本文首发于 vivo互联网技术 微信公众号
链接:https://mp.weixin.qq.com/s/sd2oX0Z_cMY8_GvFg8pO4Q
作者:杨昆
上篇 《如何编写高质量的 JS 函数(1) -- 敲山震虎篇 》介绍了函数的执行机制,此篇将会从函数的命名、注释和鲁棒性方面,阐述如何编写高质量的 JS 函数。

(一)函数命名
一、目前前端的函数命名存在什么问题
从上图可以知道,命名和缓存是计算机科学中的两大难题。
本文要说的函数命名,虽然涉及到的范围较窄,但思想都一样,完全可以借鉴到其他的形式中。
之前阅读过代码大全中变量的相关章节,也针对性的了解过一些源码,根据我的经验总结,目前函数命名除了业界标准的问题外,还存在一些细节的问题,比如:
- 中英语言的差异性
- 不懂得从多维度去提升命名的准确性(如何从多维度去提升命名的准确性)
- 不会使用辅助工具(如何使用辅助工具)
下面进行简明扼要的分析。
二、汉语和英语的差异性
1、为什么不能用汉语方式命名呢?
汉语拼音存在多义性;汉字翻译的辅助工具还不够普及,因此不能用汉语方式命名。
2、用英语时遇到的困难
最大的难点在于语法的正确使用场景。
举个例子, react 的生命周期,如下:
- componentDidMount
- componentWillReceiveProps
- shouldComponentUpdate
