Mycat
- 数据库中间件
- 一个彻底开源的,面向企业应用开发的大数据库集
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
- 用来干什么
- 用于支持海量数据存储,对海量数据进行分库分表
- 支持分库分表场景下的分布式事务
- 对多个数据源进行统一整合
- 高并发应用场景下,降低请求对单个数据库节点带来的灾难性压力
- 可以通过数据库中间间层面实现数据库读写分离,使其Java程序与数据库访问解耦
- 特性
- 数据读写分离

- 数据分片

- 多数据源整合
- 数据读写分离
Mycat入门概述
是什么
Mycat是数据库中间件
-
数据库中间件
-
中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通
例如:Tomcat,web中间件
-
数据库中间件:连接java应用程序和数据库
-
-
数据库中间件对比
| 数据库中间件 | 说明 |
|---|---|
| Cobar | Cobar属于阿里B2B事业群,始于2008年,在阿里服役3年多,接管3000+个MySQL数据库的schema,集群日处理在线SQL请求50亿次以上。由于Cobar发起人的离职,Cobar停止维护 |
| Mycat | Mycat是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新的功能在其中,青出于蓝而胜于蓝 |
| OneProxy | OneProxy基于MySQL官方的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件。舍弃了一些功能,专注在性能和稳定性上 |
| kingshard | kingshard由小团队用go语言开发,还需要发展,需要不断完善 |
| Vitess | Vitess是Youtube生产在使用,架构很复杂。不支持MySQL原生协议,使用需要大量改造成本 |
| Atlas | Atlas是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定 |
| MaxScale | MaxScale是mariadb(MySQL原作者维护的一个版本) 研发的中间件 |
| MySQLRoute | MySQLRoute是MySQL官方Oracle公司发布的中间件 |
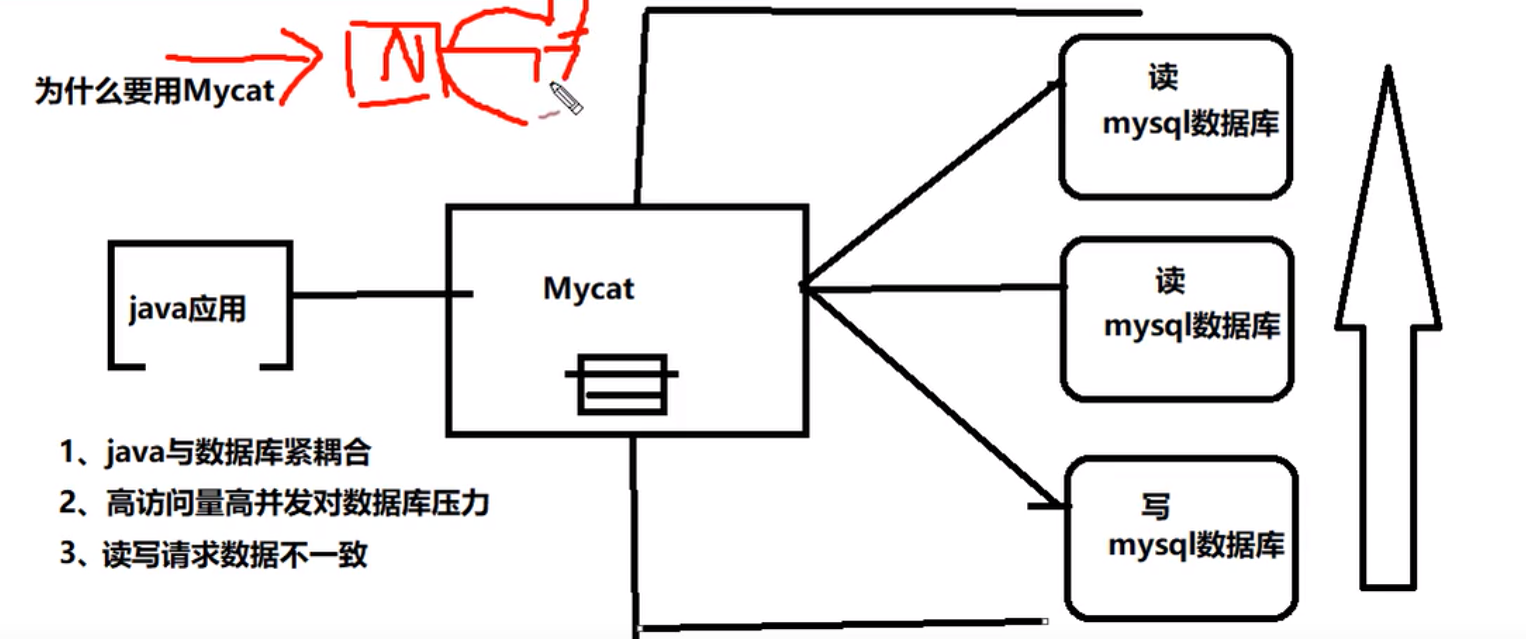
为什么要用MyCat
-
Java与数据库耦合
-
高并发高访问量对数据库压力大
-
读写请求数据不一致
Mycat官网
干什么
读写分离
数据分片
垂直拆分(分库)
水平拆分(分表)
垂直+水平拆分(分库分表)
多数据源整合
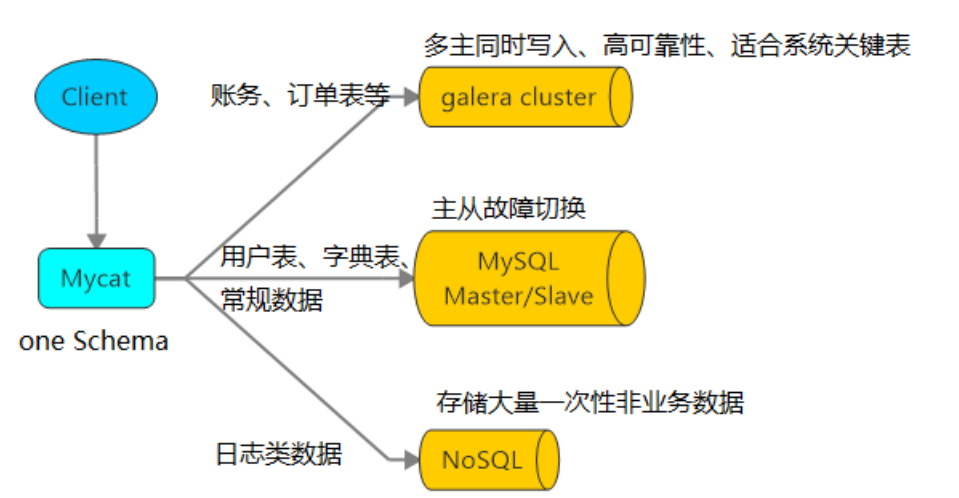
原理
-
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户
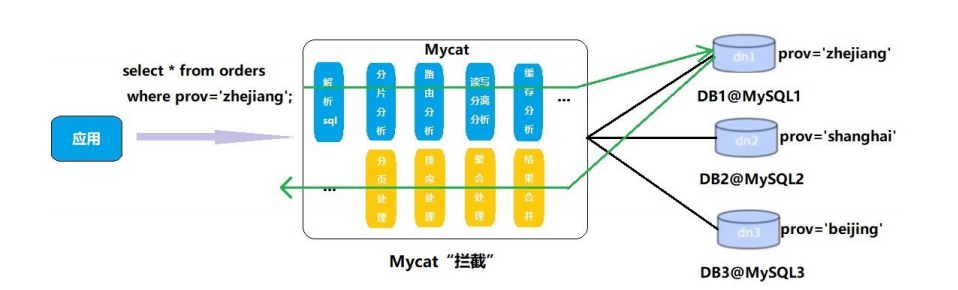
这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用Mycat还是MySQL
安装启动
安装
下载
-
linux环境下 下载tar.gz 这里示例用的是1.6.7.1
-
# 解压 # z:指定gz压缩包 # x:指明解压操作 # v:信息展示 # f:指定要解压的文件 tar -zxvf Mycat-server-1.6.7.1-release-20190627191042-linux.tar.gz
主要配置文件
-
conf 目录下
-
schema.xml:定义逻辑库,表、分片节点等内容 -
rule.xml:定义分片规则 -
server.xml:定义用户以及系统相关变量,如端口等
-
启动
修改配置文件server.xml
-
conf 目录下的
server.xml文件,便于和mysql作区分#conf目录 cd /usr/local/mycat/mycat/conf/ #修改server.xml vim server.xml修改mycat默认的用户root为mycat,区分mysql的root用户
修改配置文件schema.xml
-
删除
标签间的表信息, 标签只留一个, 标签只留一个, 只留一对 -
最终效果
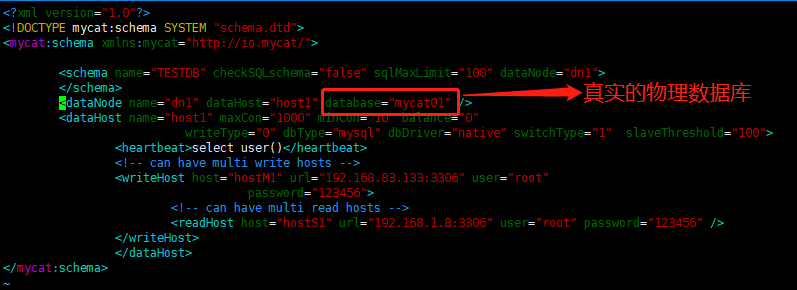
-
建议启动两到三个mysql服务
验证数据库访问情况
-
Mycat 作为数据库中间件要和数据库部署在不同机器上,所以要验证远程访问情况
mysql -uroot -p123456 -h 192.168.1.8 -P 3306 mysql -uroot -p123456 -h 192.168.83.133 -P 3306
启动Mycat
-
为了能第一时间看到启动日志,方便定位问题,我们选择控制台启动的方式
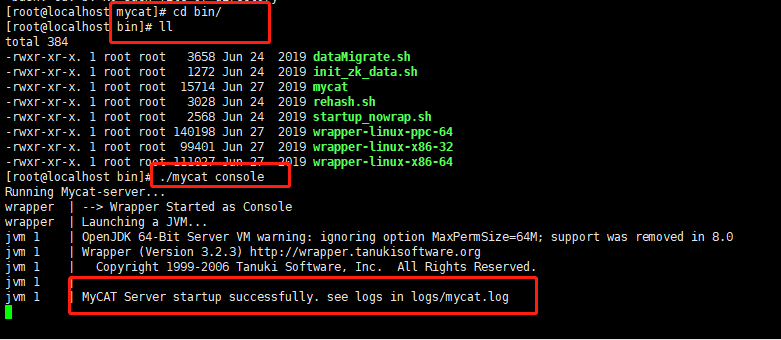
控制台启动
- mycat/bin 目录下执行 ./mycat console
后台启动
- mycat/bin 目录下 ./mycat start
登录
登录后台管理窗口
-
此登录方式用于管理维护Mycat,管理窗口默认端口9066以及Mycat服务所在的IP地址
mysql -umycat -p -P 9066 -h 192.168.83.133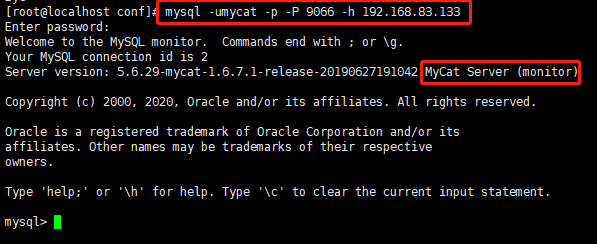
-
show databases:配置的逻辑数据库名 -
show @@help:帮助命令 -
show @@heartbeat:心跳检测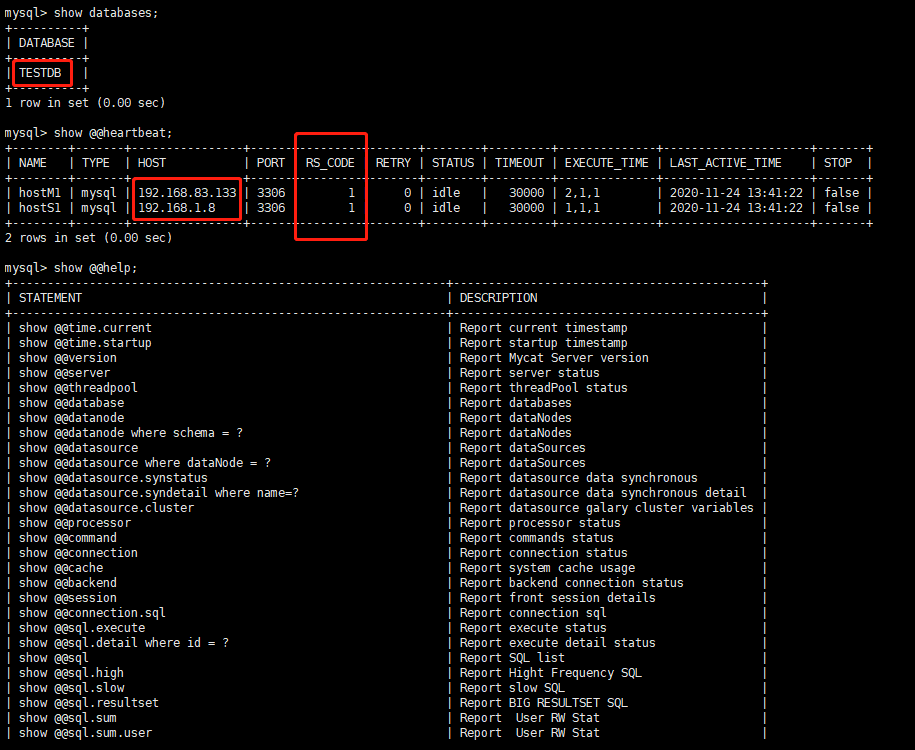
-
登录数据窗口
-
此登录方式用于通过 Mycat 查询数据,数据窗口默认端口8066以及Mycat服务所在的IP地址
mysql -umycat -p -P 8066 -h 192.168.83.133
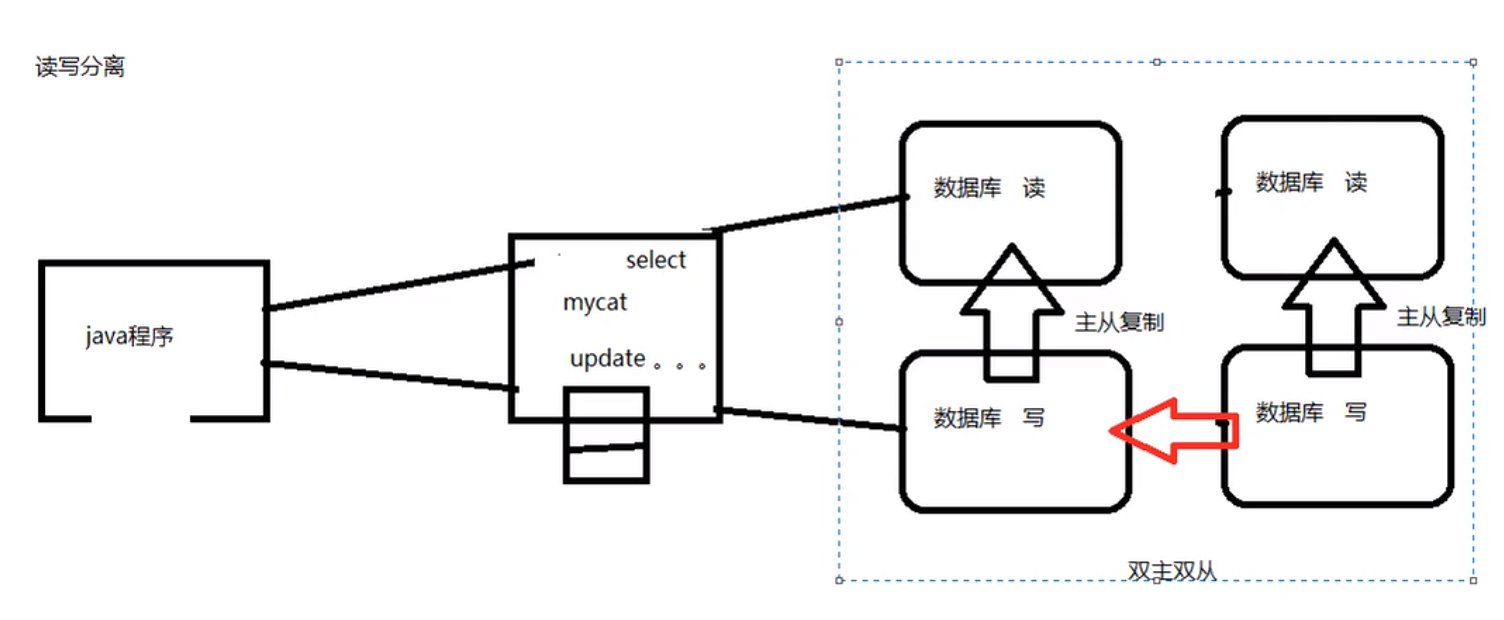
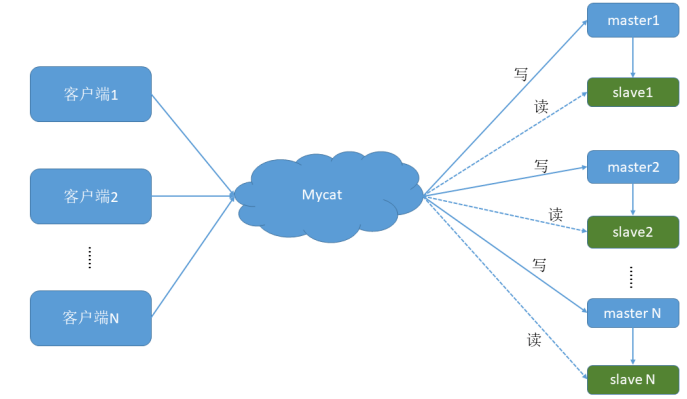
搭建读写分离
- 通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写分离,实现 MySQL 的高可用性
一主一从
架构
- 一个主机用于处理所有写请求,一台从机负责所有读请求,架构图如下
MySQL主从复制原理
- 二进制日志文件进行复制
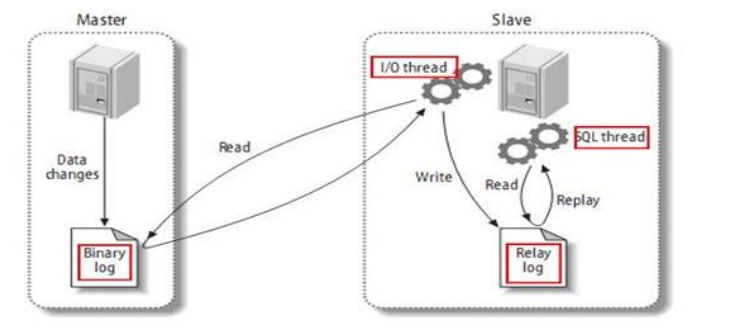
- 区别与redis的主从复制,MySQL主从复制是从日志文件的切入点开始复制,而Redis是从头开始复制
docker容器之间互访问
-
多个容器之间如何互相访问,默认情况下容器之间本身可以通过 docker0 网桥分配的 IP 地址互访,但由于无法固定 IP,日常使用起来并不方便
-
Docker 本身也有一个 link 指令,可以用于连接两个容器,但这命令的缺点是只能单向连接,也就是 A 和 B 两个容器,只能 A 访问 B 或者 B 访问 A,做不到 AB 之间直接同时互访
-
因此一般情况下,更推荐使用创建新网络的方法来配置容器,创建新网络的指令格式为
