递归函数就是在函数体内部调用自己的函数
众所周知,递归思维在编程界影响深远,一重递归简单明了,很容易看出执行顺序,但是递归有了嵌套后,你是否还能理解其执行过程呢?
1.单重递归。
#include<iostream>
#include<string>
using namespace std;
int m = 5,n = 5;
void view(string sign,int value);
void resault();
int main(int argc,char** argv){
resault();
return 0;
}
void resault(){
view("m",m);
}
void view(string sign,int value){
if(value > 0){
cout << sign << " = " << value << endl;
value--;
view(sign,value);
}
}
这种递归是最简单的递归,也非常容易理解,故在此不多浪费口舌.
2.并列递归
#include<iostream>
#include<string>
using namespace std;
int m = 5,n = 5;
void view(string sign,int value);
void resault();
int main(int argc,char** argv){
resault();
return 0;
}
void resault(){
view("m",m);
view("n",n);
}
void view(string sign,int value){
if(value > 0){
cout << sign << " = " << value << endl;
value--;
view(sign,value);
}
}
这种递归不涉及嵌套,两个递归同等级同地位,也属于简单递归。
3.递归嵌套
#include<iostream>
#include<string>
#include<Windows.h>
using namespace std;
int m = 5,n = 5;
void view(string sign,int value);
void resault();
int main(int argc,char** argv){
resault();
return 0;
}
void resault(){
view("m",m);
}
void view(string sign,int value){
if(value > 0){
cout << sign << " = " << value << endl;
value--;
view("n",value);
view(sign,value);
}else{
return;
}
}
这种递归就属于递归的嵌套了,与前边相比,就上升了一个档次,有了一定的难度,聪明的你们知道其执行顺序的原理么?
因为递归具有一定的等级性,把每一层的参数都压在了堆栈当中,系统开销大,而且很容易造成堆栈的溢出,所以对思维有一定的要求,否则很容易造成堆栈溢出或者死循环。为什么说它具有等级性呢,因为他要调用自己本身,不一定调用一次,而每一次调用时参数会随着改变,那么,问题就来了,执行顺讯应该怎么理解,就比如上图,其实,从执行结果来看,不难看出递归确实与栈有着千丝万缕的联系,特别是存在递归嵌套的时候,就比如上图,假如我们用p表示外层递归,q来表示内层递归嵌套,如果代码是这样的(伪代码)
work(){
p(n)->work();
q(n)->work();
}
假使当n达到3以后就满足该递归出口的条件,那么这个递归函数的执行顺序就是
p1->p2->p3->q3->q2->p3->q3->q1->p2->p3->q3->q2->p3->q3
光看是看不出什么名堂来的,下面我们通过分析上一个题的执行过程来更清楚了解嵌套递归函数的执行顺序:
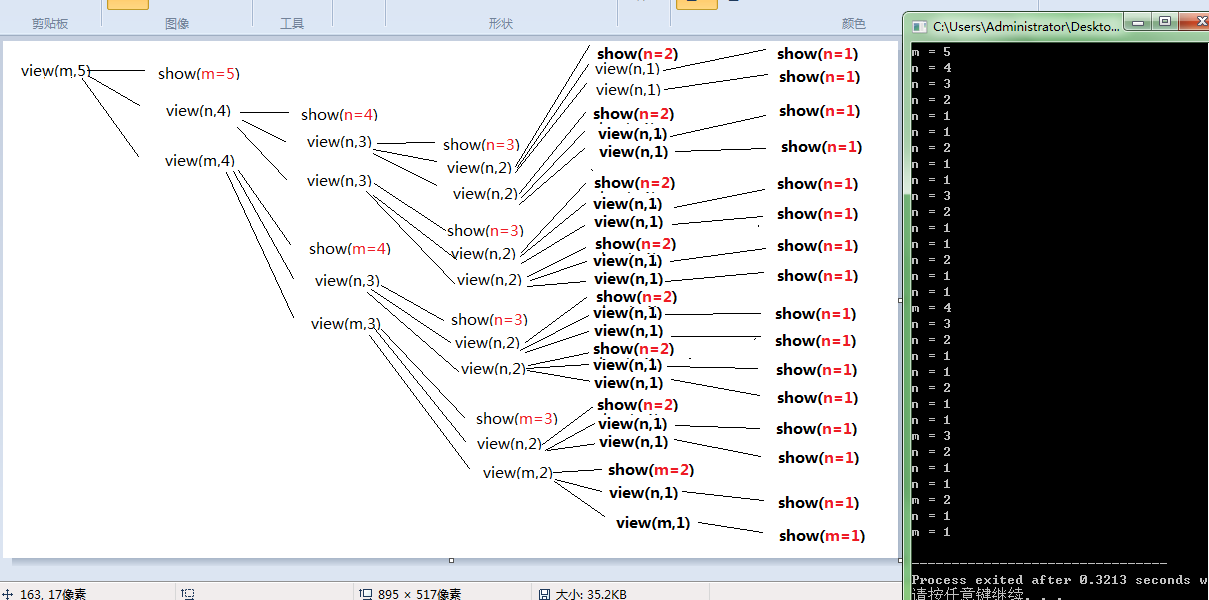
聪明的你是否看出了什么名堂?
