这是一篇关于Java内存结构组织的文章,涉及的概念主要有方法区、Java栈、java堆。通过这个文章,可以加深对Java对象的理解,以及优化代码的结构。
开始:
|
想写这篇总结酝酿了有个来月了,却始终感觉还差点什么东西,一直未敢动笔。 最近两天连夜奋战,重新整理下前面查阅的资料、笔记,还是决定将它写出来。 现在提出几个问题,如果都能熟练回答的大虾,请您飘过.如以往一样,我是小菜,本文自然也是针对小菜阶层的总结。 |
首先是概念层面的几个问题:
- Java中运行时内存结构有哪几种?
- Java中为什么要设计堆栈分离?
- Java多线程中是如何实现数据共享的?
- Java反射的基础是什么?
然后是运用层面:
- 引用类型变量和对象的区别?
- 什么情况下用局部变量,什么情况下用成员变量?
- 数组如何初始化?声明一个数组的过程中,如何分配内存?
- 声明基本类型数组和声明引用类型的数组,初始化时,内存分配机制有什么区?
- 在什么情况下,我们的方法设计为静态化,为什么?(上次胡老师问文奇,问的哑口无言,当时想回答,却老感觉表述不清楚,这里也简单说明一下)
好了,问题提完了,如果您都能一眼看出答案,那么,没有必要再浪费您宝贵的时间看下去了。
如果您还不太明白,请跟随我一路走下去。
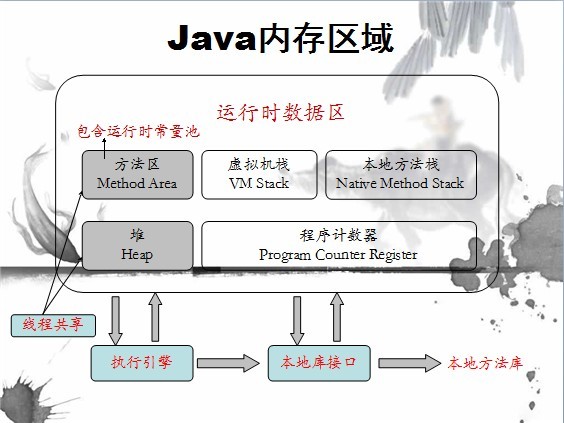
Java中运行时内存结构
1.1 方法区:
方法区是系统分配的一个内存逻辑区域,是JVM在装载类文件时,用于存储类型信息的(类的描述信息)。
方法区存放的信息包括:
1.1.1类的基本信息:
- 每个类的全限定名
- 每个类的直接超类的全限定名(可约束类型转换)
- 该类是类还是接口
- 该类型的访问修饰符
- 直接超接口的全限定名的有序列表
1.1.2已装载类的详细信息:
- 运行时常量池:
在方法区中,每个类型都对应一个常量池,存放该类型所用到的所有常量,常量池中存储了诸如文字字符串、final变量值、类名和方法名常量。它们以数组形式通过索引被访问,是外部调用与类联系及类型对象化的桥梁。(存的可能是个普通的字符串,然后经过常量池解析,则变成指向某个类的引用)
- 字段信息:
字段信息存放类中声明的每一个字段的信息,包括字段的名、类型、修饰符。
字段名称指的是类或接口的实例变量或类变量,字段的描述符是一个指示字段的类型的字符串,如private A a=null;则a为字段名,A为描述符,private为修饰符
- 方法信息:
类中声明的每一个方法的信息,包括方法名、返回值类型、参数类型、修饰符、异常、方法的字节码。
(在编译的时候,就已经将方法的局部变量、操作数栈大小等确定并存放在字节码中,在装载的时候,随着类一起装入方法区。)
在运行时,JVM从常量池中获得符号引用,然后在运行时解析成引用项的实际地址,最后通过常量池中的全限定名、方法和字段描述符,把当前类或接口中的代码与其它类或接口中的代码联系起来。 - 静态变量:
这个没什么好说的,就是类变量,类的所有实例都共享,我们只需知道,在方法区有个静态区,静态区专门存放静态变量和静态块。
- 到类classloader的引用:到该类的类装载器的引用。
- 到类class 的引用:虚拟机为每一个被装载的类型创建一个class 实例,用来代表这个被装载的类。
由此我们可以知道反射的基础:
| 在装载类的时候,加入方法区中的所有信息,最后都会形成Class类的实例,代表这个被装载的类。方法区中的所有的信息,都是可以通过这个Class类对象反射得到。我们知道对象是类的实例,类是相同结构的对象的一种抽象。同类的各个对象之间,其实是拥有相同的结构(属性),拥有相同的功能(方法),各个对象的区别只在于属性值的不同。 同样的,我们所有的类,其实都是Class类的实例,他们都拥有相同的结构-----Field数组、Method数组。而各个类中的属性都是Field属性的一个具体属性值,方法都是Method属性的一个具体属性值。 |