很多人都会有疑问,为什么用 did 和 will 。
三、如何让命名有英语 style
举个例子:
- componentDidMount 是 react 等生命周期的钩子,但是为什么要这样命名?
- componentWillReceiveProps 为什么要这样命名?
答案就在下图:
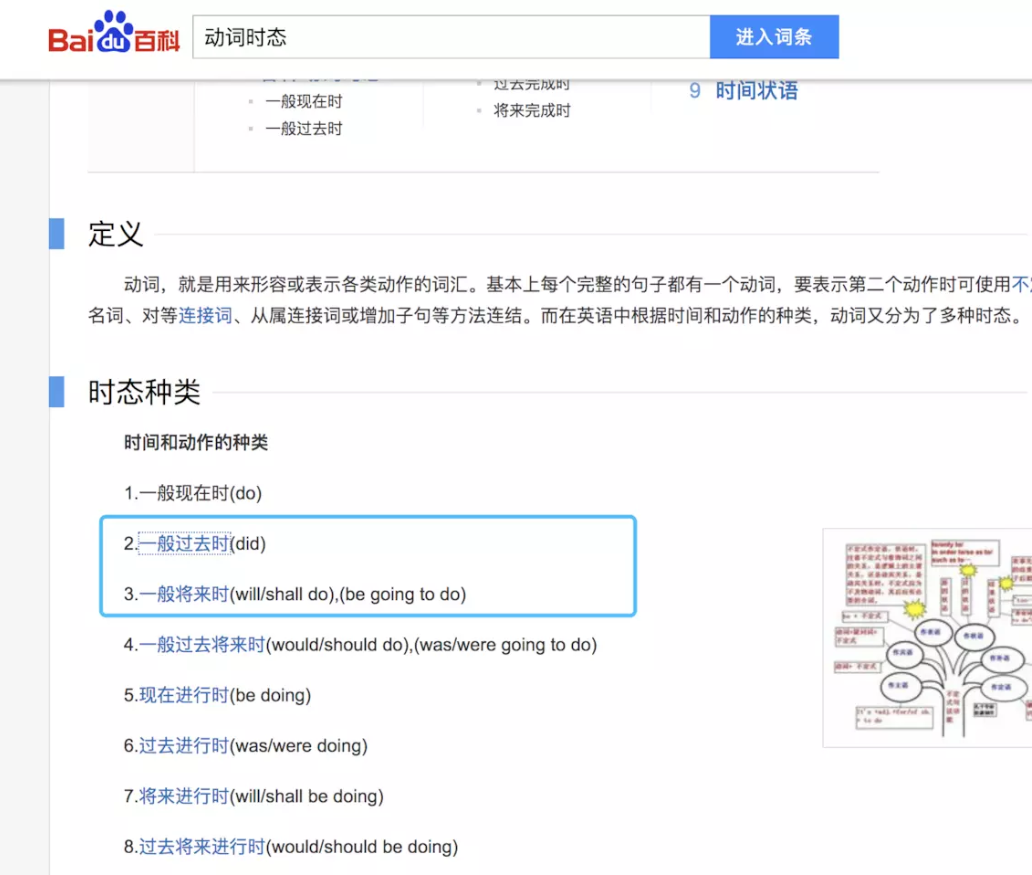
注意上图中的 did 代表一般过去时,will 代表一般将来时。
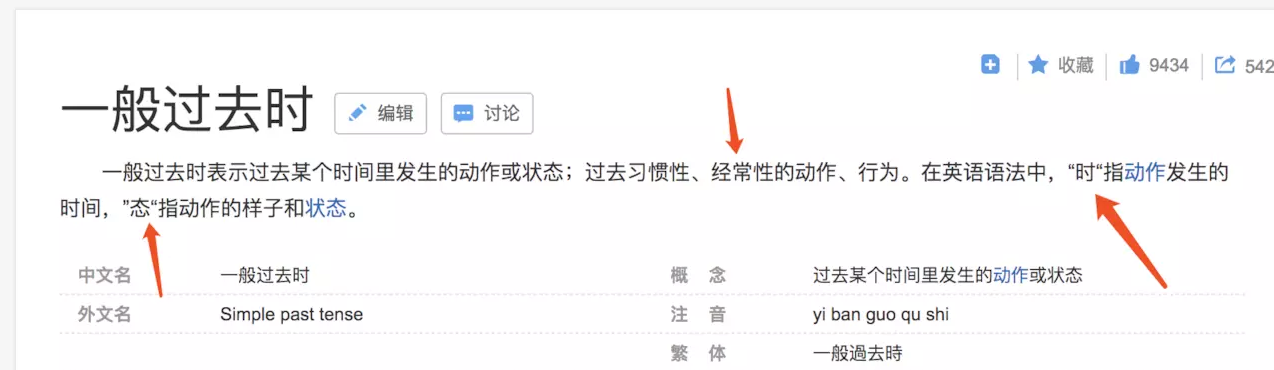
然后我们百科一般过去式和一般将来时,如图所示。
(1)一般过去时:
(2)一般将来时:
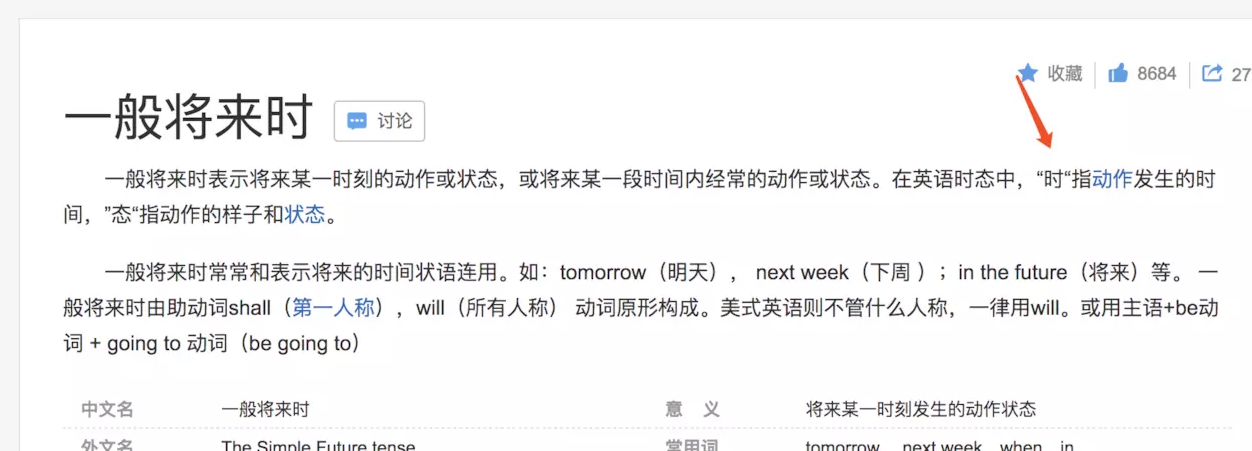
看上图的红箭头,did 表示一般过去时,时是指动作发生的时间,用在这里,突出了钩子的含义,一旦 mount 成功就执行此函数。will 同理。
四、通过函数返回结果来命名
这是个小特性,比如 shouldComponentUpdate , 为什么 should 放在最前面。
因为这个函数返回的值是布尔值。那么我们可以理解为这是个问句,通过问句的形式来告诉我们,这里具有不确定性,需要根据返回值来判断是否更新。
五、借助工具
1、借助谷歌翻译
2、借助 codelf