docker network create -d bridge newnet-d 就不是后台运行的意思了,而是指定网络类型的,意思是创建的新网络类型为 bridge,命名为 newnet
-
-
创建新的网络
docker network create --subnet=172.18.1.0/24 newnet-
查看网络,可以看到新创建的网络
docker network ls
-
-
创建完了网络之后,如果需要指定容器使用对应的网络,则只需创建时加上
--network和--ip指令即可,如下创建mysql容器docker run --name mysql3307 --network newnet --ip 172.18.1.37 -p 3307:3306 -v /var/mycatVolume/mysql3307/data:/var/lib/mysql -v /var/mycatVolume/mysql3307/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31 -
docker inspect容器ID 查看网络信息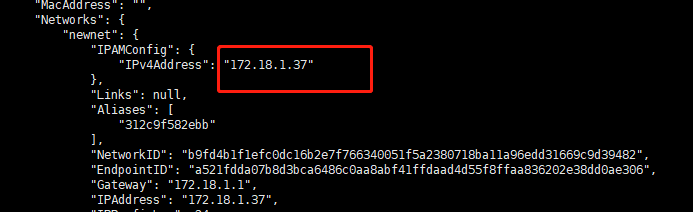
-
docker启动多个mysql服务
建立统一的通信,保证容器之间可以互相访问
-
mysql新建文件夹和配置文件,新建本地文件
mkdir -p /var/mycatVolume/mysql3307/data mkdir -p /var/mycatVolume/mysql3307/conf #conf目录下创建 my.cnf touch my.cnf -
my.cnf内容如下[mysqld] #主服务器唯一ID server-id=1 #启用二进制日志 log-bin=mysql-bin
-
-
创建mysql容器 3307、3308
#3307 docker run --name mysql3307 -p 3307:3306 --network newnet --ip 172.18.1.37 -v /var/mycatVolume/mysql3307/data:/var/lib/mysql -v /var/mycatVolume/mysql3307/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31 #3308 docker run --name mysql3308 -p 3308:3306 --network newnet --ip 172.18.1.38 -v /var/mycatVolume/mysql3308/data:/var/lib/mysql -v /var/mycatVolume/mysql3308/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31
主从配置
-
第一步:主机修改配置文件
/var/mycatVolume/mysql3307/conf目录下my.cnf[mysqld] #主服务器唯一ID server-id=17 #启用二进制日志 log-bin=mysql-bin #设置不需要复制的数据库(可设置多个) #binlog-ignore-db=mysql #binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=ms03 -
第二步:从机修改配置文件
/var/mycatVolume/mysql3308/conf目录下my.cnf[mysqld] #服务器唯一ID server-id=18 #启用中继日志 relay-log=mysql-relay -
第三步:修改
my.cnf配置后,必须重启MySQL服务 -
第四步:在主机上建立账户并授权slave
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123';-
查询master的状态
show master status;记录下File和Position的值;执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化

-
-
第五步:在从机上配置需要复制的主机
#复制主机的命令 CHANGE MASTER TO MASTER_HOST='172.18.1.37', MASTER_USER='slave', MASTER_PASSWORD='123123', MASTER_LOG_FILE='mysql-bin.000010', MASTER_LOG_POS=154, master_port=3306;-
启动从机复制功能
start slave; -
停止从机复制功能
start slave; -
重置从机配置
stop slave; reset slave; -
查看从机状态
show slave statusG;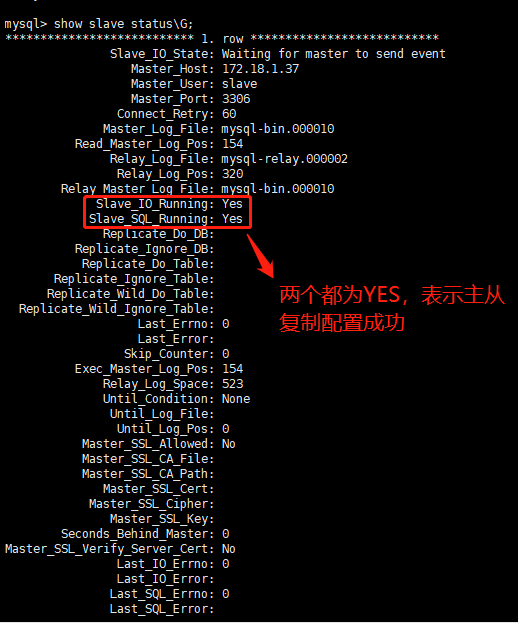
-
-
第六步:验证主从复制是否有效
-
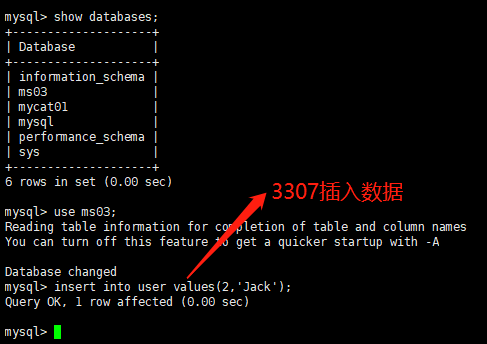
向 ms03中的user表插入数据
-
Mycat实现读写分离
-
第一步:准备工作
vim mycat/conf目录下的schema.xml,查看Mycat读写分离配置<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="host1" database="ms03" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.83.133:3307" user="root" password="123456"> <!-- can have multi read hosts --> <readHost host="hostS1" url="192.168.83.133:3308" user="root" password="123456" /> </writeHost> </dataHost> </mycat:schema>- 3307 主机创建/选择数据库ms03,并新建表 mytbl
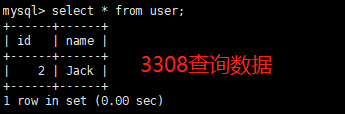
use ms03; create table mytbl(id int,name varchar(20)); insert into mytbl values(1,'z3'); select * from mytbl;- 从机查询是否复制成功
-
第二步:启动Mycat服务

-
第三步:登录Mycat数据窗口 8066
mysql -umycat -h 192.168.83.133 -P 8066 -p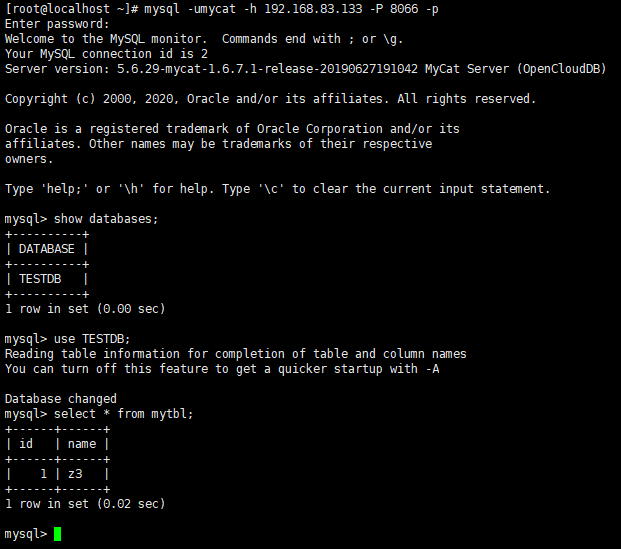
-
第四步:验证是否读写分离
-
在从机中插入,目的让主从数据不一致
insert into mytbl values (4,'only');
可以看出此时并没有实现主机写操作,从机读操作的功能
-
修改Mycat配置文件,
vim mycat/conf目录下的schema.xml,修改的balance属性,通过此属性配置读写分离的类型 负载均衡类型,目前取值有4种:
- 第一种:balance="0",不开启读写分离机制,所有读操作都发送到当前可用的writeHost 上