在运行时,JVM从常量池中获得符号引用,然后在运行时解析成引用项的实际地址,最后通过常量池中的全限定名、方法和字段描述符,把当前类或接口中的代码与其它类或接口中的代码联系起来。
1.2 Java栈
JVM栈是程序运行时单位,决定了程序如何执行,或者说数据如何处理。
在Java中,一个线程就会有一个线程的JVM栈与之对应,因为不过的线程执行逻辑显然不同,因此都需要一个独立的JVM栈来存放该线程的执行逻辑。
对方法的调用:
Java栈内存,以帧的形式存放本地方法的调用状态,包括方法调用的参数、局部变量、中间结果等(方法都是以方法帧的形式存放在方法区的),每调用一个方法就将对应该方法的方法帧压入Java 栈,成为当前方法帧。当调用结束(返回)时,就弹出该帧。
这意味着:
在方法中定义的一些基本类型的变量和引用变量都在方法的栈内存中分配。当在一段代码块定义一个变量时,Java 就在栈中为这个变量分配内存空间,当超过变量的作用域后(方法执行完成后),Java 会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作它用。--------同时,因为变量被释放,该变量对应的对象,也就失去了引用,也就变成了可以被gc对象回收的垃圾。
因此我们可以知道成员变量与局部变量的区别:
| 局部变量,在方法内部声明,当该方法运行完时,内存即被释放。 成员变量,只要该对象还在,哪怕某一个方法运行完了,还是存在。 从系统的角度来说,声明局部变量有利于内存空间的更高效利用(方法运行完即回收)。 成员变量可用于各个方法间进行数据共享。 |
Java 栈内存的组成:
局部变量区、操作数栈、帧数据区组成。
(1): 局部变量区为一个以字为单位的数组,每个数组元素对应一个局部变量的值。调用方法时,将方法的局部变量组成一个数组,通过索引来访问。若为非静态方法,则 加入一个隐含的引用参数this,该参数指向调用这个方法的对象。而静态方法则没有this参数。因此,对象无法调用静态方法。
由此,我们可以知道,方法什么时候设计为静态,什么时候为非静态?
| 前面已经说过,对象是类的一个实例,各个对象结构相同,只是属性不同。 而静态方法是对象无法调用的。 所以,静态方法适合那些工具类中的工具方法,这些类只是用来实现一些功能,也不需要产生对象,通过设置对象的属性来得到各个不同的个体。 |
(2):操作数栈也是一个数组,但是通过栈操作来访问。所谓操作数是那些被指令操作的数据。当需要对参数操作时如a=b+c,就将即将被操作的参数压栈,如将b 和c 压栈,然后由操作指令将它们弹出,并执行操作。虚拟机将操作数栈作为工作区。
(3):帧数据区处理常量池解析,异常处理等
1.3 java堆
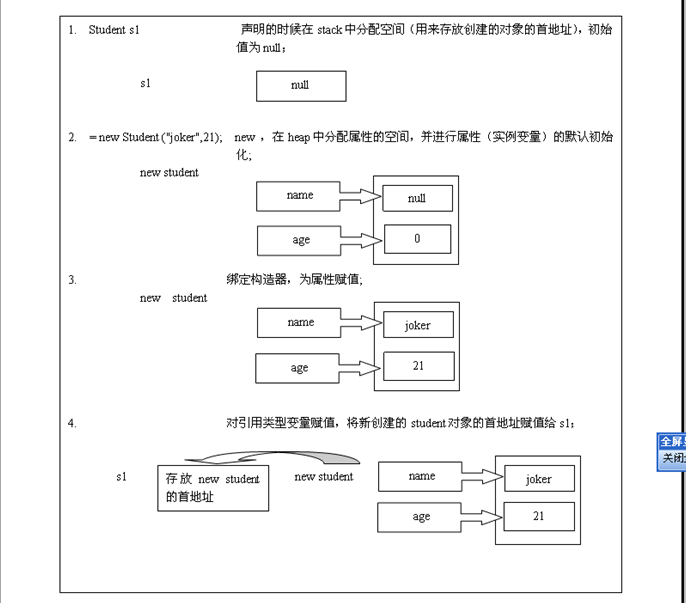
java的堆是一个运行时的数据区,用来存储数据的单元,存放通过new关键字新建的对象和数组,对象从中分配内存。
在堆中声明的对象,是不能直接访问的,必须通过在栈中声明的指向该引用的变量来调用。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
由此我们可以知道,引用类型变量和对象的区别:
|
声明的对象是在堆内存中初始化的, 真正用来存储数据的。不能直接访问。 引用类型变量是保存在栈当中的,一个用来引用堆中对象的符号而已(指针)。 |
堆与栈的比较:
JAVA堆与栈都是用来存放数据的,那么他们之间到底有什么差异呢?既然栈也能存放数据,为什么还要设计堆呢?