这是一个神器,用来搜索各种开源项目中的变量命名,以供参考。
对应名字的 VSCODE 插件也有。
六、如何避免函数命名的多义性和不可读性
ramda 源码中的一个函数,代码如下:
这个函数叫 forEachObjIndexed ,代码中看不出这个函数的命名含义,只能从从源码里面的函数注释中找答案。
函数注释如下图:
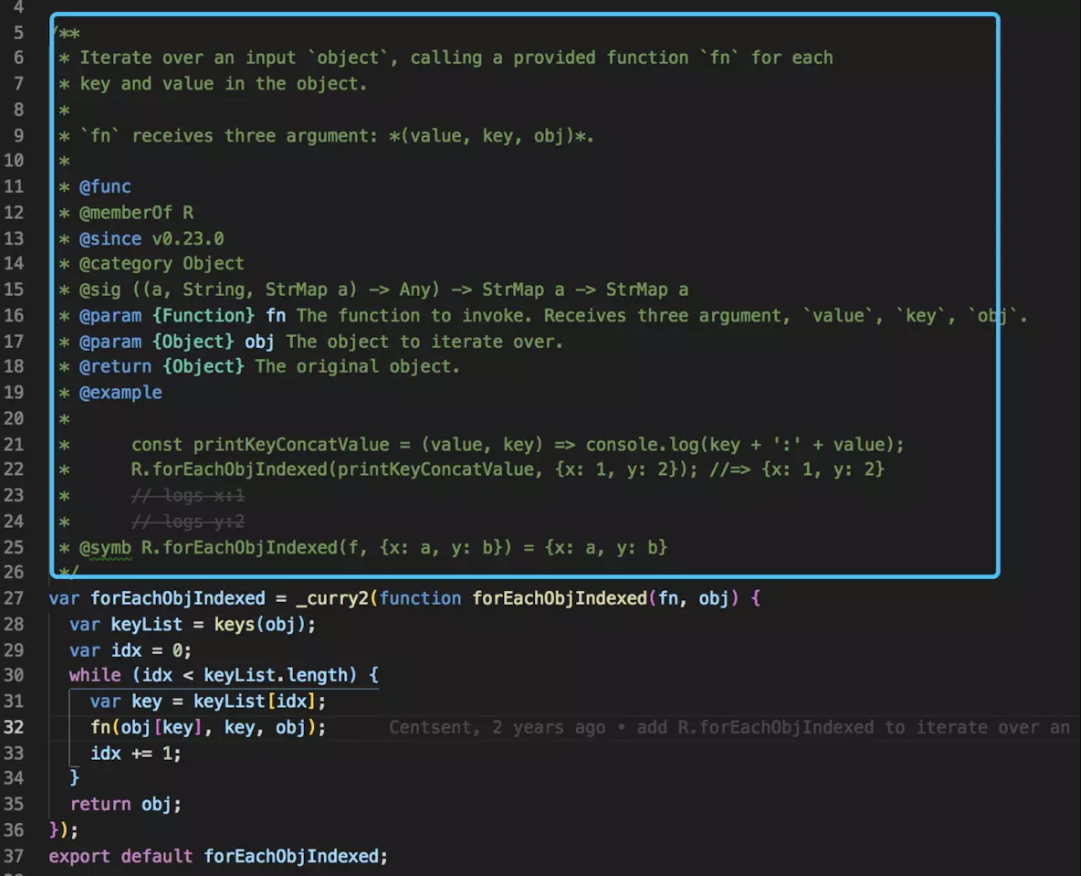
由此知道,如果函数命名存在困难,可以通过注释的方式,将函数的整体介绍和说明输出文档来解决这个问题。
七、函数命名的分类
函数命名很普遍的一个现象就是带各种前缀的函数名,如下:
- $xxx() - _xxx()
这种带各种前缀的函数名,看起来并不好看还别扭。核心原因是 JS 语言不支持私有变量,导致只能使用 _ 或者 $ 来保证相应的对外不可****见。
所以我把前端的函数命名分为两大类,如下:
第一类:不想暴露给外部访问的函数(比如只给内部使用)
第二类:暴露给外部访问的函数(各种功能方法)
而Symbol 初始化的函数命名是一种特例,代码如下:
八、总结
总结一下最佳实践:
多学习初中高中英语语法,开源项目中的函数命名没有那么难理解,通过语法的学习和借助工具,函数命名基本可以解决,如果遇到无法清晰描述所写函数的目的的命名时,请务必给函数写上良好注释,不管函数名字有多长多难懂,只要有良好的注释,那就是可以接受的一件事情。