- 第二种:balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单地说,当双主双从模式(M1->S1,M2->S2,并且M1与M2 互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡
- 第三种:balance="2",所有的读操作都随机的在writeHost、readHost 上分发
- 第四种:balance="3",所有读请求随机的分发到readhost执行,writeHost不负担读压力
-
将
schema.xml中的balance属性改为2,重启Mycat server可以看到读请求,被随机分发到主从机上
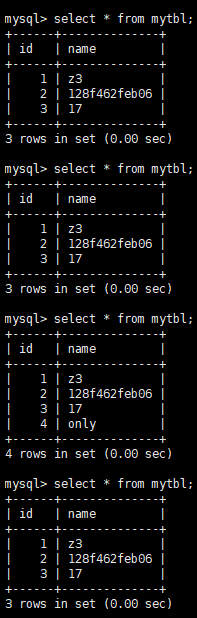
-
双主双从
-
一个主机m1用于处理所有写请求,它的从机s1和另外一台主机m2还有它的从机s2负责所有读请求。当m1宕机后,m2主机负责写请求,m1、m2互为备机。架构图如下:
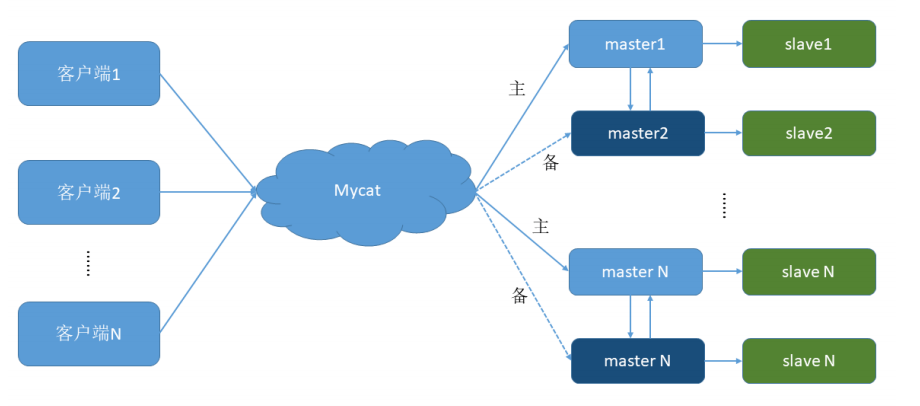
-
组成
3307和3317作为双主机
3308和3318作为双从机
-
双主机配置
-
3307 Master1的配置
#主服务器唯一ID server-id=7 #启用二进制日志 log-bin=mysql-bin #设置不需要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=ms03 #设置logbin格式 binlog_format=STATEMENT #在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates #表示自增长字段每次递增的量,指自增长字段的起始值,其默认值是1,取值范围是1 ...65535 auto-increment-increment=2 #表示自增长字段从那个数开始,指字段一次递增多少,它的取值范围是1...65535 auto-increment-offset=1 -
3317 Master2的配置
#主服务器唯一ID server-id=17 #启用二进制日志 log-bin=mysql-bin #设置不需要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=ms03 #设置logbin格式 binlog_format=STATEMENT #在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates #表示自增长字段每次递增的量,指自增长字段的起始值,其默认值是1,取值范围是1 ...65535 auto-increment-increment=2 #表示自增长字段从那个数开始,指字段一次递增多少,它的取值范围是1...65535 auto-increment-offset=2
双从机配置
-
3308
[mysqld] #服务器唯一ID server-id=8 #启用中继日志 relay-log=mysql-relay -
3318
[mysqld] #服务器唯一ID server-id=18 #启用中继日志 relay-log=mysql-relay
启动四个mysql容器
docker run --name mysql3307 -p 3307:3306 --network newnet --ip 172.18.1.7 -v /var/mycatVolume/mysql3307/data:/var/lib/mysql -v /var/mycatVolume/mysql3307/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31
docker run --name mysql3308 -p 3308:3306 --network newnet --ip 172.18.1.8 -v /var/mycatVolume/mysql3308/data:/var/lib/mysql -v /var/mycatVolume/mysql3308/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31
docker run --name mysql3317 -p 3317:3306 --network newnet --ip 172.18.1.17 -v /var/mycatVolume/mysql3317/data:/var/lib/mysql -v /var/mycatVolume/mysql3317/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31
docker run --name mysql3318 -p 3318:3306 --network newnet --ip 172.18.1.18 -v /var/mycatVolume/mysql3318/data:/var/lib/mysql -v /var/mycatVolume/mysql3318/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31
-
在两台主机上建立账户并授权 slave
#在主机MySQL里执行授权命令 GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123'; #查询Master1的状态 show master status; #分别记录下File和Position的值 #执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化-
Master1
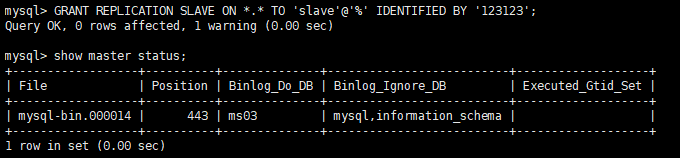
-
Master2

-
-
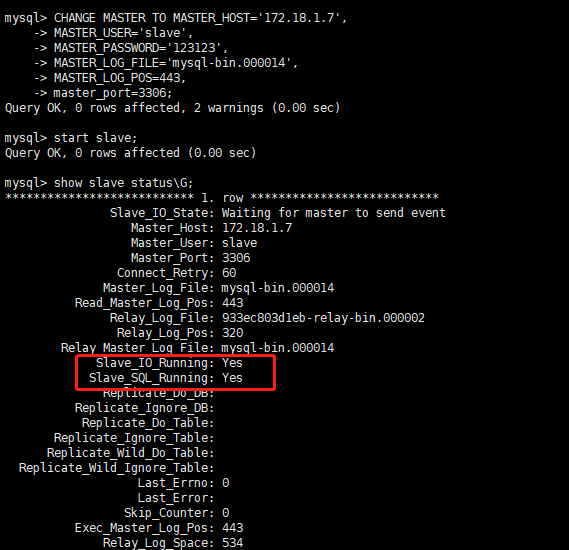
在从机上配置需要复制的主机
#复制主机的命令 CHANGE MASTER TO MASTER_HOST='主机的IP地址', MASTER_USER='slave', MASTER_PASSWORD='123123', MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;-
Slave1的复制命令
#复制主机1的命令 CHANGE MASTER TO MASTER_HOST='172.18.1.7', MASTER_USER='slave', MASTER_PASSWORD='123123', MASTER_LOG_FILE='mysql-bin.000014', MASTER_LOG_POS=443, master_port=3306; -
Slave2的复制命令
#复制主机2的命令 CHANGE MASTER TO MASTER_HOST='172.18.1.17', MASTER_USER='slave', MASTER_PASSWORD='123123', MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=732, master_port=3306; -
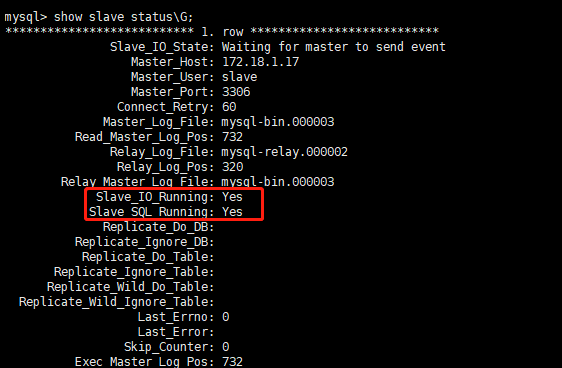
启动从机复制功能和查看从机服务状态
#启动两台从服务器复制功能 start slave; #查看从服务器状态 show slave statusG;下面两个参数都是Yes,则说明主从配置成功!
