理解OpenCL中的工作组、工作项的索引
理解OpenCL中的工作组、工作项的索引
==============================================================
目录结构
1、工作组和工作项
2、一维数据的工作组和工作项
3、深度学习中二维图像的池化(Pooling)
4、参考
==============================================================
关键词:OpenCL 工作组 工作项 深度学习池化Pooling
本文第1节介绍了OpenCL中的工作组和工作项,摘抄自书本《OpenCL编程指南》,因其在并行计算中比较重要,特别作为重点从理论到实践理解。
第2节以核函数为例,该函数的输出是输入数组数据的两倍,同时输出各个工作项对应的全局ID和局部ID。
第3节以深度学习中的池化为例,介绍了2维图像的工作组和工作项ID,以及简单提及3维内容的工作组和工作项ID。
1、工作组和工作项
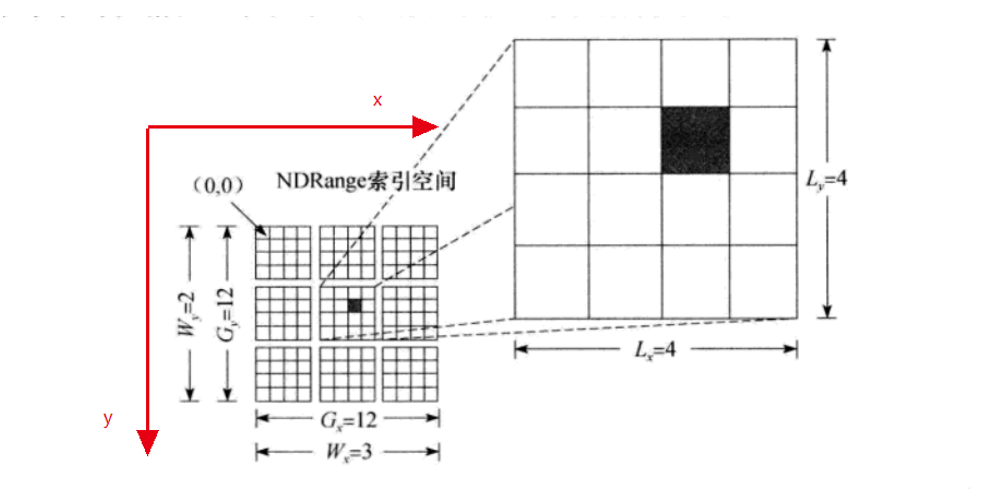
OpenCL运行时系统会创建一个整数索引空间,索引空间是N维的值网格,N为1、2或3,又称NDRange。
执行内核的各个实例称为工作项(work-item)。工作项在整个索引空间中由一个全局ID标识,就像学校给学生用学号标识。
工作项组织为工作组(work-group)。全局索引为工作组指定了工作组ID(就像学校给班级编号),工作组内又为工作项指定了局部ID(就像班级里又为学生编了号)。
所以,如何通过坐标方式找到工作项。
(1)可以通过工作项的全局索引
(2)先通过工作组索引号,再通过局部索引号
使用(gx,gy)表示工作项的全局ID,全局索引工具大小为(Gx,Gy)。
所以工作项的坐标范围为[(0,Gx-1), (0,Gy-1)]。
用w表示工作组ID,W工作组各个维度的维度大小。
把一个工作组内的索引空间称为局部索引空间。各个维度的大小用字母L表示,局部ID使用小写字母l表示。
因此,大小为(Gx,Gy)的NDRange索引空间划分为Wx*Wy空间上的工作组,工作组的索引号为(wx,wy)。各个工作组大小为Lx*Ly。
Lx = Gx / Wx
Ly = Gy / Wy
通过工作项的全局ID(gx,gy)来定义工作项,或者通过局部ID(lx,ly)和工作组ID(wx,wy)定义:
gx = wx*Lx + lx
gy = wy*Ly + ly
全局索引空间各个维度起始点从0开始,不过在全局索引空间的起始点定义了一个偏移量,用小写字母o表示
gx = wx*Lx + lx + ox
gy = wy*Ly + ly + oy
2、一维数据的工作组和工作项
本例中的核函数如下,功能为将输入数据乘以2后输出。输入数据为8*8的数组,在主函数中将设置64个核一起处理,最后打印出输入数据、全局ID号、局部ID号和输出结果,通过以下语句实现:
work_dim:工作项的维度,此处为1维。
global_item_size:给每一个核函数编号的全局变量,此处为8*8=64,ID号从0~63。
local_item_size:4,给所有的核函数分组,每四个一组,每组内的ID从0到3。
clEnqueueNDRangeKernel函数的解析可以参考以下网址:
https://blog.csdn.net/gflytu/article/details/7686130
-
cl_uint work_dim = 1;
-
size_t global_item_size;
-
size_t local_item_size;
-
-
global_item_size = width*height; /*Global number of work items */