(二)函数的注释
一、有名的npm包的一些注释风格
函数注释,一方面提高了可读性,另一方面还可以生成在线文档。
一个高质量的函数,注释少不了,但是这并不代表所有的函数都需要注释。富有富的活法,穷有穷的潇洒,重要或者复杂的函数,可以写个好注释;简单或者不重要的函数,可以不写注释或者写一个简单的注释。
那么,目前函数的注释都有哪几种方式呢?
1、egg.js 的注释风格
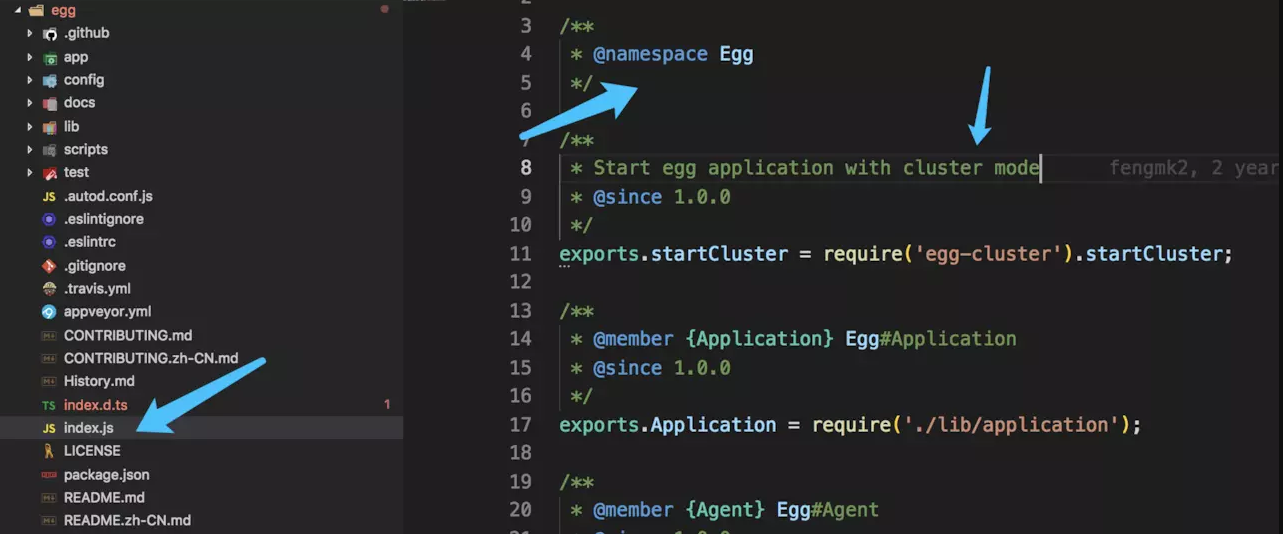
从图中可以看到 egg.js 的入口文件的注释特点是简单整洁。
继续看下图:
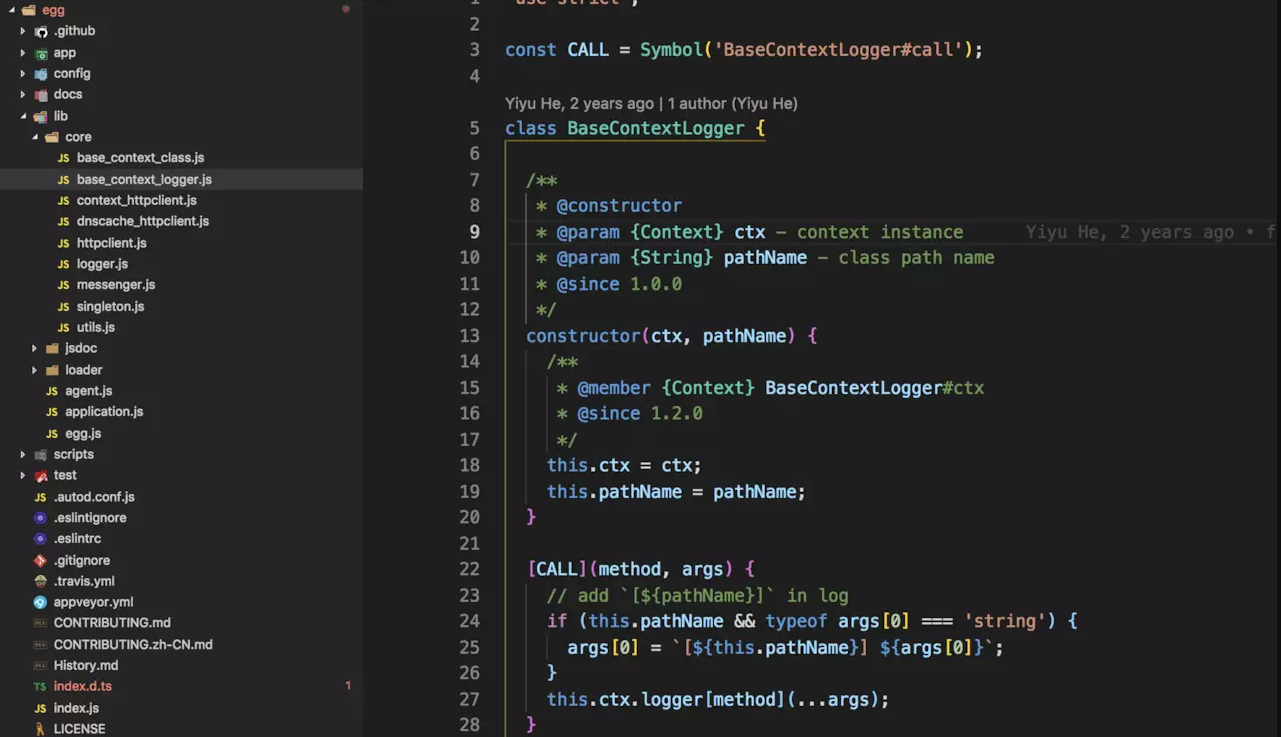
这是一个被抽象出来的基类,展示了作者 [Yiyu He] 当时写这个类的时候,其注释的风格有以下几点:
第一点:构造函数的注释规则,表达式语句的注释规则。
第二点:注释的取舍,有一些变量可以不用注释,有些要注释,不要有那种要注释就要全部注释的思想。
再看两张有趣的图片:
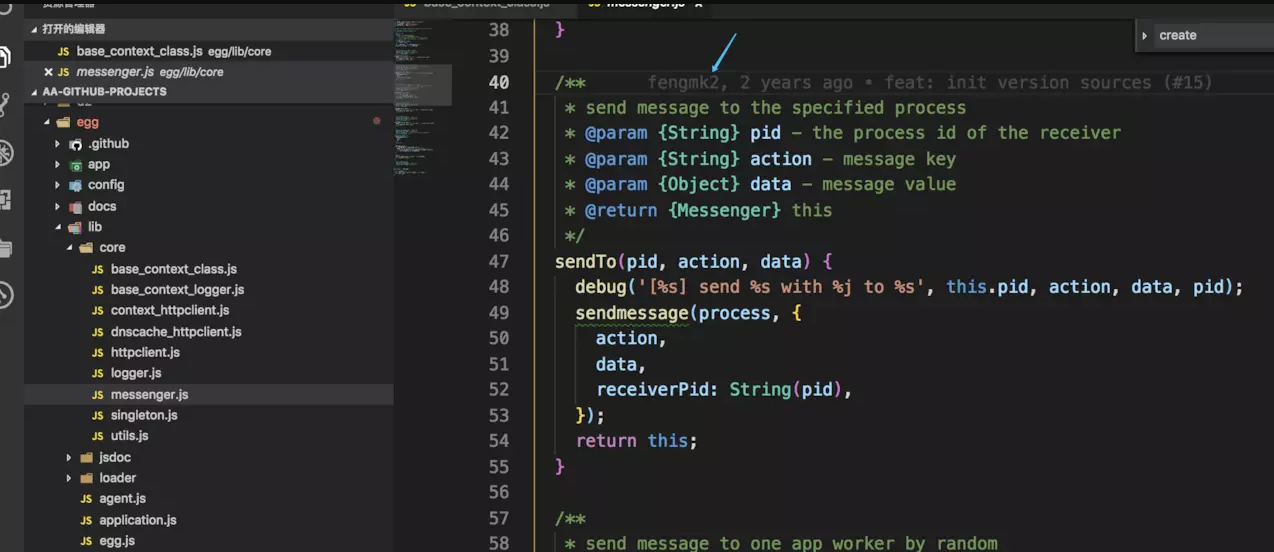
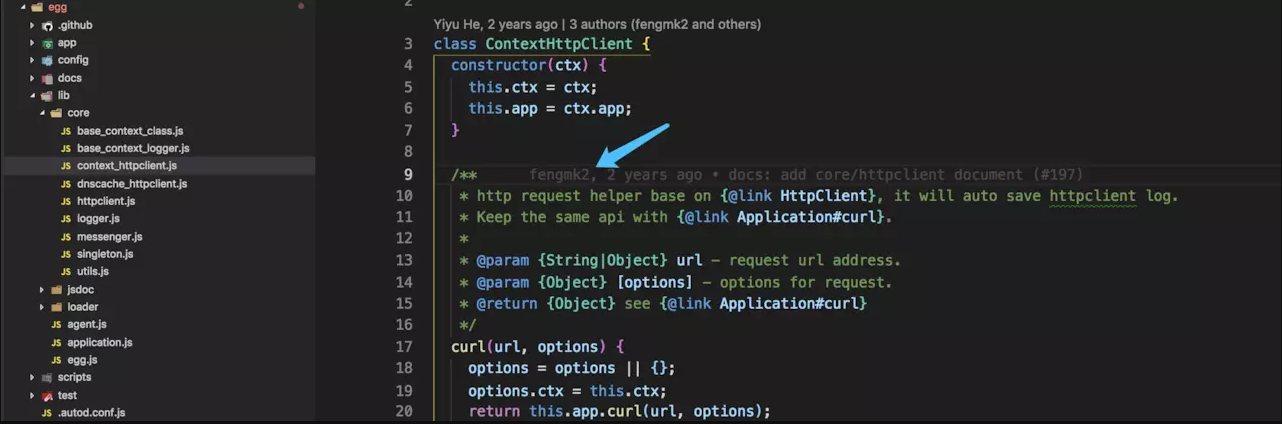