Slave_IO_Running: Yes ,Slave_SQL_Running: Yes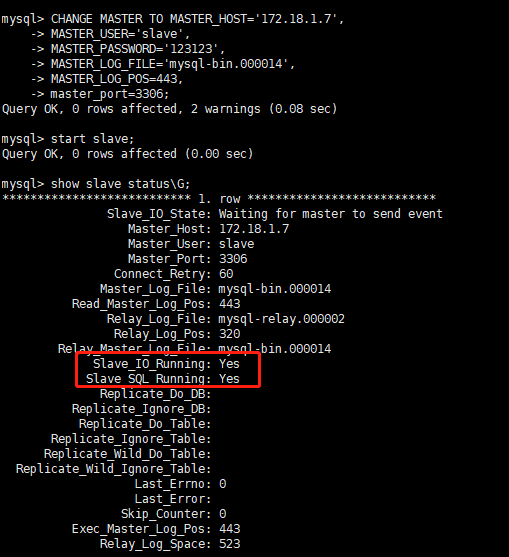
-
两个主机互相复制
-
Master2复制 Master1,Master1复制Master2
#Master2 CHANGE MASTER TO MASTER_HOST='172.18.1.7', MASTER_USER='slave', MASTER_PASSWORD='123123', MASTER_LOG_FILE='mysql-bin.000014', MASTER_LOG_POS=443, master_port=3306;#Master1 CHANGE MASTER TO MASTER_HOST='172.18.1.17', MASTER_USER='slave', MASTER_PASSWORD='123123', MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=732, master_port=3306; #启动两台主服务器复制功能 start slave; #查看从服务器状态 show slave statusG;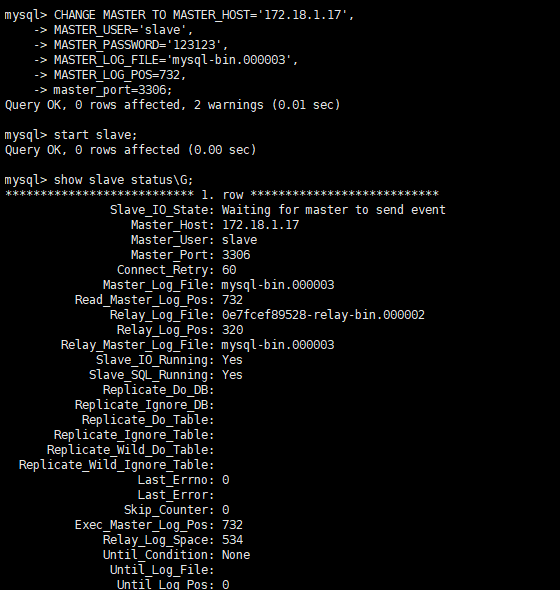
验证双主双从
-
Master1 主机新建库、新建表、insert记录,Master2和从机复制
create table doublems(id int,name varchar(50)); insert into doublems values(1,'touchair');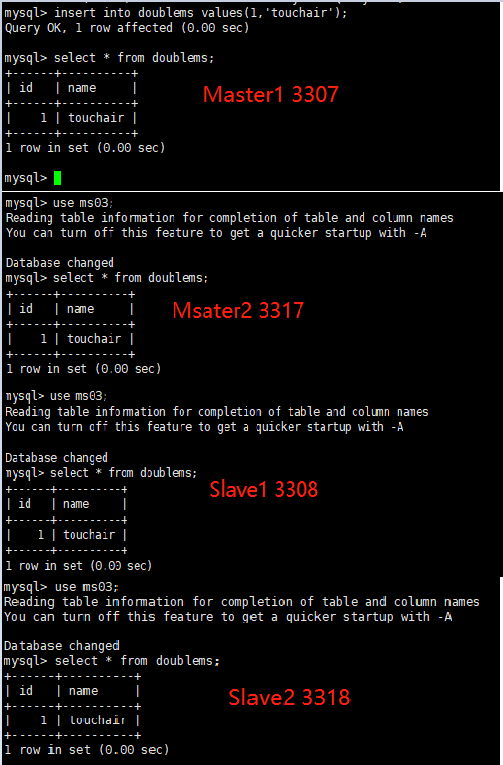
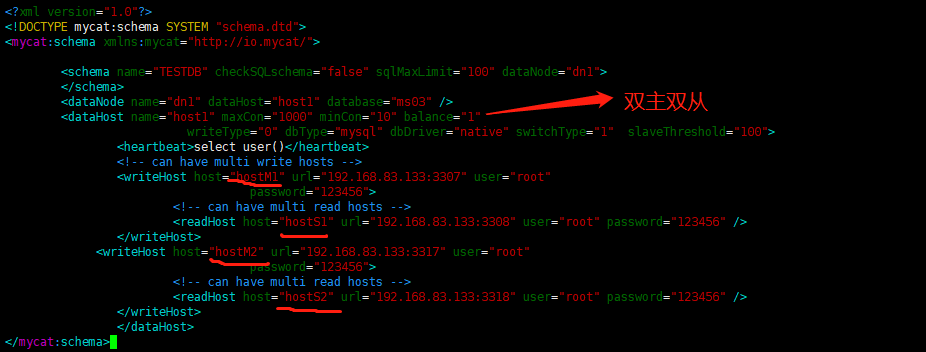
修改Mycat的配置文件
-
修改
的balance属性,通过此属性配置读写分离的类型 <?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="host1" database="ms03" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.83.133:3307" user="root" password="123456"> <!-- can have multi read hosts --> <readHost host="hostS1" url="192.168.83.133:3308" user="root" password="123456" /> </writeHost> <writeHost host="hostM2" url="192.168.83.133:3317" user="root" password="123456"> <!-- can have multi read hosts --> <readHost host="hostS2" url="192.168.83.133:3318" user="root" password="123456" /> </writeHost> </dataHost> </mycat:schema>- balance="1": 全部的readHost与stand by writeHost参与select语句的负载均衡
- writeType="0": 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二
- writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
- writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties
- switchType="1": 1 默认值,自动切换、-1 表示不自动切换、2 基于 MySQL 主从同步的状态决定是否切换
验证读写分离
-
在写主机Master1数据库表doublems中插入带系统变量数据,造成主从数据不一致
INSERT INTO doublems VALUES(2,@@server_id);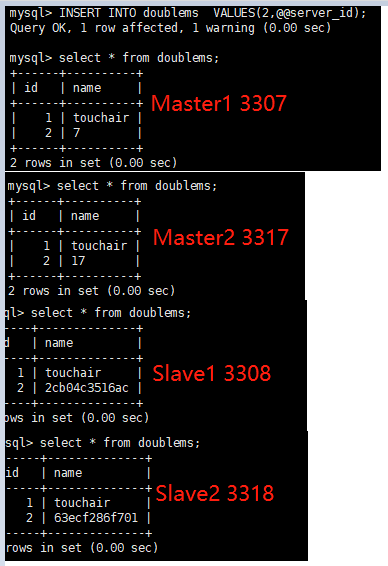
-
启动Mycat,在Mycat的数据窗口验证读写分离
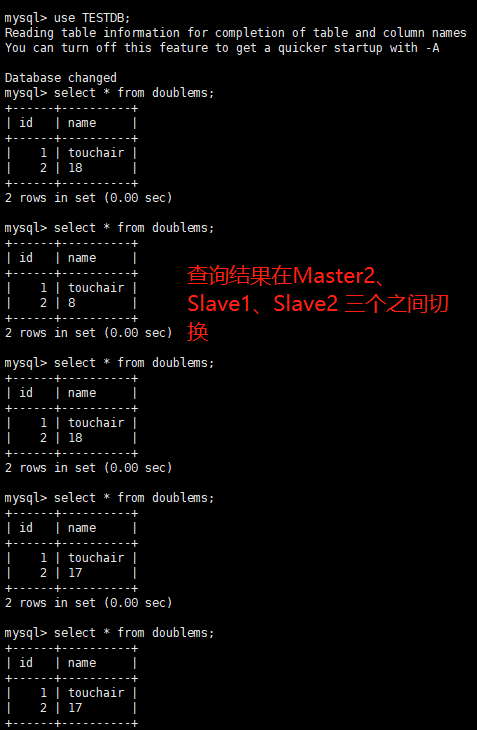
抗风险能力
-
停止Master1之后,再Mycat中尝试插入数据
在Mycat中依然可以插入数据,Master2自动切换为主机,Slave1与Slave2复制读操作
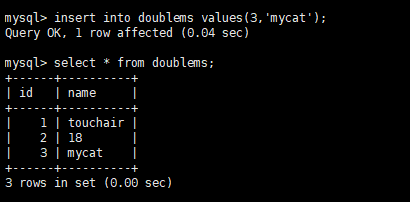
-
此时再重新启动Master1
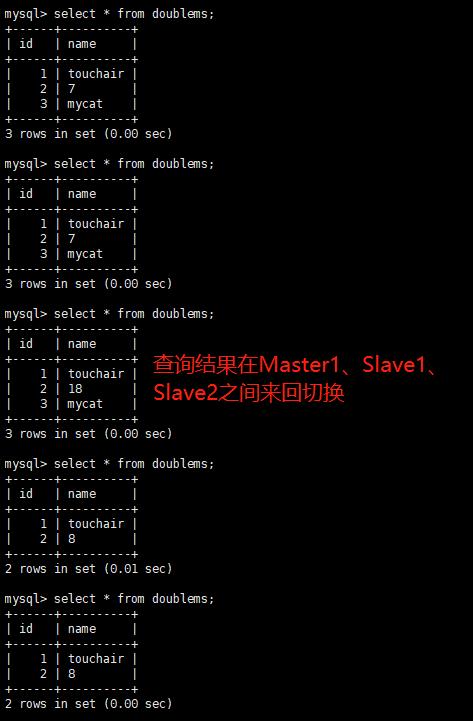
-
Master1、Master2 互做备机,负责写的主机宕机,备机切换负责写操作,保证数据库读写分离高可用性
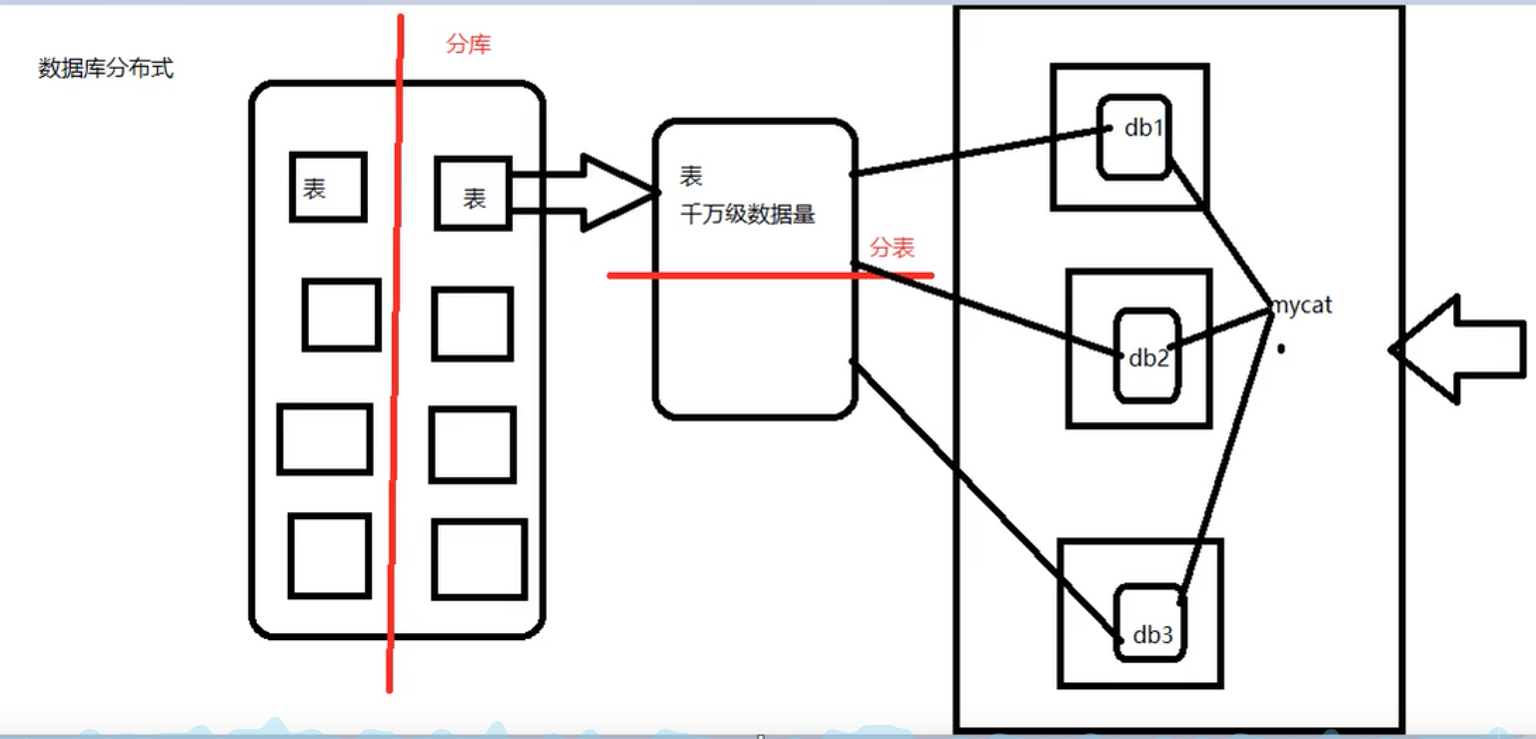
垂直拆分——分库
-
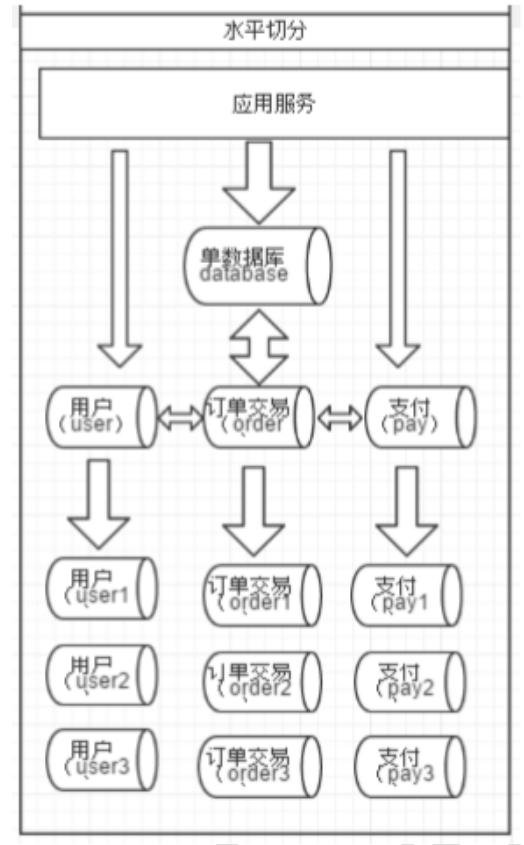
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
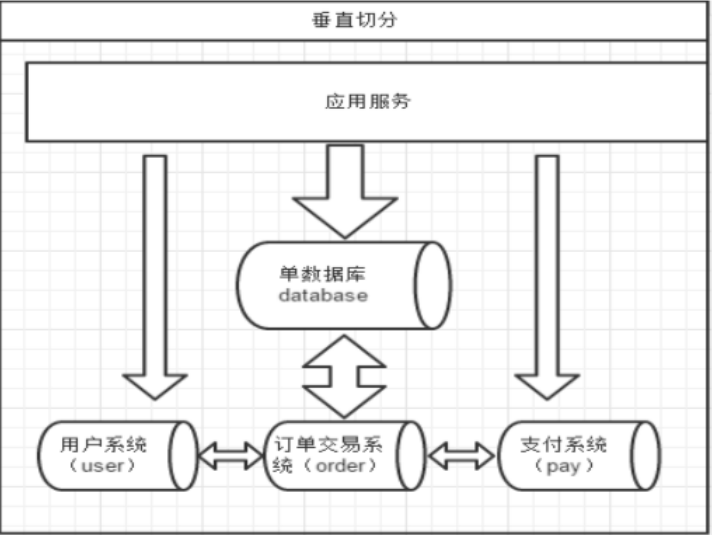
系统被切分成了用户、订单交易、支付几个模块
如何划分表
-
一个问题:在两台主机上的两个数据库中的表,能否关联查询?
