一、其它
- 查看文档的方式:API、help()
- 通过查 scikit-learn 库的 API ,查看 scikit-learn 中各个模块下的各个方法的功能、用法;
- 模块的方法下有多种参数,每一种参数有多种设置,第一个设置为该参数的默认状态;
- 模块下的方法的具体封装:在各个模块安装目录下的 .py 文件中;
- 如:D:软件安装PythonLibsite-packagessklearnmetricsclassification.py
- 如:D:软件安装PythonLibsite-packagessklearnmodel_selection\_search.py
- 思想:机器学习领域中模型出现的问题,很多时候原因不是出在算法层面上,而是出在样本数据层面上,所以面对混淆矩阵反应出的模型错误点,一定要查看产生错误的样本数据,人为的理解为什么面对这些样本类型模型会犯错误,可能样本数据也出现问题,即使样本数据没有问题,也能通过观察总结出更多样本新的特征;
- 思想:实践中,解决机器学习要解决的问题的时候,有时候并不能通过算法很好的解决这个问题,要回到数据中,查看数据是否出现问题,是否能更好的整理、清理、提取数据特征;
二、多分类问题中的混淆矩阵
1)基础
-
求取混淆矩阵
from sklearn.metrics import confusion_matrix confusion_matrix(y_test, y_predict)
- confusion_matrix():可直接计算多分类问题的混淆矩阵;
- 多分类问题,精准率、召回率、阈值的计算,需要修改 average 参数:average = 'micro'
- 以精准率为例:
from sklearn.metrics import precision_score precision_score(y_test, y_predict, average='micro')
- 可视化步骤
- 计算矩阵每一行的数据和
row_sums = np.sum(cfm, axis=1)
- 计算矩阵每一行的数据所站该行数据总和的比例
err_matrix = cfm / row_sums
- 将新的矩阵的对角线的数据更改为 0
np.fill_diagonal(err_matrix, 0)
# np.fill_digonal(矩阵, m):将矩阵对角线的数据全部改为 m;
- 绘制混淆矩阵
plt.matshow(cfm, cmap=plt.cm.gray) plt.show()
- 让矩阵对角线的数据更改为0:因为对角线的数据全是模型预测正确的样本的数量,而分析混淆矩阵的主要目的是查看模型预测错误的地方;
- plt.matshow(矩阵, 颜色类型):直接绘制一个矩阵
- 思路:以同一种颜色的不同深度反应数据大小;
- cmap = plt.cm.gray:选择颜色类型为灰色(gray);
- 功能
- 直观查看模型犯错误的地方,以及所犯的具体错误;
- 根据模型犯错误地方,改进模型;
2)例
-
计算混淆矩阵
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets digits = datasets.load_digits() X = digits.data y = digits.target from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8) from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression() log_reg.fit(X_train, y_train) log_reg.score(X_test, y_test) y_predict = log_reg.predict(X_test) cfm = confusion_matrix(y_test, y_predict)
- 矩阵变形
# 矩阵变形处理: # 1)计算矩阵每一行的数据和; row_sums = np.sum(cfm, axis=1) # 2)计算矩阵每一行的数据所站该行数据总和的比例; err_matrix = cfm / row_sums # 3)让矩阵对角线的数据更改为0:因为对角线的数据全是模型预测正确的样本的数量,而分析混淆矩阵的主要目的是查看模型预测错误的地方; # np.fill_digonal(矩阵, m):将矩阵对角线的数据全部改为 m; np.fill_diagonal(err_matrix, 0)
- 可视化
plt.matshow(err_matrix, cmap=plt.cm.gray) plt.show()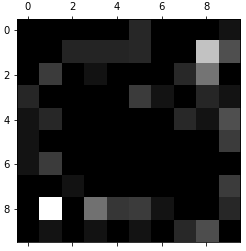
- 分析:
- 图中越亮的地方就是模型犯错较多的地方,而且可以直接看出模型所犯的具体错误;
- 第 8 行 第 1 列的格子最亮,说明模型总是将数字 8 预测为 1,且犯错最多;