看上面两张图的箭头,指向的都是同一个作者 [fengmk2] 。他的函数注释规则,第一张图没有空格,第二种有空格,还有对返回的 this 的注释,比如很多人习惯将 this 直接注释成 Object 类型。
2、lodash.js
说到函数注释,就不能不说到 lodash.js 。由于篇幅有限,本文就不做相应介绍了,大家自行按照上面的方式去了解。
二、通过注释生成在线文档的思考
有人说注释要很规范,方便给别人,比如用 jsdoc 等 。我的观点是,对一些不需要开源的 web 项目,没有必要用 jsdoc , 理由如下:
1.繁琐,需要按照 jsdoc 规则来。
2.个人认为,jsdoc 有入侵性,文档规则需要写在代码中。
如果要写注释说明手册,对于大型项目,我推荐使用 apidoc , 因为 apidoc 入侵性不强,不要求把规则写在代码中,可以把所有规则写到一个文件中。
但是一般小项目,没有必要单独写一份 api 文档。如果是开源的大型项目,首先需要考虑是否有开源的官方网站,你会看到网上的一些开源项目官网好像很酷,其实这个世界上不缺的就是轮子,你也可以很快的做出这样的网站,
下面我们来看看是如何做到的。
首先看一下 taro 源码,如下图:
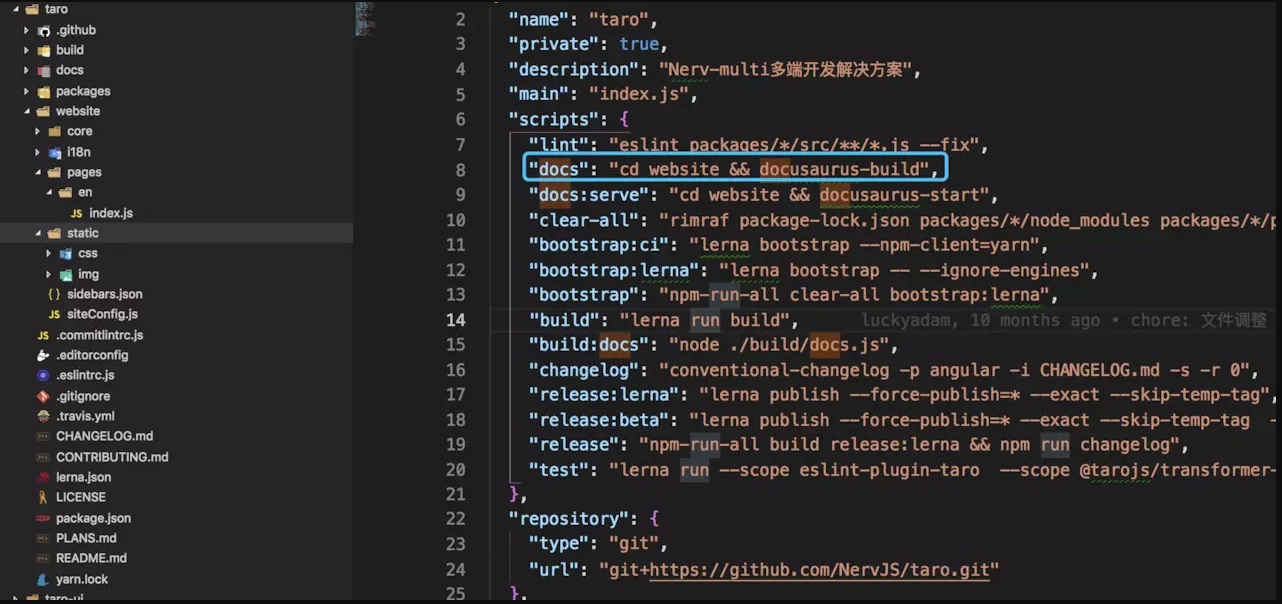
这里就是生成一个静态网站的秘密,执行 npm run docs 就可以。用的是 docusaurus 包。