答案:不可以
划分原则
-
分库的原则:有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里
-
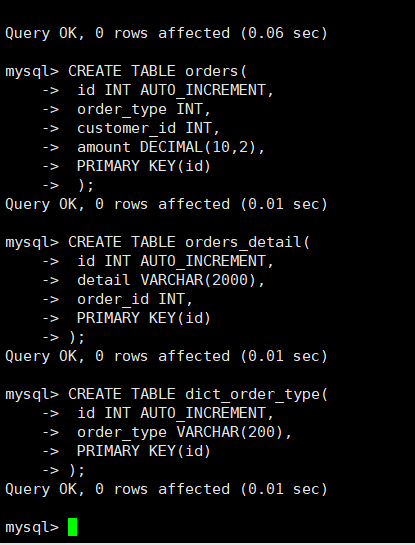
#在Mycat中执行 #客户表 rows:20万 CREATE TABLE customer( id INT AUTO_INCREMENT, NAME VARCHAR(200), PRIMARY KEY(id) ); #订单表 rows:600万 CREATE TABLE orders( id INT AUTO_INCREMENT, order_type INT, customer_id INT, amount DECIMAL(10,2), PRIMARY KEY(id) ); #订单详细表 rows:600万 CREATE TABLE orders_detail( id INT AUTO_INCREMENT, detail VARCHAR(2000), order_id INT, PRIMARY KEY(id) ); #订单状态字典表 rows:20 CREATE TABLE dict_order_type( id INT AUTO_INCREMENT, order_type VARCHAR(200), PRIMARY KEY(id) ); -
以上四个表如何分库?
客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库
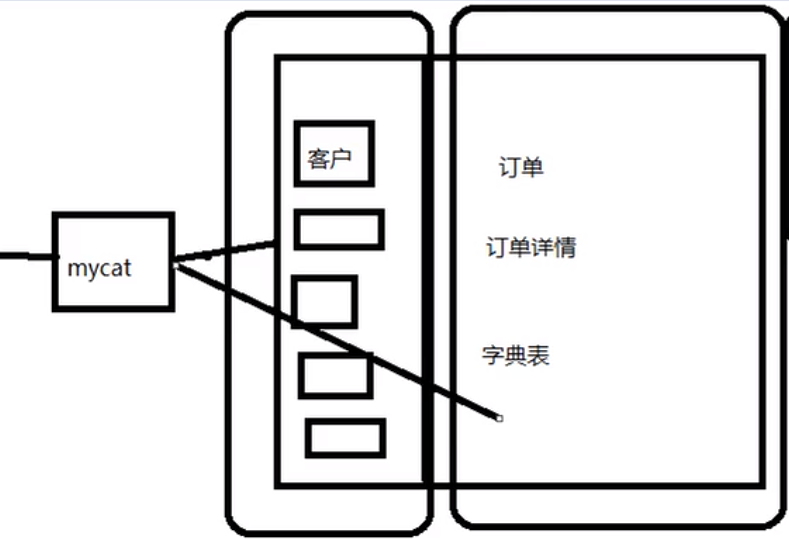
我们只需要连上数据库中间件Mycat,然后Mycat去访问不同的数据库
-
Mycat实现分库原理
- Mycat核心:拦截SQL——SQL语义分析———转发
实现分库
-
修改Mycat配置文件
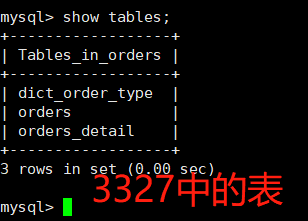
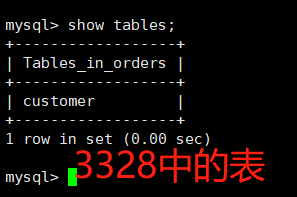
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> <table name="customer" dataNode="dn2" ></table> </schema> <dataNode name="dn1" dataHost="host1" database="orders" /> <dataNode name="dn2" dataHost="host2" database="orders" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.83.133:3327" user="root" password="123456"> </writeHost> </dataHost> <dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM2" url="192.168.83.133:3328" user="root" password="123456"> </writeHost> </dataHost> </mycat:schema>customer表相关的走dn2数据库 3328 节点,其余都走dn1数据库 3327节点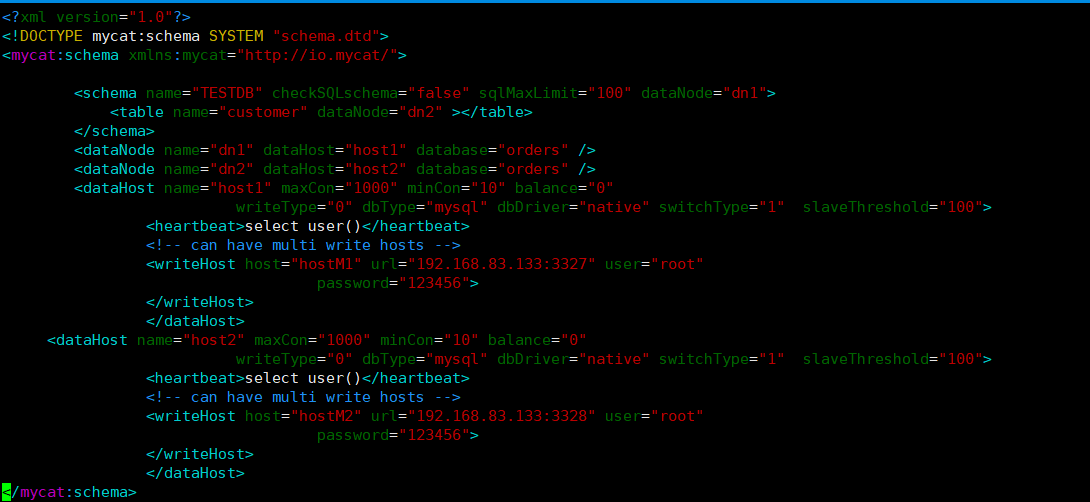
-
启动Mysql服务 3327,3328,并新建两个空白数据库orders
#3327 docker run --name mysql3327 -p 3327:3306 --network newnet --ip 172.18.1.27 -v /var/mycatVolume/mysql3327/data:/var/lib/mysql -v /var/mycatVolume/mysql3327/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31 #3328 docker run --name mysql3328 -p 3328:3306 --network newnet --ip 172.18.1.28 -v /var/mycatVolume/mysql3328/data:/var/lib/mysql -v /var/mycatVolume/mysql3328/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7.31 #创建数据库orders create database orders; -
在Mycat中执行建表语句
#在Mycat中执行 #客户表 rows:20万 CREATE TABLE customer( id INT AUTO_INCREMENT, NAME VARCHAR(200), PRIMARY KEY(id) ); #订单表 rows:600万 CREATE TABLE orders( id INT AUTO_INCREMENT, order_type INT, customer_id INT, amount DECIMAL(10,2), PRIMARY KEY(id) ); #订单详细表 rows:600万 CREATE TABLE orders_detail( id INT AUTO_INCREMENT, detail VARCHAR(2000), order_id INT, PRIMARY KEY(id) ); #订单状态字典表 rows:20 CREATE TABLE dict_order_type( id INT AUTO_INCREMENT, order_type VARCHAR(200), PRIMARY KEY(id) );-
访问 Mycat:
mysql -umycat -p123456 -h 192.168.83.133 -P 8066切换到 TESTDB,创建4张表查看表信息,可以看到成功分库
-
水平拆分——分表
-
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
实现分表
选择要拆分的表
- MySQL单表存储数据条数是有瓶颈的,单表达到1000万条数据就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表)进行优化
- 例如:orders、order_detail都已经达到600万行数据,需要进行分表优化
分表字段
-
以ordes表为例,可以根据不同字段进行分表
分表字段 效果 id(主键、或创建时间) 查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个节点访问少,不平均 customer_id 根据客户id去分,两个节点访问平均,一个客户的所有订单都在同一个节点
修改配置文件 schema.xml
-
为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为
touchair_rule(自定义的名字)<table name="orders" dataNode="dn1,dn2" rule="touchair_rule" ></table>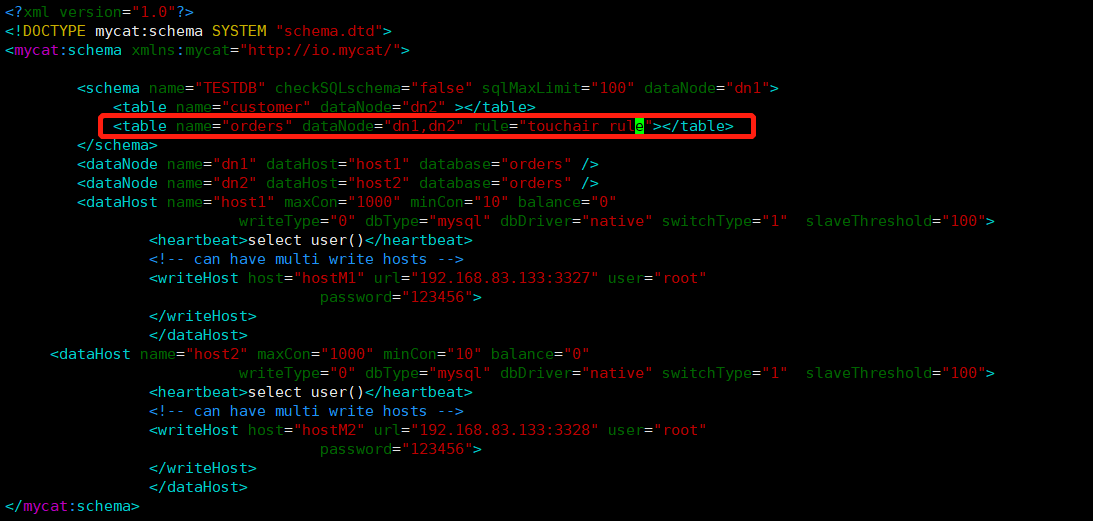
修改配置文件 rule.xml
-
在
rule配置文件里新增分片规则touchair_role,并指定规则适用字段为customer_id,还有选择分片算法mod-long(对字段求模运算),customer_id对两个节点求模,根据结果分片,配置算法mod-long参数count为2,两个节点<tableRule name="touchair_rule"> <rule> <columns>customer_id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">2</property> </function>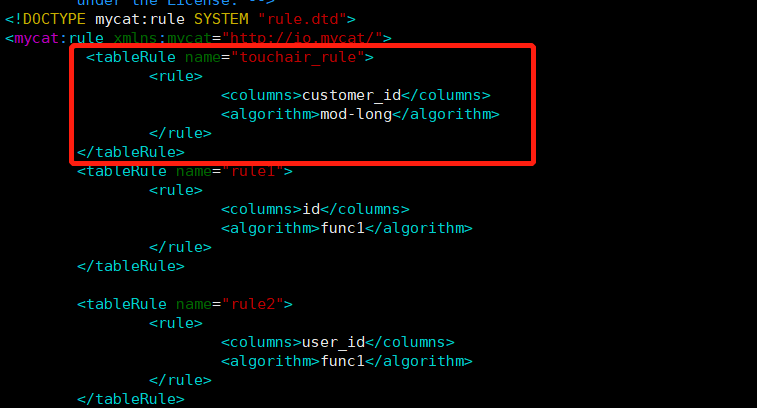
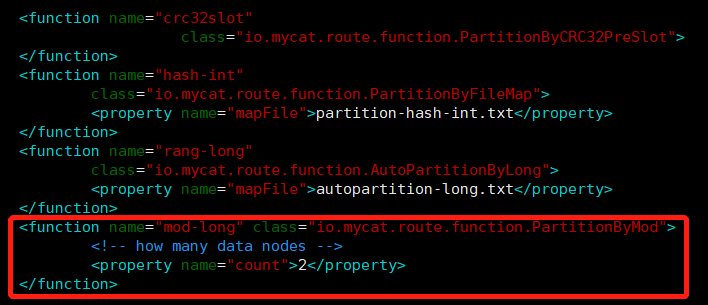
-
配置完成后,紧接着在dn2数据库节点 3328上,创建
