数仓建模之设计与开发
1. 数据模型入门
1).数据模型概念
数据模型的定义:数据模型是抽象描述现实世界的一种工具和方法,是通过抽象的实体及实体之间联系的形式,来表示现实世界中事务的相互关系的一种映射。读起来有些拗口,可以简单理解为描述实体及关系的一个方法。
2).数据模型意义
引入数据模型,是为了方便人们了解客观世界。针对企业内的数据模型而言,可方便直观了解企业业务,帮助企业梳理、改善、优化业务流程。通过有效的建模,可以将企业内的数据有效地组织起来,有利于企业高性能、低成本、高效率、高质量的使用它们。
-
性能
通过数据建模,帮助快速查找数据,减少访问开销,提高访问效率。比较典型的设计如数据仓库中的宽表设计。
-
成本
通过有效的数据建模,减少数据冗余,节省存储成本。同时,充分利用模型中间结果,复用计算结果,提升计算效率。良好的数据模型,也有利于提升开发效率,进而节约开发成本。
-
稳定
数据模型的构建,将业务与业务进行解耦,提高自身的稳定性。当业务发生变化时,可通过变更或扩展数据模型,快速适配变化,提供系统整体稳定性。
-
质量
良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性。
-
共享
数据模型能够促进业务与技术进行有效沟通,形成对主要业务定义和术语的统一认识,具有跨部门、中性的特征,可以表达和涵盖所有的业务。
-
规范
通过统一的数据模型定义,可对业务形成统一认知,规范使用
3).数据模型要素
数据模型描述的内容,可分为数据结构、数据操作和数据约束三部分。
-
数据结构
数据结构用于描述系统的静态特征,包括数据的类型、内容、性质及数据之间的联系等。它是数据模型的基础,也是刻画一个数据模型性质最重要的方面。在数据库系统中,人们通常按照其数据结构的类型来命名数据模型。
-
数据操作
数据操作用于描述系统的动态特征,包括数据的插入、修改、删除和查询等。数据模型必须定义这些操作的确切含义、操作符号、操作规则及实现操作的语言。
-
数据约束
数据的约束条件实际上是一组完整性规则的集合。完整性规则是指给定数据模型中的数据及其联系所具有的制约和存储规则,用以限定符合数据模型的数据库及其状态的变化,以保证数据的正确性、有效性和相容性。
2. 数据仓库模型
1).数仓模型类别
常用的模型设计,可遵循概念模型、逻辑模型、物理模型的类别进行设计
-
概念模型
通过分析和归纳,划分成主题,并确定主题之间的关系。
-
逻辑模型
基于概念模型的基础,定义数仓实体,属性,关系,指导数据存储,组织和应用开发。
-
物理模型
就是通过数仓制定的一些命名,存储,压缩规范等实例化逻辑模型并落地执行。
2).数仓模型分层
数据仓库模型设计,通常会划分为多个层次。其主要目的如下:
-
清晰数据结构
每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
-
数据血缘追踪
能够快速准确地定位到问题,并清楚它的危害范围。
-
减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
-
把复杂问题简单化
将复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。当数据出现问题之后,不用修复所有的数据,只需要从有问题的步骤开始修复。
❖ 常见分层结构
常见的层次划分如下图,这是常见的一种划分方法。针对不同层的模型,可采用不同的建模方法,后面会详细谈到这点。

3. 数仓建模方法
1).关系(范式)建模
范式建模是数据仓库之父Inmon推崇的、从全企业的高度设计一个符合3NF模型,用实体加关系描述的数据模型描述企业业务架构。其基础是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象。它更多是面向数据的整合和一致性治理,正如Inmon所希望达到的“single version of the truth”。
❖ 建模方法
关系建模常常需要全局考虑,要对上游业务系统的进行信息调研,以做到对其业务和数据的基本了解,要做到主题划分,让模型有清晰合理的实体关系体系,以下是方法的示意:

-
优点:规范性较好,冗余小,数据集成和数据一致性方面得到重视。
-
缺点:需要全面了解企业业务、数据和关系;实施周期非常长,成本昂贵;对建模人员的能力要求也非常高,容易烂尾。
2).维度建模
维度模型是数据仓库领域另一位大师Ralph Kimball 所倡导的。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能,更直接面向业务。
❖ 建模方法
通常需要选择某个业务过程,然后围绕该过程建立模型,其一般采用自底向上的方法,从明确关键业务过程开始,再到明确粒度,再到明确维度,最后明确事实,非常简单易懂。

-
优点:技术要求不高,快速上手,敏捷迭代,快速交付;更快速完成分析需求,较好的大规模复杂查询的响应性能
-
缺点:维度表的冗余会较多,视野狭窄。
3).对比:关系模型vs维度模型