-
local_item_size = 4; /* Number ofwork items per work group */
-
/*--> global_item_size / local_item_size which indirectly sets the
-
numberof workgroups*/
-
-
/* Execute Data Parallel Kernel */
-
ret =clEnqueueNDRangeKernel(command_queue, kernel, work_dim, NULL,
-
&global_item_size,&local_item_size,
-
0, NULL, NULL);

图2. 工作组共有64/4=16个
以上设置共有16个工作组,每个工作组的局部ID有0,1,2,3四个,注意观察控制台打印输出。
核函数:add_vec.cl
-
__kernel void add_vec(__global int * data_in,
-
__global int *mem_global_id,
-
__global int *mem_local_id,
-
__global int *data_out,
-
int length)
-
{
-
int i,j;
-
int global_id;
-
int local_id;
-
-
global_id = get_global_id(0);
-
local_id = get_local_id(0);
-
-
mem_global_id[global_id] =global_id;
-
mem_local_id [global_id] = local_id;
-
-
-
for(i=0; i<length; i++)
-
{
-
data_out[i] =data_in[i]*2;
-
}
-
-
}
主函数:main.cpp
https://github.com/yywyz/OpenCL-Programming-Examples/blob/master/work_id_1dim/main.cpp
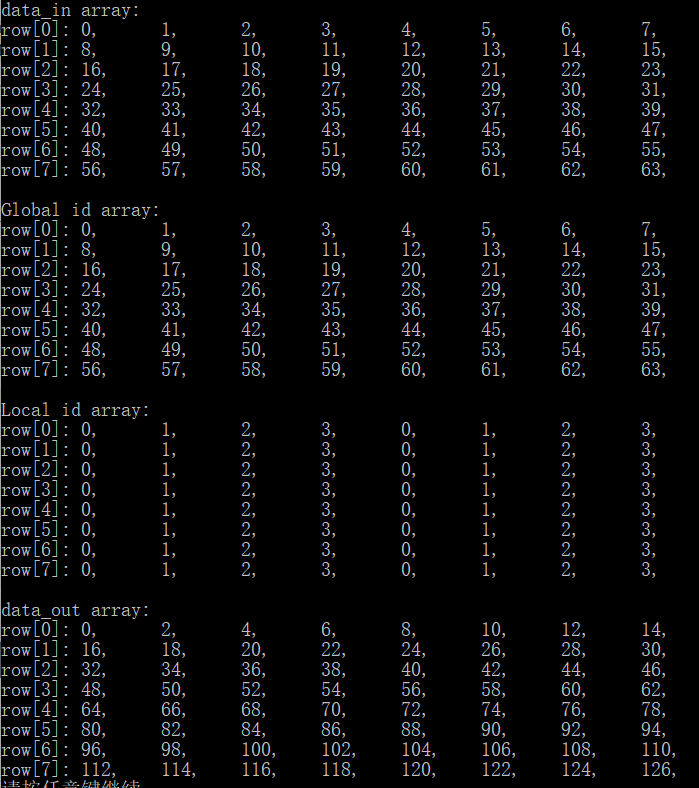
图3. 一维数组的输入数据、全局ID数组、局部ID数组和输出数据数组
3、深度学习中二维图像的池化(Pooling)
以下例子为二维数据的例子,以深度学习中的池化(Pooling)为例,在深度学习中,池化可以降低数据维度,聚合数据特征,减少计算量等。池化的方法有多种,如平均值池化,最大值池化。可参考https://blog.csdn.net/silence1214/article/details/11809947
本例使用2*2最大值池化,输入数据8*8,输出数据4*4。
使用2维工作组,打印输出各个工作组全局ID和局部ID,如全局ID为(x,y),则输出表示为xy,在核函数中记为10*x+y。
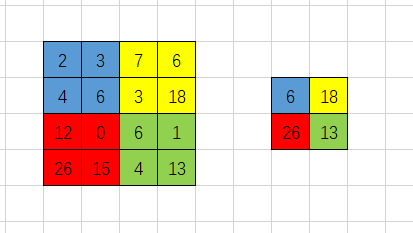
图4. 2*2 max_pooling例子
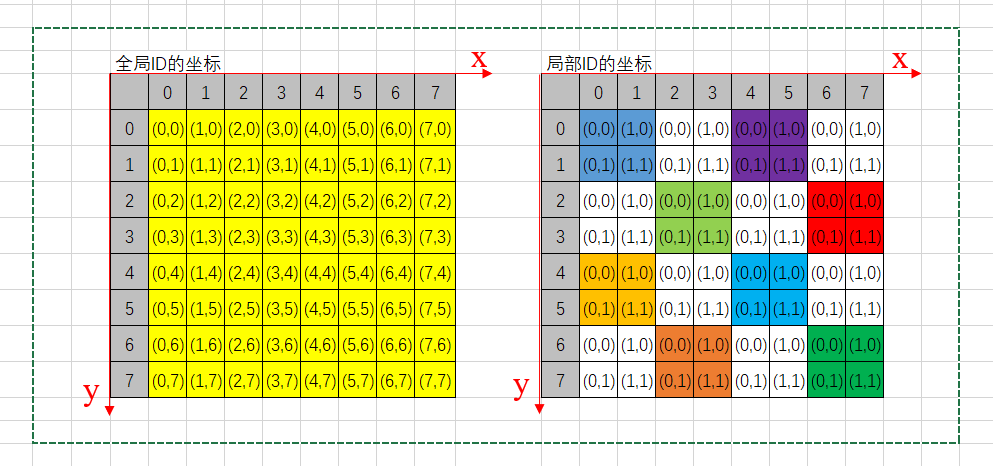
图5. 二维图像工作组的全局ID和局部ID
以上通过在主函数中的以下语句实现,将工作维度设置为2,设置各个维度的全局大小分别为8和8,通过设置局部块大小来确定工作组,设置为2,所以工作组一共有(8/2)*(8/2)=16个:
-
cl_uint work_dim = 2;
-
size_t global_item_size[2] = {8, 8};
-
size_t local_item_size[2] = {2, 2};