orders表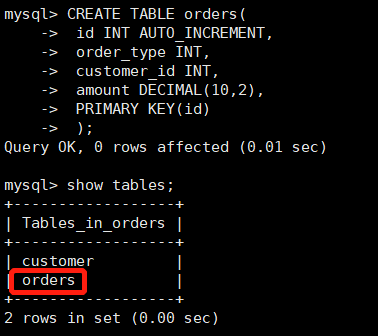
重启Mycat,让配置生效
访问Mycat实现分片
-
在Mycat里向orders表插入数据,INSERT字段不能省略
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100); INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300); INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000); INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000); INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400); INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);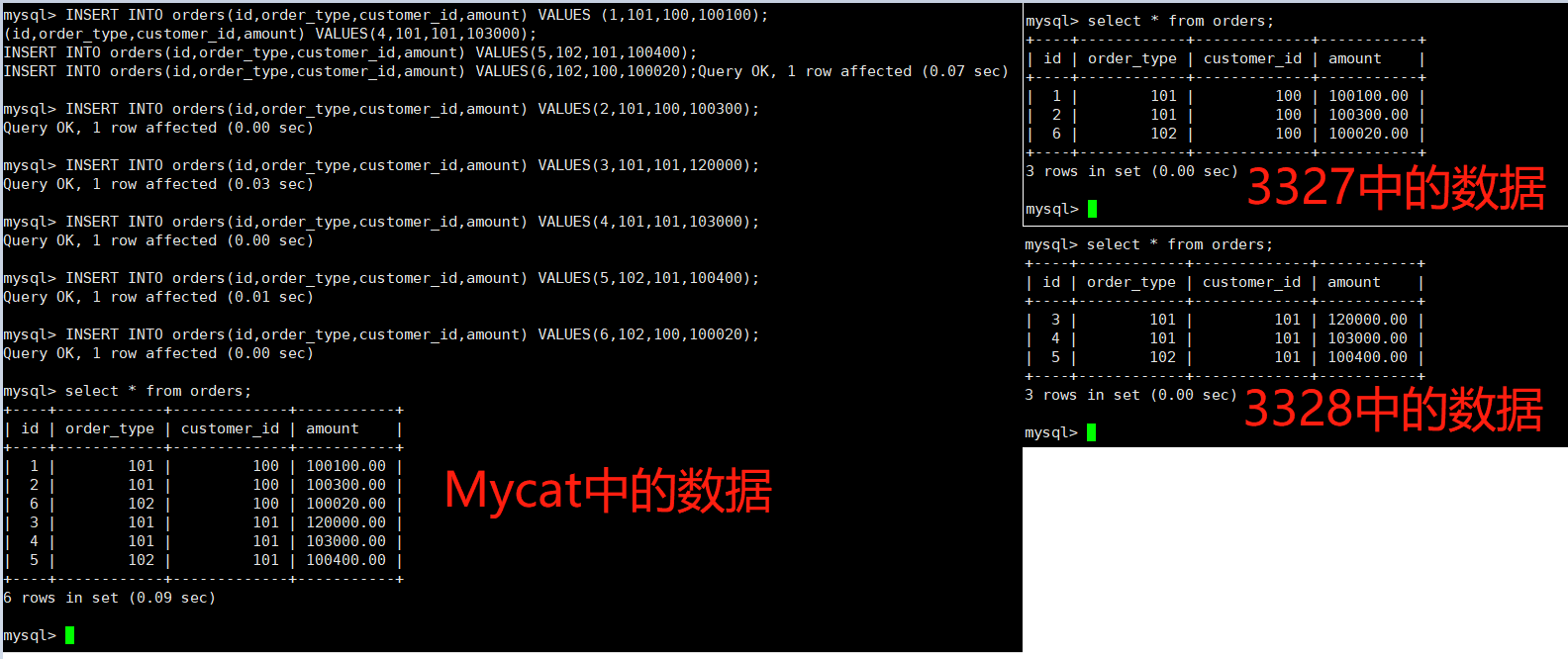
Mycat的分片 “join”
-
orders订单表已经进行分表操作了,和它关联的orders_detail订单详情表如何进行join查询
-
我们要对orders_detail也要进行分片操作,Join的原理如下图:
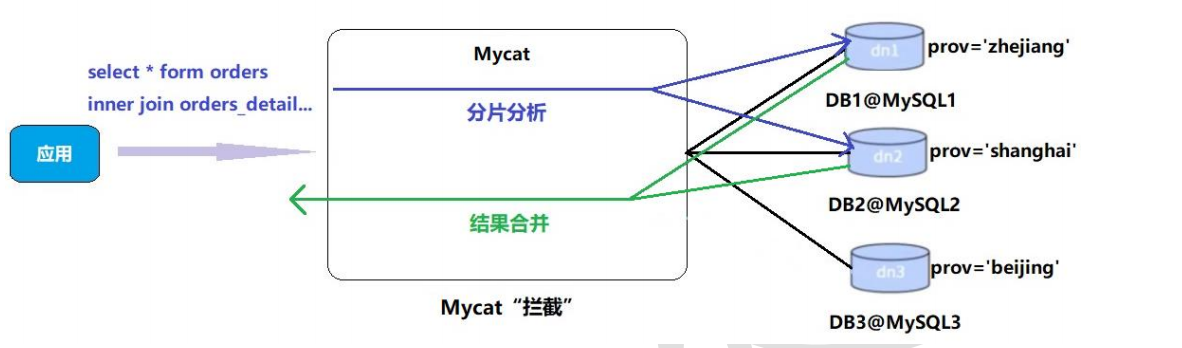
-
ER表
- Mycat借鉴了NewSQL领域的新秀 Foundation DB 的设计思路,Foundation DB创新性的提出了Table Group的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了JOIN的效率和性能问题,根据这一思路,提出了基于E-R关系的数据库分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上
修改配置文件 schema.xml
-
添加配置项
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
-
在 dn2上 创建
orders_detail表#订单详细表 CREATE TABLE orders_detail( id INT AUTO_INCREMENT, detail VARCHAR(2000), order_id INT, PRIMARY KEY(id) );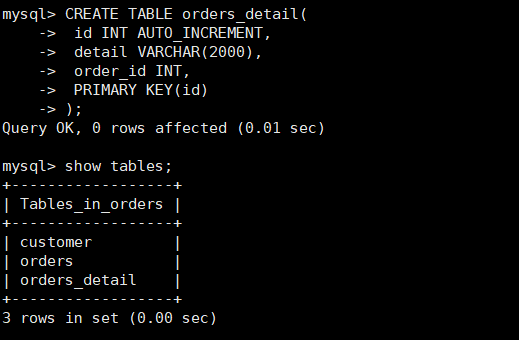
重启Mycat使配置生效
访问Mycat向 orders_detail表插入数据
-
插入数据
INSERT INTO orders_detail(id,detail,order_id) values(1,'detail1',1); INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2); INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3); INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4); INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5); INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
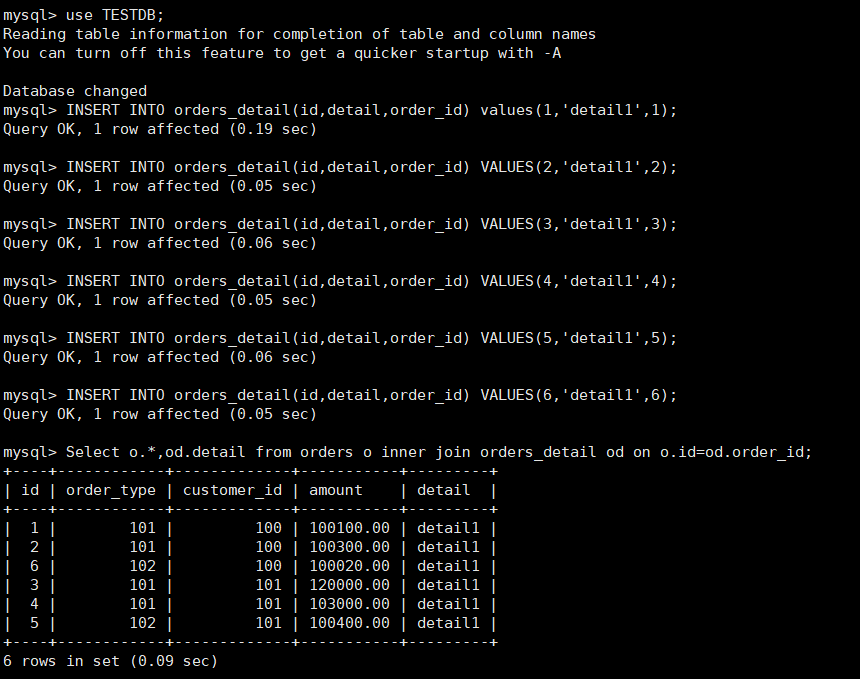
在mycat、dn1、dn2中运行两个表join语句
-
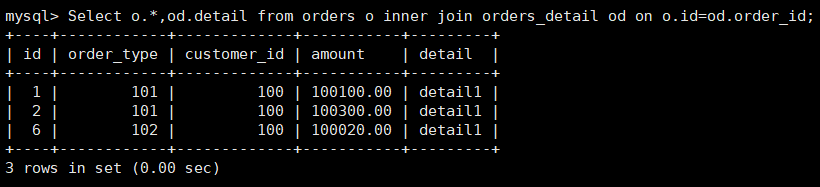
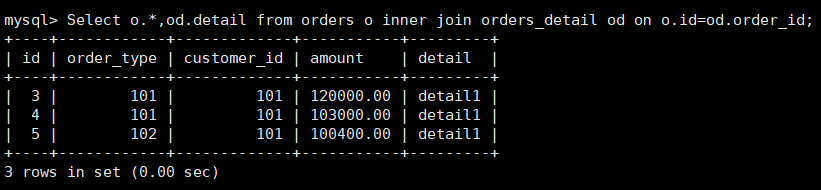
Select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id; -
Mycat中运行关联语句
-
在dn1 3327 中运行join语句
-
在dn2 3328 中运行join语句
全局表
-
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
- 1:变动不频繁
- 2:数据量总体变化不大
- 3:数据规模不大,很少有超过数十万条记录
鉴于此,Mycat定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
① 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
② 全局表的查询操作,只从一个节点获取
③ 全局表可以跟任何一个表进行JOIN操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN的难题,通过全局表+E-R关系的分片策略,Mycat可以满足80%以上的企业应用开发
修改配置文件 schema.xml
-
添加配置项
<table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>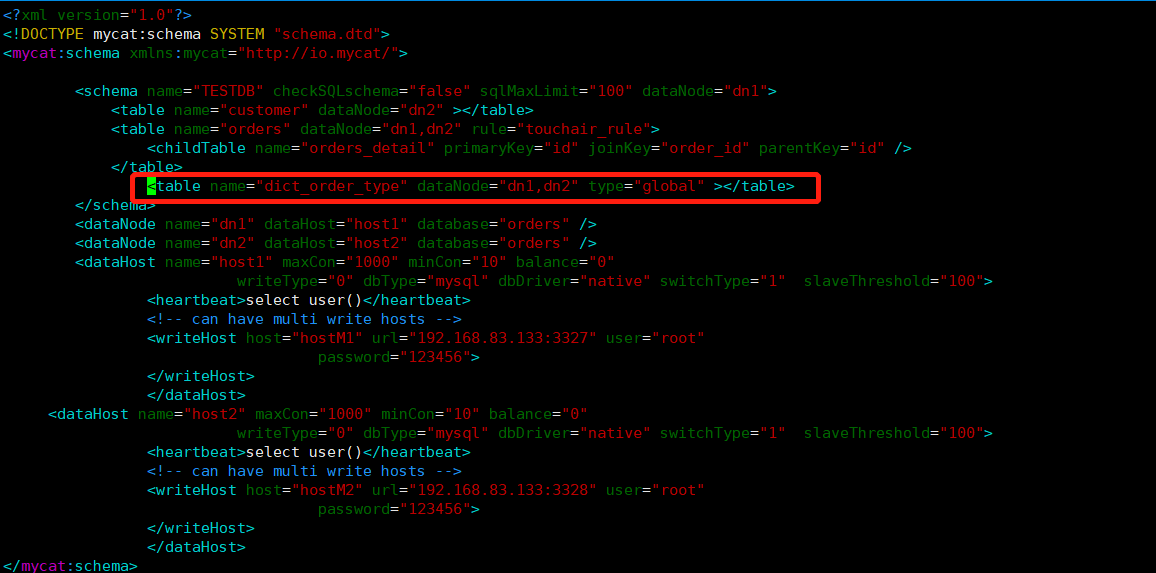
重启Mycat使配置生效
在 dn2 创建 dict_order_type 表
-
建表
CREATE TABLE dict_order_type( id INT AUTO_INCREMENT, order_type VARCHAR(200), PRIMARY KEY(id) );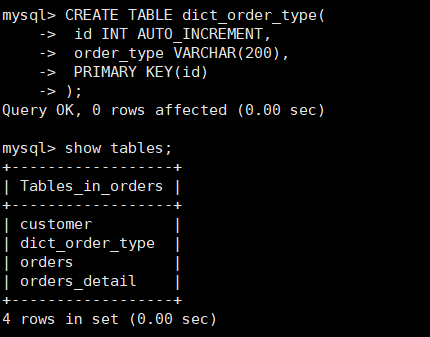
访问Mycat向dict_order_type 表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');
INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');
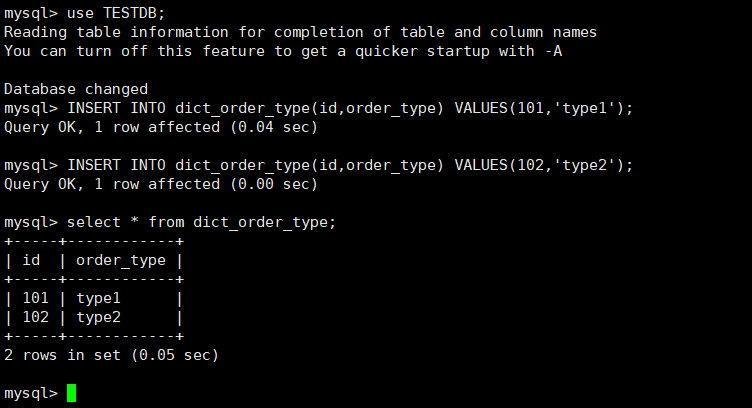
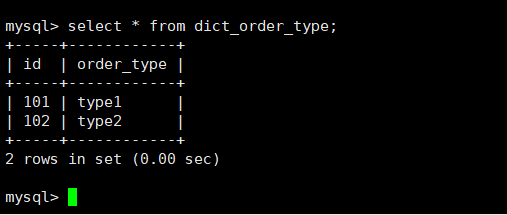
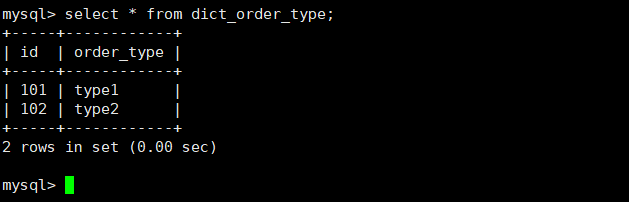
在Mycat、dn1、dn2中查询表数据
-
Mycat
-
dn1 3327
-
dn2 3328
常用的分片规则
取模
- 此规则为对分片字段求模运算。也是水平分表最常用规则。5.1配置分表中,orders表采用了此规则
分片枚举
- 通过在配置文件中配置可能的枚举id,自己配置分片,本规则适用与特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务就使用本规则
修改schema.xml文件
<table name="orders_ware_info" dataNode="dn1,dn2" rule="sharding_by_intfile" ></table>

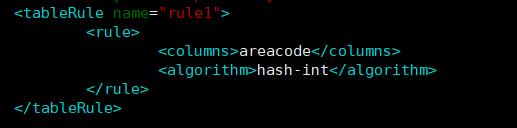
修改rule.xml
<tableRule name="sharding_by_intfile">
<rule>
<columns>areacode</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
</function>
# columns:分片字段,algorithm:分片函数
# mapFile:标识配置文件名称,type:0为int型、非0为String, #defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点, # 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错

修改partition-hash-int.txt配置文件
110=0
120=1
重启Mycat
访问Mycat创建订单归属区域信息表
-
创建表
