一、正则表达式特殊符号:

二、grep的用法
grep [-A|B|a|c|i|n|v] [--color=auto] '搜索字串' filename
-A ===> after缩写,后面接数字,除了列出该列外,还列出后续的n列
-B ===> before缩写,后面接数字,除了列出该列外,还列出前面的n列
-a ===> 将二进制binary文件以text文件的方式查找数据
-c ===> 记录找到字符串的次数
-i ===> 忽略大小写
-n ===> 输出行号
-v ===> 反向选择
--color-auto ===> 将找到的关键字用特殊颜色标注1.普通用法
eg:

2.grep配合正则表达式用法
(1)将nginx文件中所有包含大写字符的行列出来,并标明行号

3.常见符号的用法
[] ===> 集合字符
- ===> 大小写字母和数字范围
^ ===> 指定字符出现在行首 | 取反
=======================================注释========================================
注意:这里的 ^ 可能代表行首也可能代表取反,[]代表集合符号
若为 ^[*] 则代表行首,即在括号 [] 之外代表行首。
若为 [^*] 则代表取反,即在括号 [] 之内代表取反。
==================================================================================
$ ===> 指定字符出现在行尾
. ===> 任意字符
* ===> 重复字符
=======================================注释========================================
注意:*?代表还有任意多个?字符的意思,即包含0个的可能,因此若至少要求含有两个a,则必须写成这样 : aaa*
===================================================================================
{} ===> 限定重复字符
=======================================注释========================================
?{x} 代表还有连续5个或5个以上?字符
?{x,y} 代表含有x到y个?字符
在shell里{和}是有特殊含义的,因此需要加转义字符
===================================================================================(1)查找成绩单中是5的倍数的成绩
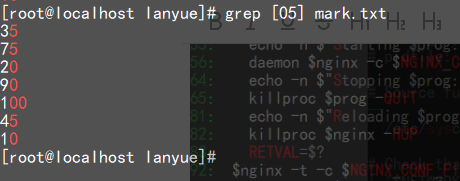
(2)将0-60的成绩输出(假设没有满分的)

(3)将成绩中不含3的成绩输出

(4)将mark文件中的空白行显示出来
grep -n '^$' mark.txt
注意 ^为行首 $为行尾,仅有行首和行尾的行即为空白行(5)将profile文件除了注释行都显示出来
grep '^[^#]' /etc/profile
注意:
第一个^是行首,第二个^是取反。
综合意思就是行首不是#的数据,即非注释数据(6)查找含有 b..h 的行,.其中 . 代表任意字符,但是一个 . 仅占用一个字符)

(7)将成绩中含有1的成绩都输出来

(8)将mark文件中还有2-5个重复字符'5'的行输出来
grep '[^5]5{2,5}[^5]' mark.txt

注意:
最前和最后的[^5]代表要查找的含有2-5个'5'的字符串前后不再是'5'
三、sed用法
sed [-nefr] 动作
-n ===> 安静模式,仅将经过sed特殊处理的那一行或者动作才列出来
-e ===> 直接在命令行进行sed的动作编辑
-f ===> 接文件,直接将sed的动作写在文件内
-r ===> sed的动作支持的是延伸型正则表达式(默认支持普通型正则表达式)
-i ===> 直接修改读取的文件内容,而不是由屏幕输出
动作:
[n1] | [n1,n2]function
a ===> 新增,后接的字符串会在当前行的下一行出现
c ===> 取代,后接的字符串会取代n1或n1-n2的内容
s ===> 取代,直接进行取代,通常搭配正则表达式
d ===> 删除
i ===> 插入,后接的字符串会在当前行的上一行出现
p ===> 打印输出,经常配合 -n
实战演练:
1.查看mark文件当前内容

2.在第10行后新增'lanyue'字符串并输出
'
3.删除第十一行的内容并输出

4.将mark第6行替换为666666输出,但是不改变源文件

5.将本机的IP地址输出(注意:这里是重点,代表着sed可以以行为单位进行处理)
(1)先来查看一下数据原始格式

(2)我们需要的仅仅是IP,所以首先要先将行过滤出来,然后再去头去尾
ifconfig | grep 'broadcast' | sed 's/.*inet//g' | sed 's/netmask.*//g'
注意:
grep 'broadcast' 为过滤出包含IP地址的行来
sed 's/.*inet//g' 为去头
sed 's/netmask.*//g' 为去尾
四、扩展正则表达式
基础的正则表达式已经足够使用了,这里可以先稍作了解就行

五、awk
相比较于sed处理整行的用法,awk更倾向于处理某行字段。
awk '条件类型1{动作1} 条件类型2{动作2} ...... 条件类型n{动作n}' filename
注意:
awk会将一行的数据分成指定段,每段都是一个变量从$1开始到$n。整行数据的变量用$0表示内置变量:

逻辑运算符:

注意:
所有的awk动作,即在{}里面内的动作,如果需要多条命令辅助时,可以通过 ; (封号)或者 Enter(回车)来隔开每个指令
实例:列出当前系统所有的账号名称,并且将UID和GID输出
cat /etc/passwd | awk 'FS=":"{print $1 " " $3" " $4}'
注意:
passwd中,每个字段以:隔开,所以为了分出每个变量需要使用FS=":"条件表达式