1.从存放数据的角度:
前面我们已经说明:
栈中存放的是基本类型的变量or引用类型的变量
堆中存放的是对象or数组对象.
在栈中,引用变量的大小为32位,基本类型为1-8个字节。
但是对象的大小和数组的大小是动态的,这也决定了堆中数据的动态性,因为它是在运行时动态分配内存的,生存期也不必在编译时确定,Java 的垃圾收集器会自动收走这些不再使用的数据。
2.从数据共享的角度:
1).在单个线程类,栈中的数据可共享
例如我们定义:
- int a=3;
- int b=3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a 的引用,然后查找栈中是否有3 这个值,如果没找到,就将3 存放进来,然后将a 指向3。接着处理int b = 3;在创建完b 的引用变量后,因为在栈中已经有3这个值,便将b 直接指向3。这样,就出现了a 与b 同时均指向3的情况。
而如果我们定义:
- Integer a=new Integer(128);//(1)
- Integer b=new Integer(128);//(2)
这个时候执行过程为:在执行(1)时,首先在栈中创建一个变量a,然后在堆内存中实例化一个对象,并且将变量a指向这个实例化的对象。在执行(2)时,过程类似,此时,在堆内存中,会有两个Integer类型的对象。
2).在进程的各个线程之间,数据的共享通过堆来实现
例:那么,在多线程开发中,我们的数据共享又是怎么实现的呢?
堆中的数据是所有线程栈所共享的,我们可以通过参数传递,将一个堆中的数据传入各个栈的工作内存中,从而实现多个线程间的数据共享
(多个进程间的数据共享则需要通过网络传输了。)
3.从程序设计的的角度:
从软件设计的角度看,JVM栈代表了处理逻辑,而JVM堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
4.值传递和引用传递的真相
有了以上关于栈和堆的种种了解后,我们很容易就可以知道值传递和引用传递的真相:
|
1.程序运行永远都是在JVM栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题。不会直接传对象本身。 但是传引用的错觉是如何造成的呢? 在运行JVM栈中,基本类型和引用的处理是一样的,都是传值,所以,如果是传引用的方法调用,也同时可以理解为“传引用值”的传值调用,即引用的处理跟基本类型是完全一样的。 但是当进入被调用方法时,被传递的这个引用的值,被程序解释(或者查找)到JVM堆中的对象,这个时候才对应到真正的对象。 如果此时进行修改,修改的是引用对应的对象,而不是引用本身,即:修改的是JVM堆中的数据。所以这个修改是可以保持的了。 |
最后:
从某种意义上来说对象都是由基本类型组成的。
| 可以把一个对象看作为一棵树,对象的属性如果还是对象,则还是一颗树(即非叶子节点),基本类型则为树的叶子节点。程序参数传递时,被传递的值本身都是不能进行修改的,但是,如果这个值是一个非叶子节点(即一个对象引用),则可以修改这个节点下面的所有内容。 |
其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。
面向对象的引入,只是改变了我们对待问题的思考方式,而更接近于自然方式的思考。
当我们把对象拆开,其实对象的属性就是数据,存放在JVM堆中;而对象的行为(方法),就是运行逻辑,放在JVM栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。