CREATE TABLE orders_ware_info ( `id` INT AUTO_INCREMENT comment '编号', `order_id` INT comment '订单编号', `address` VARCHAR(200) comment '地址', `areacode` VARCHAR(20) comment '区域编号', PRIMARY KEY(id) );
插入数据
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'bj','110');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,'sz','120');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (3,3,'dy','120');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (4,4,'cz','110');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (5,5,'wx','110');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (6,6,'sh','120');
查询Mycat、dn1、dn2 可以看到数据分片效果
-
Mycat
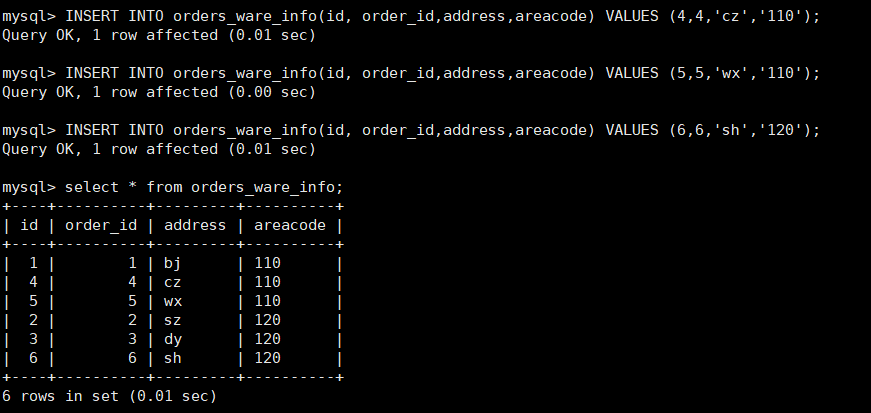
-
dn1 3327
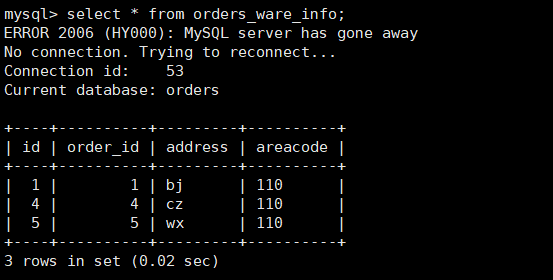
-
dn2 3328
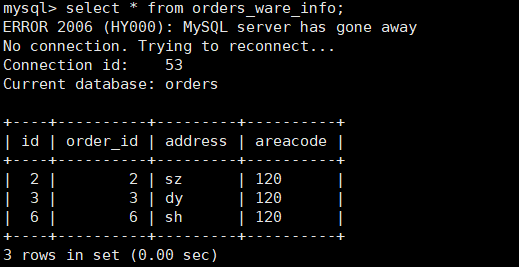
范围约定
- 此分片适用于,提前规划好分片字段某个范围属于哪个分片
修改schema.xml文件
-
添加配置项
<table name="payment_info" dataNode="dn1,dn2" rule="auto_sharding_long" ></table>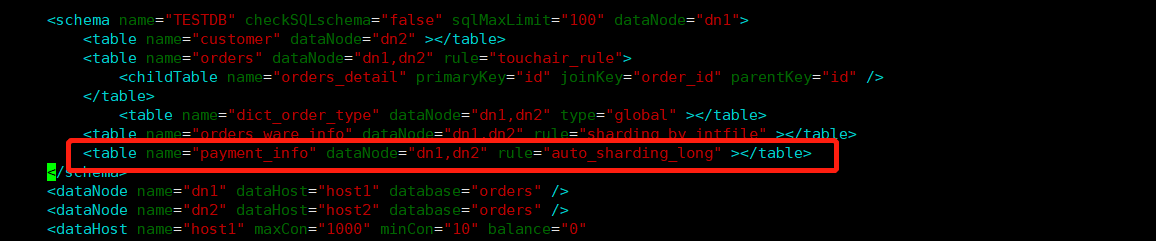
修改rule.xml文件
-
添加规则
<tableRule name="auto_sharding_long"> <rule> <columns>order_id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule>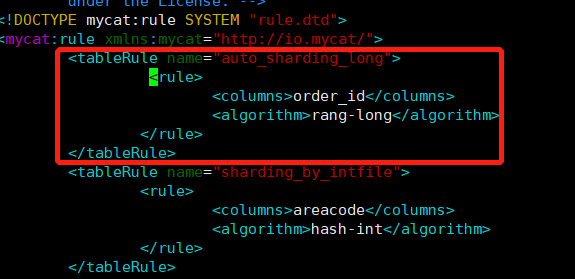
-
算法配置
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> <property name="defaultNode">0</property> </function>columns:分片字段,algorithm:分片函数
mapFile:标识配置文件名称
defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点, 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错
-
修改
autopartition-long.txt文件0-102=0 103-200=1
重启Mycat
访问Mycat并创建表
-
建表SQL
#支付信息表 CREATE TABLE payment_info ( `id` INT AUTO_INCREMENT comment '编号', `order_id` INT comment '订单编号', `payment_status` INT comment '支付状态', PRIMARY KEY(id) ); -
插入数据
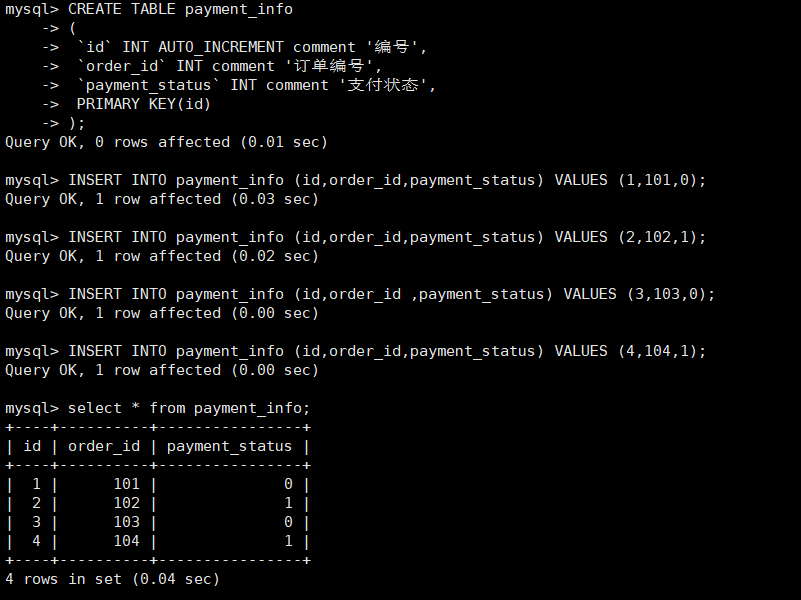
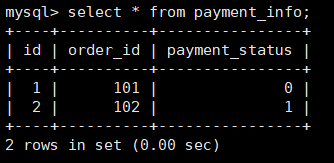
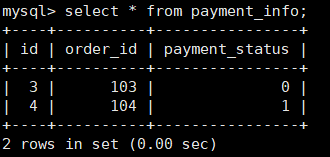
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0); INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1); INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0); INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);
查询Mycat、dn1、dn2可以看到数据分片效果
-
Mycat
-
dn1
-
dn2
按日期(天)分片
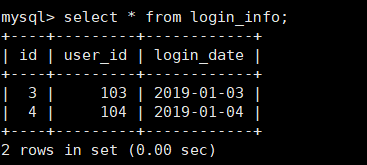
- 此规则为按天分片,设定时间格式、范围
修改schema.xml文件
-
添加配置文件
<table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table>
修改rule.xml
-
修改规则
<tableRule name="sharding_by_date"> <rule> <columns>login_date</columns> <algorithm>shardingByDate</algorithm> </rule> </tableRule>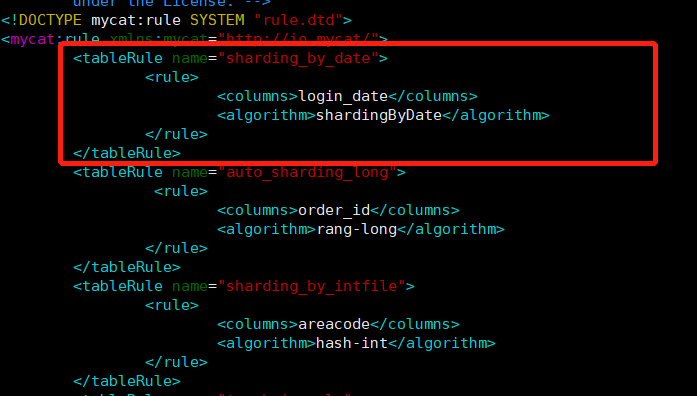
-
算法配置
<function name="shardingByDate" class="io.mycat.route.function.PartitionByDate"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2019-01-01</property> <property name="sEndDate">2019-01-04</property> <property name="sPartionDay">2</property> </function> # columns:分片字段,algorithm:分片函数 #dateFormat :日期格式 #sBeginDate :开始日期 #sEndDate:结束日期,则代表数据达到了这个日期的分片后循环从开始分片插入 #sPartionDay :分区天数,即默认从开始日期算起,分隔 2 天一个分区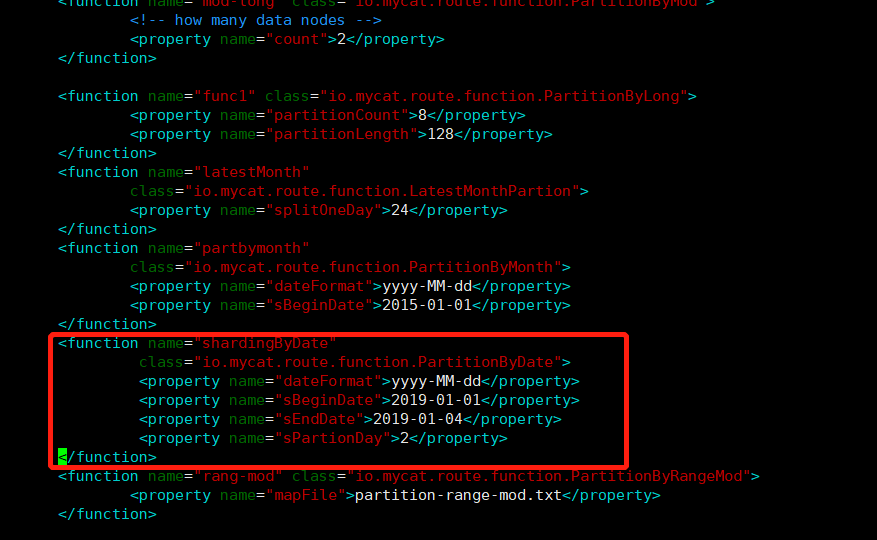
重启Mycat
访问Mycat创建表
-
建表SQL
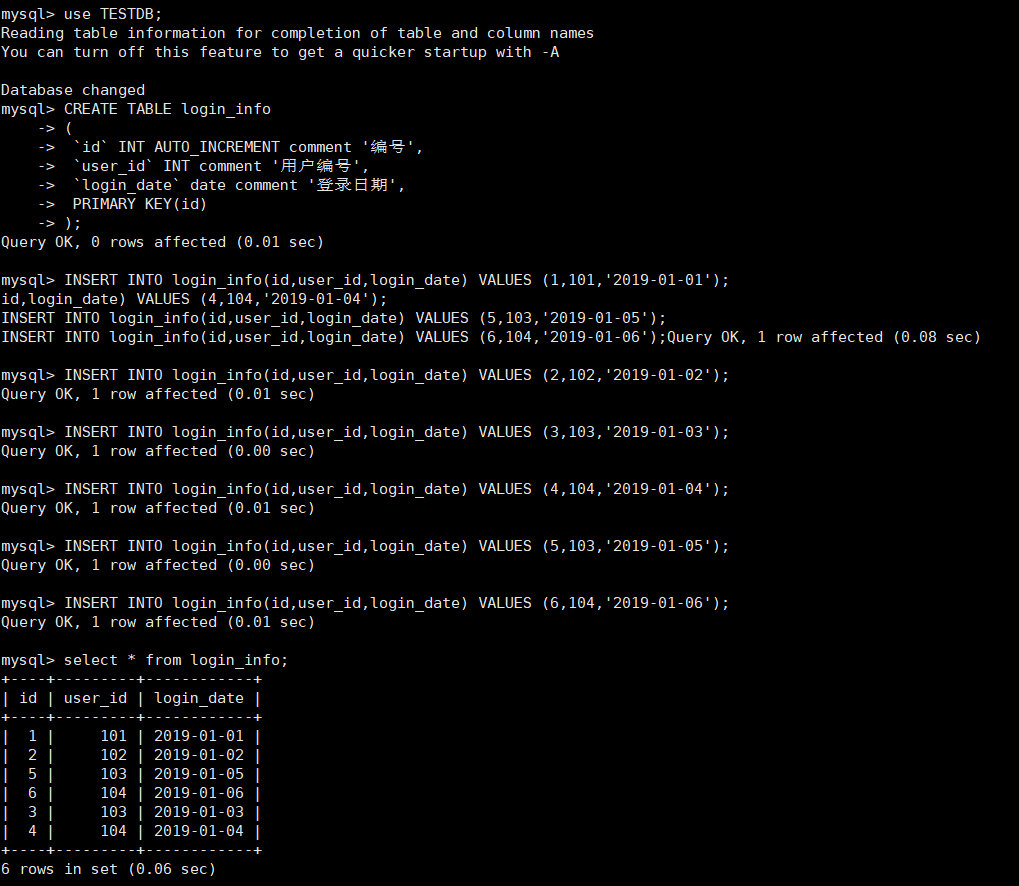
#用户信息表 CREATE TABLE login_info ( `id` INT AUTO_INCREMENT comment '编号', `user_id` INT comment '用户编号', `login_date` date comment '登录日期', PRIMARY KEY(id) );
插入数据
-
插入SQL
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2019-01-01'); INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2019-01-02'); INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2019-01-03'); INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2019-01-04'); INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2019-01-05'); INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2019-01-06');
查询Mycat、dn1、dn2可以看到数据分片效果
-
Mycat
-
dn1
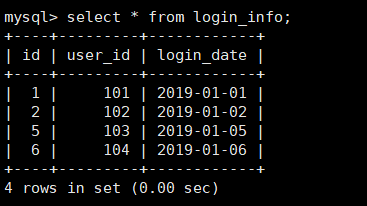
-
dn2
全局序列
- 以上例子中,id都是写死插入的,但真实场景不适用,那么怎么防止id重复、冲突呢?