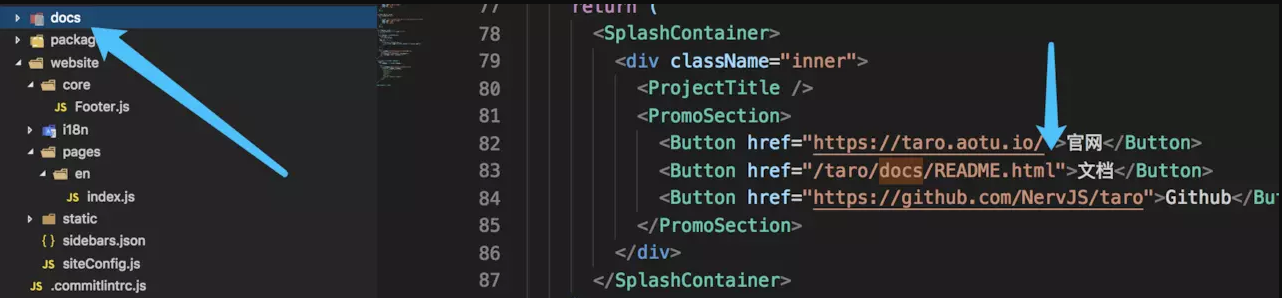
从上图中可以知道,文档的内容,来源于 docs 目录,里面都是 md 文件,开源项目的文档说明都在这里。
当然也有把对应的文档直接放到对应的代码目录下的,比如 ant-design 如下图:
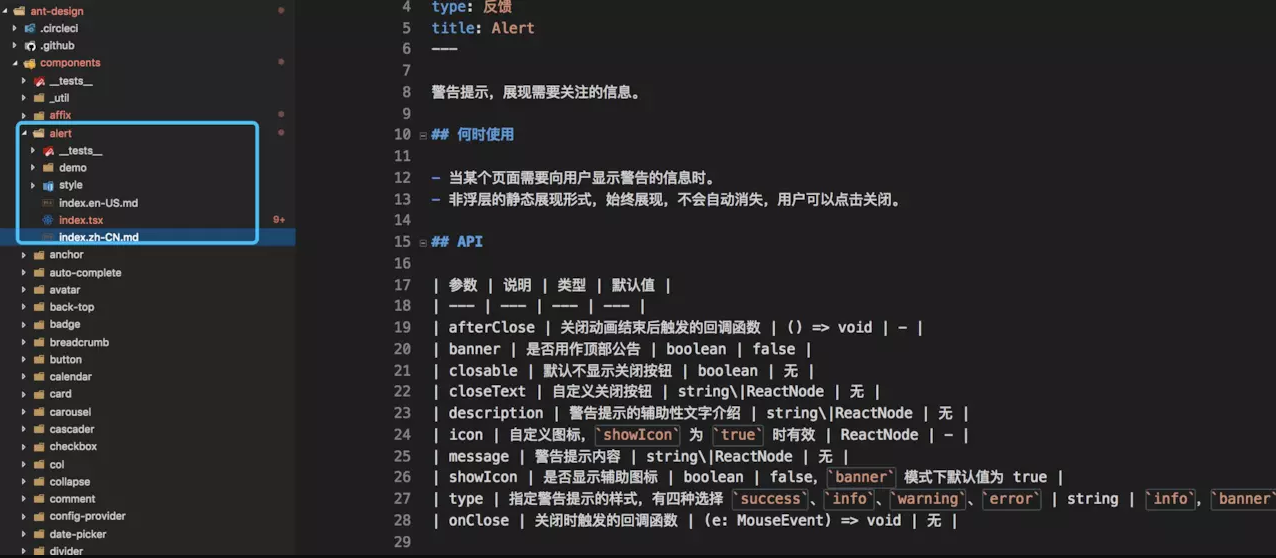
就是直接把文档放在组件目录下了。
从这里我们可以知道,目前流行的开源项目的官方网站是怎么实现的,以及文档该怎么写。
三、我个人的注释习惯
下面说说我本人对函数注释(只针对函数注释)的一些个人风格或者意见。
1、分享 VSCode 关于注释的几个工具
- Better Comments 给注释上色
- Document This 自动生成注释
- TODO Highlight 高亮 TODO ,并可以搜寻所有 TODO
下面是一张演示图:
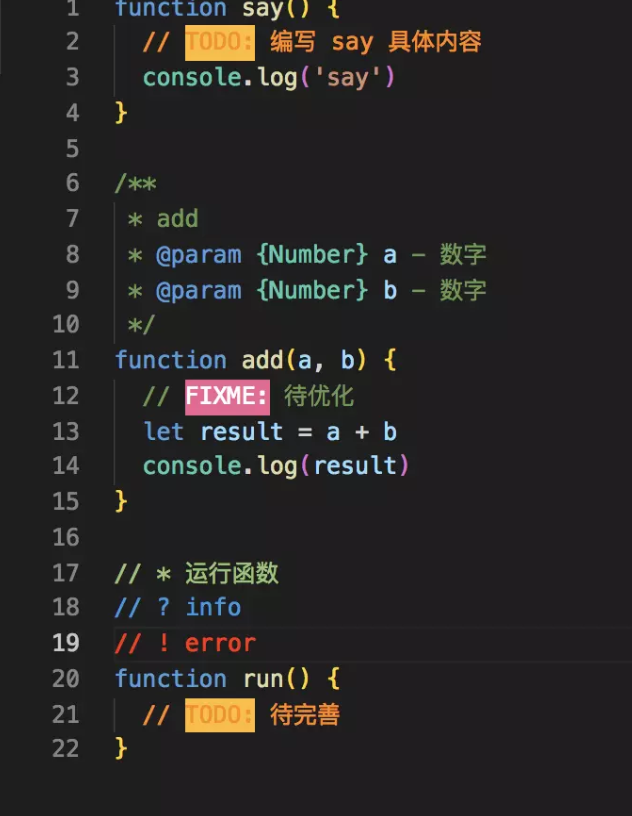
2、写和不写注释的平衡
我的观点是不影响可读性,复杂度低,对外界没有过度干涉的函数可以不写注释。
3、表达式语句的注释
函数内,表达式语句的注释可以简单点。如下图所示,// 后面加简要说明。
function say() {
// TODO: 编写 say 具体内容
console.log('say')
}
5、FIXME 注释