我再帮你做点啥吧:
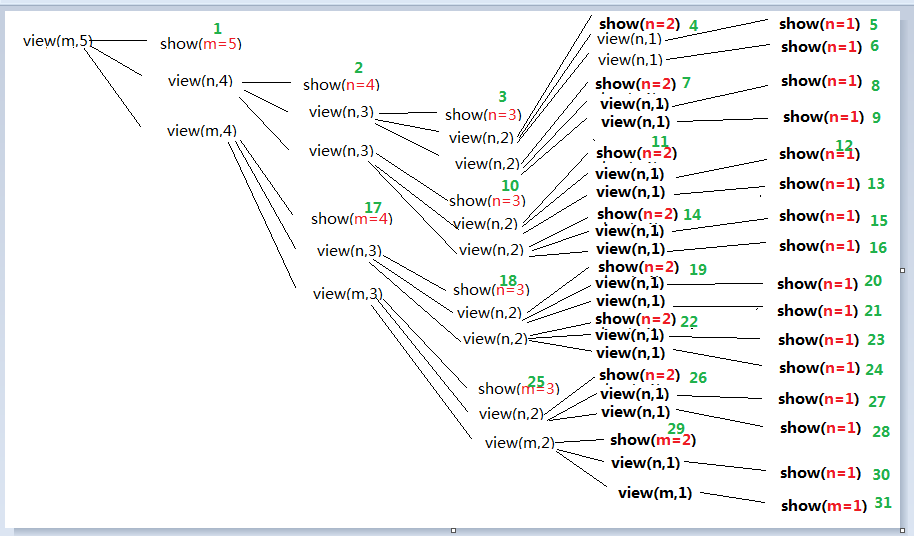
这下,你应该茅塞顿开了吧,所以你会得出结论,递归嵌套的执行顺序具有以下性质:
1.先执行当前递归函数(外层)(序号1)的第一个双重递归函数(内层)(序号2),然后并不立即执行该递归函数(序号1)的第二个双重递归函数(内层),而是执行第一个双重递归函数(序号2)的第一个三重双重包含函数(序号3),假设三重递归函数执行完毕满足递归出口,第一个三重递归函数执行完毕后,它会找与自己同等级(源自同一个双重递归函数)的下一个三重递归函数(序号4),如果没有(如果序号4不存在),返回到该三重递归函数(序号3)的来源递归函数(第一个双重递归函数)(序号2),查看第一个双重递归函数(序号2)是否存在同等级递归函数,以此类推......
2.第n重递归函数执行顺序的优先级为:
第一个n+1重递归函数 > 同等级n+1重递归函数(第二个n+1重递归函数) > 该n重递归函数的源n-1重递归函数
简单的理解为有儿子就给儿子,没儿子就给弟弟,儿子弟弟都没有就给父亲,这里充分的体现出了递归函数的原型类似于数据结构栈的原理.
可以看出,其执行顺序并不是我们人类的常规思维(类广度优先遍历),而是类深度优先遍历,即使这样,程序依然能不按递归等级变化完美的记忆不同等级,不同顺序的递归函数用到的参数及变量,只说明了一个问题,它是依据数据结构的栈的原理,不断开辟新的内存空间以满足程序需要,而不是不断改变已有内存空间的值来满足程序需要,所以递归是一种极具消耗内存资源的算法思维,所以在现实项目中,除非代码量影响过大,否则能不用递归就不用递归.