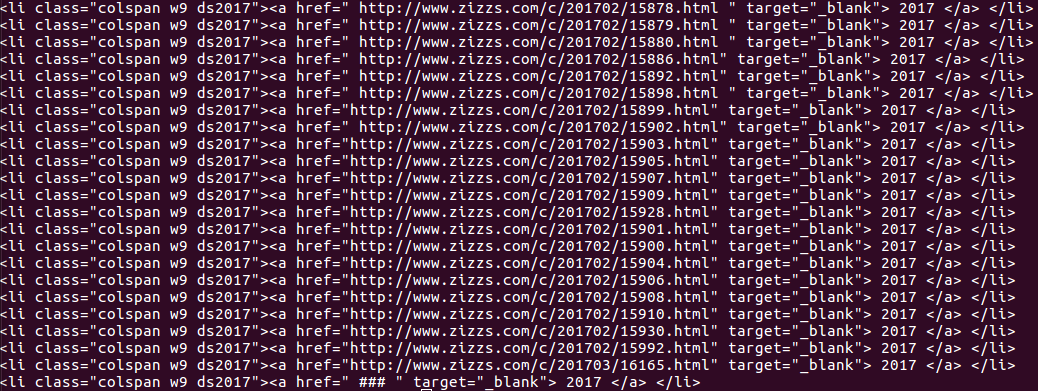
找到表格所在位置之后可以看到我要找的页面都在class="colspan w9 ds2017" 中, 借用findAll()定位这个内容.
但是print出来是整个内容,而我要提取的是href中的页面链接.
对于这个问题我使用python的正则表达式re.findall()方法来提取链接.
使用方法: re.findall(pattern, string, flags=0),第一个参数是你要查找的字符串模式可以用正则表达式设计,第二是整个字符串
要了解python字符串可以看看这篇博文.
http://blog.csdn.net/eastmount/article/details/51082253
可以观察到我要查找的字符串有些是以空格开头的,有些不是, 我的正则表达式为:
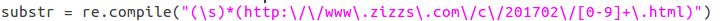
最后成功抓取到自己想要的链接:
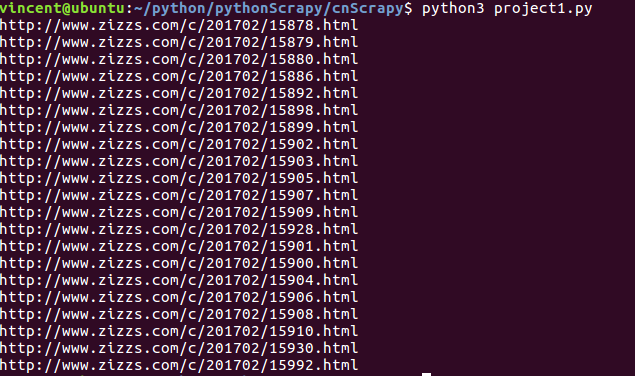
后面就是用这些链接去抓取表格内容的各个学校的招生信息了。
贴上源码:
# _*_ coding: UTF-8 _*_ from urllib import request from bs4 import BeautifulSoup import re url = 'http://www.zizzs.com/zt/zzzsjz2017/###' # 这一段是将python urllib伪装成chrome 浏览器,防止被服务器拒绝,原因在我另一篇文章python文章总结里面
def getHTML(url): headers = {'User-Agent':'User-Agent:Mozilla/5.0(Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} req = request.Request(url,headers = headers) return request.urlopen(req) html = getHTML(url) #得到BeautifulSoup对象 bsObj = BeautifulSoup(html,'lxml') foundLinks = [] #成功找到初始页面的所有二级链接 substr = re.compile("(s)*(http://www.zizzs.com/c/201702/[0-9]+.html)") for link in bsObj.find("div",{"id":"tab2_content"}).findAll("",{"class":"colspan w9 ds2017"}): #print(str(link)) if len(re.findall(substr,str(link))) != 0: foundLinks.append(re.findall(substr,str(link))[0][1]) print(foundLinks)
整个程序虽然比较简单,但是自己对BeautifulSoup和正则表达式还不是很熟悉,还是调试了很久.