一、决策树思维、决策树算法
1)决策树思维
- 决策树思维是一种逻辑思考方式,逐层的设定条件对事物进行刷选判断,每一次刷选判断都是一次决策,最终得到达到目的;整个思考过程,其逻辑结构类似分叉的树状,因此称为决策树思维;
- 例一:公式招聘时的决策树思维
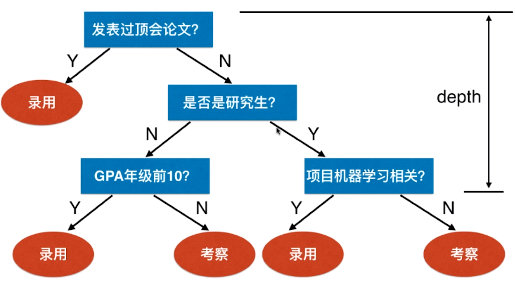
- 此过程形成了一个树的结构,树的叶子(录用 / 考察)节点位置是做出的决定,也可以理解为是对输出(也就是应聘者的信息)的分类:录用、考察——这样的逻辑思考的过程就叫决策树。
- 树的最高深度:depth == 3,说明最多做出 3 次判断就能得到结果;
2)scikit-learn 中的决策树算法
-
例二:
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets iris = datasets.load_iris() X = iris.data[:, 2:] y = iris.target plt.scatter(X[y==0, 0], X[y==0, 1]) plt.scatter(X[y==1, 0], X[y==1, 1]) plt.scatter(X[y==2, 0], X[y==2, 1]) plt.show()
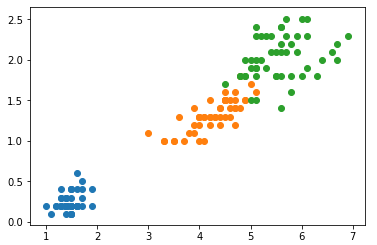
-
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) # 使用 DecisionTreeClassifier 方法对数据分类 from sklearn.tree import DecisionTreeClassifier # 创建决策树的分类器 # 构造决策树时,DecisionTreeClassifier() 方差需要传入两个参数: # 1)max_depth:决策树最高深度; # 2)criterion='entropy':表示“熵”的意思; dt_clf = DecisionTreeClassifier(max_depth=2, criterion='entropy') dt_clf.fit(X, y) plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) plt.scatter(X[y==0, 0], X[y==0, 1]) plt.scatter(X[y==1, 0], X[y==1, 1]) plt.scatter(X[y==2, 0], X[y==2, 1]) plt.show()

3)分析模型的决策边界:得出模型的决策树
4)决策树算法
- 决策树算法是借用了决策树思维解决分类问题(或者回归问题)的算法;
- 决策树算法的特点:
- 非参数学习算法;
- 可以解决分类问题;
- 天然可以解决多分类问题;
- 也可以解决回归问题;(结果是一个数值)
- 具有非常好的可解释性;
二、信息熵
- “信息熵”:随机变量不确定度的度量,是信息论中的代表;
- 特点:熵越大,数据的不确定性越高;熵越小,数据的不确定性越低;
- 不确定性:一组数据的个数一定,元素的种类越少,该组数据的不确定性越高;
1)信息熵的计算:
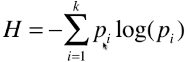
- Pi:对于一个系统中,有 k 类的信息,每一类信息所占系统的比例,记为 P;
- k 类:比如数据集中样本的总类数;
- 比例:每一类样本数量占总数的多少;
- 公式中的 “-”:由于 Pi < 1,则 log(Pi) < 0,熵的值 H 应该大于 0;
- log(Pi):对数函数的底数可以取2,e或者10,取的底不同,获得的信息熵的结果的单位不同,分别称为:bits, nats 和 bans。
2)实例了解信息熵的计算
-
例一:
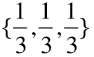
- k == 3:共 3 种样本类别;
- P1 == P2 == P3 == 1/3
 ,此处选择的底数是自然对数 e;
,此处选择的底数是自然对数 e;
- 在这里的计算中,我们求信息熵的底可以用任意值,因为具体在划分的时候,不管底取多少,H这个函数的性质是不会变的。
-
例二:

- k == 3
- P1 == 1/10、P2 == 2/10、P3 == 7/10

-
例三:

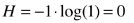
3)3 个例子对比分析
- 现象:例一的信息熵 > 例二的信息熵 > 例三的熵
- 结论:
- 确定性:例三 > 例二 > 例一
- 例二中的数据的确定性比例一高更高,因为它有 70% 的数据是同一类型的;
- 信息熵物理上的最小值:Hmin = 0;
三、构建决策树的思路和问题
1)决策树算法的思想
- 解决分类问题时,决策树算法的任务是构造决策树模型,对未知的样本进行分类;
- 决策树算法利用了信息熵和决策树思维:
- 信息熵越小的数据集,样本的确定性越高,当数据集的信息熵为 0 时,该数据集中只有一种类型的样本;
- 训练数据集中有很多类型的样本,通过对数据集信息熵的判断,逐层划分数据集,最终将每一类样本单独划分出来;
- 划分数据集的方式有很多种,只有当按样本类别划分数据集时(也就是两部分数据集中不会同时存在相同类型的样本),划分后的两部分数据集的整体的信息熵最小;反相推断,当两部分数据集的整体的信息熵最小时,则两部分数据集中不会同时存在相同类型的样本;
- 预测:根据模型参数划分结束后,对每个“叶子”节点的样本数据进行投票,规定数量最多的样本的类型为该“叶子”的预测类型;(也就是未知的样本经过逐层决策后到达该“叶子”节点处,则认为该样本的类型为其所处的“叶子”的预测类型)
2)概念
- 根节点:第一次进行划分的节点,拥有全部数据;
- 维度:一般指样本特征;
- 划分点:选定的特征的一个值;(按某特征的值的大小排列数据集样本,根据该特征的值划分数据集)
- 整体的信息熵:节点处的数据集划分为两部分后的信息熵,等于两部分数据集信息熵的和:H总 = H1 + H2;
- H1 = -log(P1) - log(P2) - ... - log(Pk):第一部分数据集中共有 k 种样本类型;
3)思路
- 思路:先找到划分一个节点数据集的方法,用此方法,从根节点开始划分数据集,直到所有的数据集不需要再进行划分,此时的决策树为最终的决策树模型;
4)问题
- 节点处的数据集应该按哪个维度的哪个阈值进行划分?
- 怎么判断该数据集不需要再进行划分?
5)解决思想
- 按不同的特征的不同值将数据集划分为两部分,划分的方式有很多种,划分后的两部分数据集的信息熵的总和最小时,对应的划分方式为最佳,此时的特征和该特征的值为最佳;
- 如果一个数据集的信息熵为 0,说明该数据集中只有一类样本,则不再对该数据集进行划分;
- 任务:
- 寻找一种方式——为每一个节点处选取一个维度,维度上选取一个值,根据这个维度和取值对数据进行划分,划分以后使得整个系统的信息熵最低;
- 方法:
- 对所有的划分可能性进行搜索,比较每一种方式所得的系统整体的信息熵,最低的信息熵对应的划分方式就是该节点最终的结构;
- 按此思路和方式,确定决策树的每一个节点,进而确定决策树的最终结构;
- 在极端情况下:
- 如下图,A、B、C 3 个叶子节点处,每个叶子节点中的数据都只属于 A、B、C 它们本身;此时整个系统的信息熵就达到了 0(每处叶子种只有一类样本,信息熵为 0,因此整体系统的信息熵也是 0);

6)计算二分类结果的整体的信息熵
- 二分类的信息熵计算:
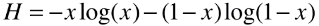 ,x 表示其中一类样本的比例;
,x 表示其中一类样本的比例;
- 绘制此函数的图像:x 的取值范围定义为:[0.01,0.99]
-
import numpy as np import matplotlib.pyplot as plt # np.log(p):此时的 p 不仅可以是一个数,还能是一个向量; # 当 p 传入的是数组时,可以一次性计算出数组中所有元素的信息熵,再以数组的形式返回; def entropy(p): return -p * np.log(p) - (1-p) * np.log(1-p) x = np.linspace(0.01, 0.99, 200) plt.plot(x, entropy(x)) plt.show()
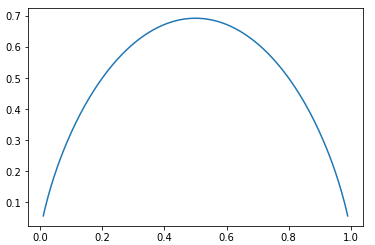
- 当 x = 0.5 时,H 最大;
- 相对于 0.5,无论 x 值偏大或者偏小,H 值都降低,因为无论 x 值偏向哪一类,数据集中的样本都更集中于一类样本,数据集的确定性就会偏高。
四、老师答疑
- 问(一):决策树模型中,每个节点处的数据集划分到最后,得到的“叶端”数据集中一定只包含一种类型的样本吗?
- 老师:是的!如果你不规定最高决策树深度,节点划分最小样本数等信息的话,最终没一个叶子节点又有可能包含一类样本信息,即信息熵为0:)但是,对于正常的数据,这样做近乎一定过拟合。关于我说的这些参数,后续课程会有介绍:)
- 问(二):如果最终所有决策树模型的“叶端”的数据集中只包含一种类型的样本,所有的“叶端”数据集对应的样本类型当中,有没有相同的类型?
- 老师:可能!举一个实际的例子(不一定科学),判断一个肿瘤是良性还是恶性,有肿瘤的长度和宽度两个指标,可能得到的决策树是这样的:有两个叶子节点对应的样本是良性的;你可以想象,在更复杂的场景下,样本的特征更多,决策树的层数更高,叶子节点更多,势必有很多叶子节点最终的类别是一样的;
肿瘤样本 / 长度>10? 长度 <= 10 / (良性) 宽度 < 10 宽度 >= 10 (良性) (恶性)
- 问(三):我们对节点数据集划分时,是不是“只有当按样本类别划分数据集时(也就是划分后的两部分数据集中不会同时存在相同类型的样本),划分后的两部分数据集的整体的信息熵最小?”
- 老师:是这样的,但是对于很多数据,在初始化分的时候,会不存在这样的划分(如果只基于一个特征和一个固定值进行划分的话)。通常划分后的两部分数据集,依然都每个样本的数据各有一些,所以还需要到下一层继续划分。
- 问(四):在根据某一特征对样本进行分类时,有没有可能是:特质值在区间 [a, b] U [c, d] 上的样本定义为一个类别?
- 老师:有可能,但根据我们的算法,还是会先选择一个分割点,另一个分割点在后续的划分时出现,所以有了2)的情况。
-
结论:
- 决策树模型中,每个节点处的数据集划分到最后,得到的“叶端”数据集中不一定只包含一种类型的样本;
- 所有的“叶端”数据集对应的样本类型当中,有些实际业务中存在相同的类型。
- 对节点数据集划分时,只有当按样本类别划分数据集时(也就是划分后的两部分数据集中不会同时存在相同类型的样本),划分后的两部分数据集的整体的信息熵最小。
- 在根据特征进行样本分类时,有些类型的样本之间存在关联,如问(二)中,老师举例的肿瘤案例:长度 <= 10 的全是良性肿瘤,长度 > 10 的有些是良性肿瘤有些是恶性肿瘤。