4. 数仓开发方法论
Kimball和Inmon是两种主流的数据仓库方法论,分别由 Ralph Kimbal大神 和 Bill Inmon大神提出,在实际数据仓库建设中,业界往往会相互借鉴使用两种开发模式。
1).Kimball:需求驱动
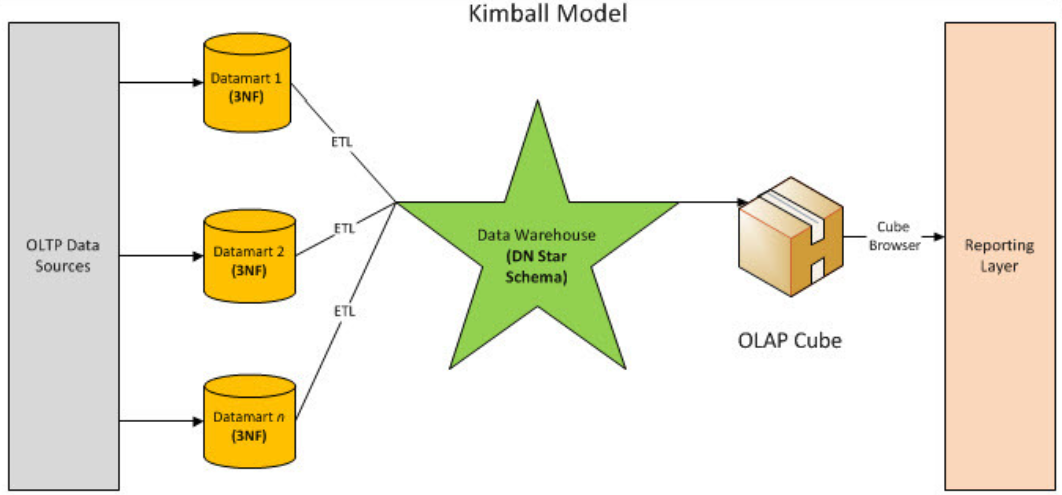
Kimball 模式从流程上看是是自底向上的,即从数据集市到数据仓库再到数据源(先有数据集市再有数据仓库)的一种敏捷开发方法,其是以最终任务为导向的。kimball采用了多维模型–星型模型,并且还是最低粒度的数据存储。先按照业务主线建立最小粒度的事实表,再建立维度表,形成数据集市,方便下一步的BI与决策支持。
❖ 开发过程
-
首先,在得到数据后需要先做数据的探索,尝试将数据按照目标先拆分出不同的表需求。
-
其次,在明确数据依赖后将各个任务再通过ETL由Stage层转化到DM层。这里DM层数据则由若干个事实表和维度表组成。
-
接着,在完成DM层的事实表维度表拆分后,数据集市一方面可以直接向BI环节输出数据了,另一方面可以先DW层输出数据,方便后续的多维分析。
2).Inmon:数据驱动
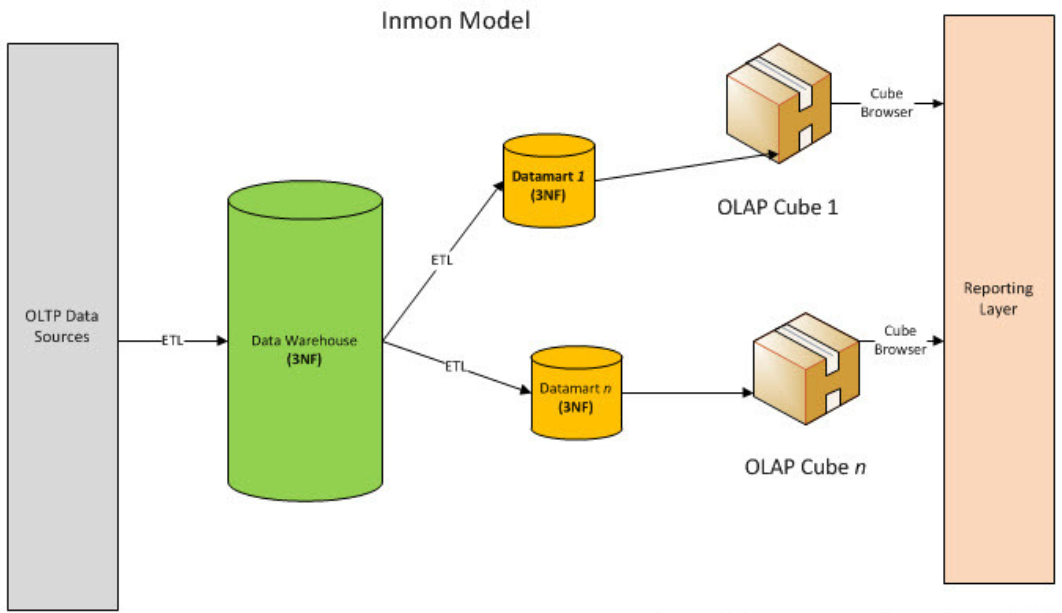
Inmon 模式从流程上看是自底向上的,即从数据源到数据仓库再到数据集市的一种瀑布流开发方法。对于Inmon模式,数据源往往是异构的,是根据最终目标自行定制的。这里主要的数据处理工作集中在对异构数据的清洗,包括数据类型检验,数据值范围检验以及其他一些复杂规则。在这种场景下,数据无法从stage层直接输出到dm层,必须先通过ETL将数据的格式清洗后放入dw层,再从dw层选择需要的数据组合输出到dm层。在Inmon模式中,并不强调事实表和维度表的概念,因为数据源变化的可能性较大,需要更加强调数据的清洗工作,从中抽取实体-关系。
3).对比:Kimball vs Inmon

一般来讲,维度模型简单直观,适合业务模式快速变化的行业,关系模型实现复杂,适合业务模式比较成熟的行业。对于大多数互联网公司由于需求的快速变化,处心积虑设计(Inmon)实体-关系的设计哲学似乎并不能满足快速迭代的业务需要。所以,更多场景下趋向于使用(Kimball)维度-事实的设计哲学反而可以更快地完成任务。