function fix() {
// FIXME: 删除 console.log方法
console.log('fix')
}
6、函数注释
一般分为普通函数和构造函数。
(1)普通函数注释:
/**
* add
* @param {Number} a - 数字
* @param {Number} b - 数字
* @returns {Number} result - 两个整数之和
*/
function add(a, b) {
// FIXME: 这里要对 a, b 参数进行类型判断
let result = a + b
return (result)
}
(2)构造函数注释:
class Kun {
/**
* @constructor
* @param {Object} opt - 配置对象
*/
constructor(opt = {}) {
// 语句注释
this.config = opt
}
}
7、总结
从开源项目的代码中可以发现,在遵守注释的基本原则的基础上,注释的风格多种多样;同一个作者不同项目的注释风格也有所差别,但我会尽可能的去平衡注释和不注释。
(三)函数的鲁棒性(防御性编程)
下图是一个段子:
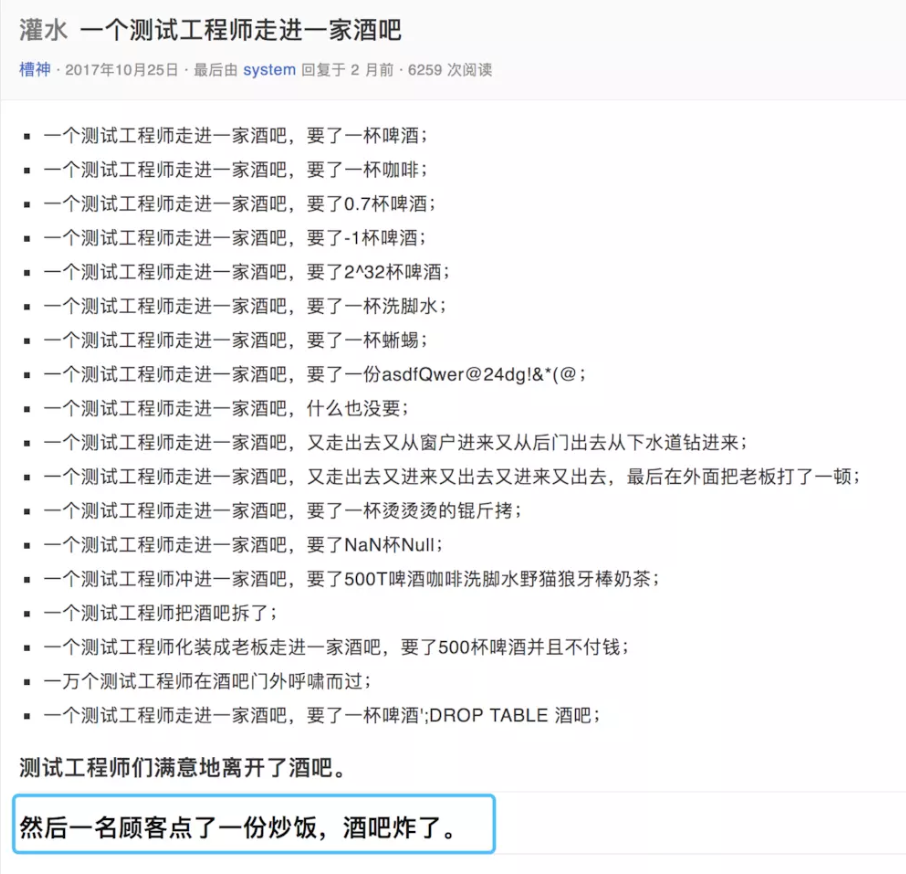
最后一句,测试测了那么多场景,最后酒吧还是炸了,怎么回事?