-
-
/* Execute Data Parallel Kernel */
-
ret =clEnqueueNDRangeKernel(command_queue, kernel, work_dim, NULL,
-
global_item_size,local_item_size,
-
0,NULL, NULL);
如果需要设置三维工作组ID,则以上同理,另外增加两个数组维度分别控制各个组大小。
以下为本例的核函数核主函数,以及实验结果。
核函数:pooling.cl
-
/**********************************************
-
function:max_pooling, 2*2
-
2018/05/24
-
**********************************************/
-
-
__kernelvoid pooling(__global int * data_in,
-
__global int *mem_global_id,
-
__global int *mem_local_id,
-
__global int *data_out,
-
int width)
-
{
-
int i,j;
-
int global_id_x, global_id_y;
-
int local_id_x, local_id_y;
-
-
global_id_x = get_global_id(0);
-
global_id_y = get_global_id(1);
-
local_id_x = get_local_id(0);
-
local_id_y = get_local_id(1);
-
-
//(x,y)
-
mem_global_id[global_id_y * width +global_id_x] = global_id_x * 10 + global_id_y;
-
mem_local_id [global_id_y * width +global_id_x] = local_id_x * 10 +local_id_y;
-
-
if((global_id_x % 2 == 0 )&&(global_id_y % 2 == 0))
-
{
-
int index1 = global_id_y* width + global_id_x;
-
int index2 = global_id_y* width + global_id_x + width;
-
int tmp1 =max(data_in[index1],data_in[index1 + 1]);
-
int tmp2 =max(data_in[index2],data_in[index2 + 1]);
-
int tmp = max(tmp1,tmp2);
-
data_out[global_id_y / 2* width / 2 + global_id_x/2] = tmp ;
-
}
-
}
主函数main.cpp
https://github.com/yywyz/OpenCL-Programming-Examples/blob/master/work_id_2dim_pooling/main.cpp
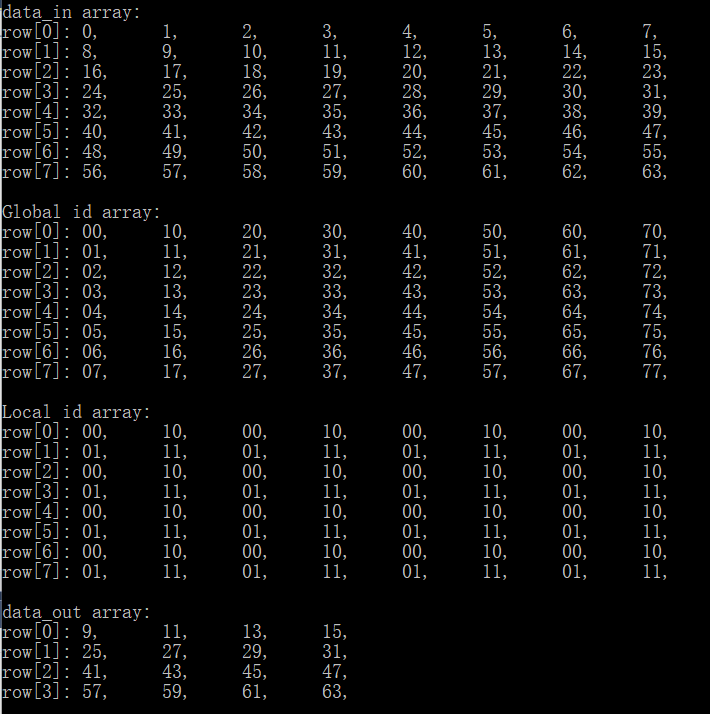
图6. 二维数组的输入数据、全局ID数组、局部ID数组和输出池化结果
4、参考
第1节摘抄自《OpenCL编程指南》,其他均为个人实践结果。
如有错误,请指出,谢谢阅读。
这个文章确实很好介绍的
转自:https://blog.csdn.net/zhouxuanyuye/article/details/80445076