从中我们可以看出,防御性编程的核心是:
把所有可能会出现的异常都考虑到,并且做相应处理。
而我个人认为,防御性的程度要看其重要的程度。一般来说,不可能去处理所有情况的,但是提高代码鲁棒性的有效途径就是进行防御性的编程。
一、一个项目的思考
我曾经接手过一个需求,重写微信小程序的登录注册绑定功能,并将代码同步到其他小程序(和其他小程序的开发进行代码交接并协助 coder 平稳完成版本过渡)。
这个项目由于用户的基数很大,风险程度很高,需要考虑很多场景,比如:
-
是否支持线上版本回退,也就是需要有前端的 AB 版本方案(线上有任何问题,可以快速切到旧登录方案)
-
需要有各种验证:图形验证码、短信验证码、ip 、人机、设备指纹、风控、各种异常处理、异常埋点上报等。
-
代码层面的考虑:通过代码优化,缩短总的响应时间,提高用户体验。
-
如何确保单个节点出问题,不会影响整个登录流程。
如何去合理的完成这个需求还是比较有难度的。
PS: 关于第4点的如何确保单个节点出问题,不会影响整个登录流程,文末有答案。
下面我就关于函数鲁棒性,说一说我个人的一些看法。
二、前端函数鲁棒性的几种方式
1、入参要鲁棒性
在 ES6+ 到来后,函数的入参写法已经得到了质的提高和优化。看下面代码:
function print(obj = {}) {
console.log('name', obj.name)
console.log('age', obj.age)
}
同时会发现,如果入参的默认值是 {} ,那函数里面的 obj.name 就会是 undefined ,这也不够鲁棒,所以下面就要说说函数内表达式语句的鲁棒性了。
2、函数内表达式语句要鲁棒性
继续上个例子:
function print(obj = {}) {
console.log('name:', obj.name || '未知姓名')
console.log('age:', obj.age || '未知年龄')
}
function print(obj = {}) {
const { name = '未知姓名', age = '未知年龄' } = obj
console.log('name:', name
console.log('age:', age)
}
3、函数异常处理的两个层面
- 防患于未然,从一开始就不要让异常发生。
- 异常如果出现了,该怎么去处理出现的异常。
那如何去更好的处理各种异常,提高函数的鲁棒性呢,我个人有以下几点看法。
4、推导一下 try/catch 的原理
js 在 node.js 提供的运行时环境中运行,node.js 是用 C++ 写的。C++ 有自己的异常处理机制,也是有 try/catch 。即 js 的 try/catch 的底层实现是直接通过桥,调用 C++ 的 try/catch 。
而 C++ 的 try/catch 具有一些特性,如try/catch 只能捕捉当前线程的异常。这样就解释了为什么 JS 的 try/catch 只能捕捉到同步的异常,而对于异步的异常就无能为力了(因为异步是放在另一个线程中执行的)。
这里是我的推导,不代表确切答案。
这里我推荐一篇博客:《C++中try、catch 异常处理机制》 ,有兴趣的可以看看。
5、合理的处理异常
第一个方法:如果是同步操作,可以用 throw 来传递异常
看下面代码:
try {
throw new Error('hello godkun, i am an Error ')
console.log('throw 之后的处代码不执行')
} catch (e) {
console.log(e.message)
}
如果上下文环境中,都没有使用 try/catch 的话,但是又 throw 了异常,那么程序大概率会崩溃。
如果是 nodejs ,此时应该再加一个进程级的 uncaughtException 来捕捉这种没有被捕捉的异常。通常还会加上 unhandledRejection 的异常处理。
第二个方法:如果是异步的操作
有三种方式:
-
使用 callback ,比如 nodejs 的 error first 风格。
-
对于复杂的情况可以使用基于 Event 的方式来做,调用者来监听对象的 error 事件。
-
使用 promise 和 async/await 来捕捉异常。
怎么去选择哪个方式呢?依据以下原则:
-
简单的场景,直接使用 promise 和 async/await来捕捉异常。
-
复杂的场景,比如可能会产生多个错误,这个时候最好用 Event 的方式。
第三个方法:如果既有异步操作又有同步操作
最好的方式就是使用最新的语法:async/await 来结合 promise 和 try/catch 来完成对既有同步操作又有异步操作的异常捕捉。
第四个方法:处理异常的一些抽象和封装
对处理异常的函数进行抽象和封装也是提高函数质量的一个途径。如何对处理异常进行抽象和封装呢?有几个方式可以搞定它:
-
第一种方式:对 nodejs 来说,通常将异常处理封装成中间件,比如基于 express/koa 的异常中间件,通常情况下,处理异常的中间件要作为最后一个中间件加载,目的是为了捕获之前的所有中间件可能出现的错误。
-
第二种方式:对前端或者 nodejs 来说,可以将异常处理封装成模块,类似 Event 的那种。
-
第三种方式:使用装饰器模式,对函数装饰异常处理模块,比如通过装饰器对当前函数包裹一层 try/catch 。
-
第四种方式:使用函数式编程中的函子( Monad )等来对异常处理进行统一包裹,这里 的 Monad 和 try/catch 在表现上都相当于一个容器,这是一个相当强大的方法。从 Monad 可以扩展出很多异常处理的黑科技,但是我建议慎用,因为不是所有人都能看懂的,要考虑团队的整体技术能力,当然一个人的话,那就随便嗨了。
合理的处理异常,根据具体情况来确定使用合理的方式处理异常
这里推荐一篇博客:《Callback Promise Generator Async-Await 和异常处理的演进》
三、如何确保单个节点出问题,不会影响整个登录流程
比如登录流程需要4个安全验证,按照通常的写法,其中一个挂了,那就全部挂了,但是这不够鲁棒性,如何去解决这个问题呢。
主要方案就使用将 promise 的链式写法换一种方式写,以前的写法是这样的:
伪代码如下:
auth().then(getIP).then(getToken).then(autoLogin).then(xxx).catch(function(){})
伪代码如下:
auth().catch(goAuthErrorHandle).then(getIP).catch(goIPErrorHandle).then(function(r){})
四、我个人对异常处理的看法
我个人认为对异常的处理,还是要根据实际情况来分析的。大概有以下几点看法:
要考虑项目可维护性,团队技术水平
我曾在一个需求中,使用了诸如函子等较为抽象的处理异常的方法,虽然秀了一把(作死),结果导致后续这块的需求改动,还得我自己来。
要提前预估好项目的复杂性和重要性。
比如在做一个比较重要的业务时,一开始没有想到异常处理需要这么细节,而且一般第一版的时候,需求并没有涉及到很多异常情况处理,但是后续需求迭代优化的时候,发现异常情况处理是如此的多,直接导致需要重写异常处理相关的代码。
所以以后在项目评估的时候,要学会尝试根据项目的重要性,来提前预留好坑位。
这也算是一种面对未来的编程模式。
五、总结
关于函数的鲁棒性(防御性编程),本文主要介绍了前端或者是 nodejs 处理异常的常规方法。
处理异常不是一个简单的活,工作中还得结合业务去确定合适的异常处理方式,总之,多多实践出真知。
更多内容敬请关注 vivo 互联网技术 微信公众号

注:转载文章请先与微信号:labs2020 联系。