- 在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat提供了全局sequence,并且提供了包含本地配置和数据库配置等多种实现方式
本地文件方式
- 此方式Mycat将sequence配置到文件中,当使用到sequence中的配置后,Mycat会更新classpath中的sequence_conf.properties文件sequence当前的值
- 优点:本地加载,读取速度较快
- 缺点:抗风险能力差,Mycat所在主机宕机后,无法读取本地文件
数据库方式(推荐)
-
利用数据库一个表来进行计数累加,但并不是每次生成序列都读写数据库,这样效率太低。Mycat会预加载一部分号段到Mycat内存中,这样大部分读写序列都是在内存中完成的。如果内存中的号段用完了Mycat会在向数据库要一次
-
问:那如果 Mycat 崩溃了 ,那内存中的序列岂不是都没了?
是的。如果是这样,那么 Mycat 启动后会向数据库申请新的号段,原有号段会弃用
也就是说如果 Mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复
第一步:建库序列脚本
-
在dn1上创建全局序列表
CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOT NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB; -
创建全局序列所需要函数
#开发人员无需考虑 以下语句怎么写 #遵循官方文档 DELIMITER $$ CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64) DETERMINISTIC BEGIN DECLARE retval VARCHAR(64); SET retval="-999999999,null"; SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM MYCAT_SEQUENCE WHERE NAME = seq_name; RETURN retval; END $$ DELIMITER ; DELIMITER $$ CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS VARCHAR(64) DETERMINISTIC BEGIN UPDATE MYCAT_SEQUENCE SET current_value = VALUE WHERE NAME = seq_name; RETURN mycat_seq_currval(seq_name); END $$ DELIMITER ; DELIMITER $$ CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64) DETERMINISTIC BEGIN UPDATE MYCAT_SEQUENCE SET current_value = current_value + increment WHERE NAME = seq_name; RETURN mycat_seq_currval(seq_name); END $$ DELIMITER ; -
初始化序列表记录
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000, 100); #查看 select * from MYCAT_SEQUENCE;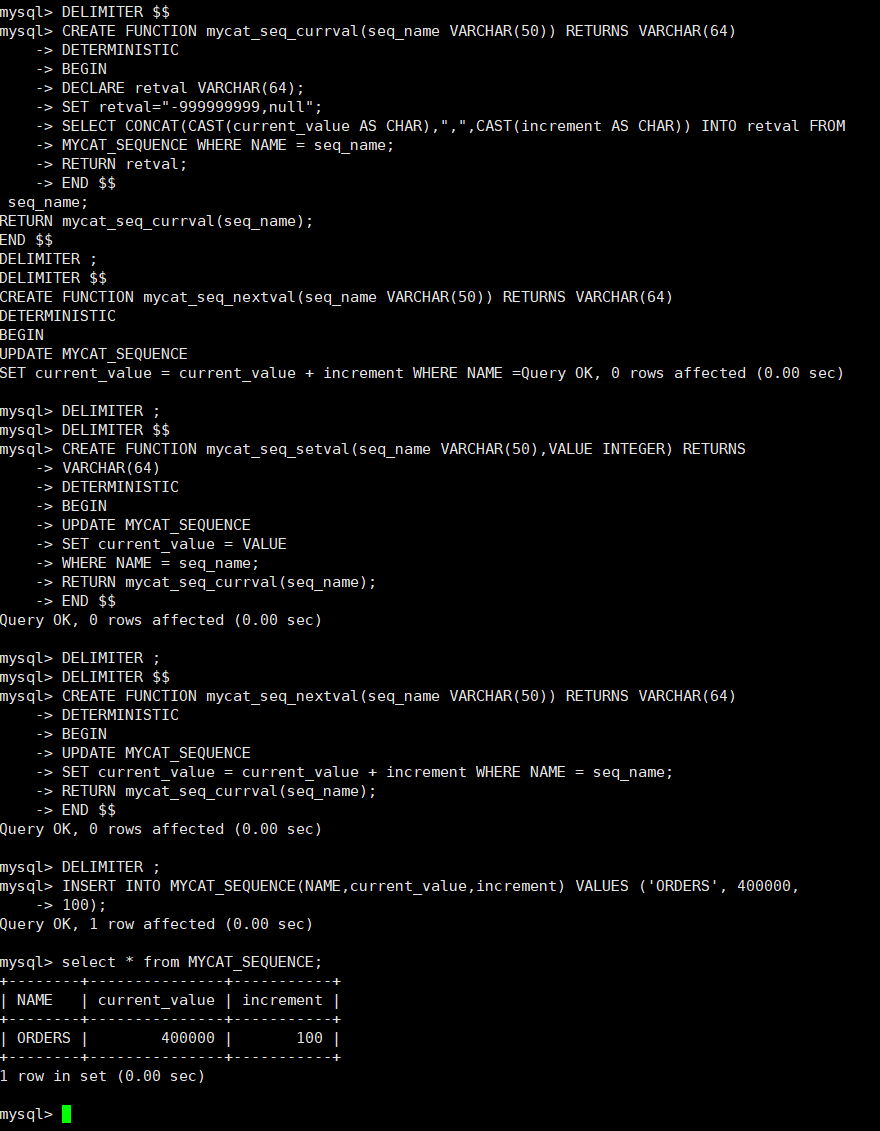
第二步:修改 Mycat 配置
-
修改sequence_db_conf.properties
vim sequence_db_conf.properties #意思是 ORDERS这个序列在dn1这个节点上,具体dn1节点是哪台机子,请参考schema.xml #修改server.xml vim server.xml #全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1。
重启Mycat
验证全局序列
-
登录 Mycat,插入数据
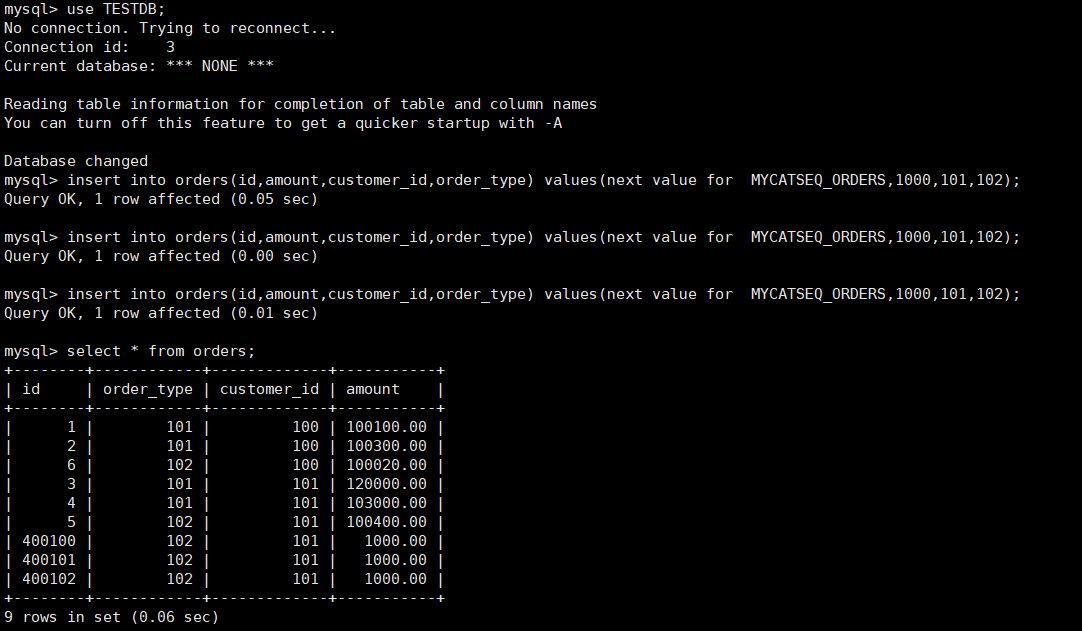
insert into orders(id,amount,customer_id,order_type) values(next value for MYCATSEQ_ORDERS,1000,101,102);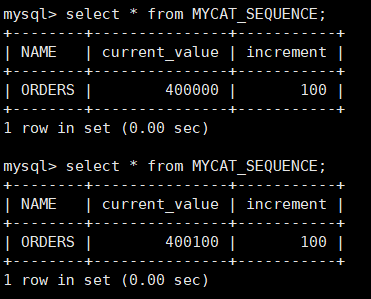
时间戳方式
- 全局序列 ID=64位二进制(42毫秒)+5(机器ID)+5 (业务编码)+12(重复累加)换算成十进制为18位数的long类型,每毫秒可以并发12位二进制的累加
- 优点:配置简单
- 缺点:18位ID过长
自主生成全局序列
- 可在java项目中自主生成全局序列
- 根据业务逻辑组合
- 可以利用redis的单线程原子性incr来生产序列,但自主生成需要单独在工程中用 java 代码实现,还是推荐使用 Mycat 自带全局序列
基于HA机制的Mycat高可用
- 在实际项目中,Mycat服务也需要考虑高可用性,如果Mycat所在的服务器出现宕机,或Mycat服务故障,需要有备机提供服务,需要考虑Mycat集群
高可用方案
-
我们可以使用HAProxy+KeepAlived配合两台Mycat搭起Mycat集群,实现高可用性。HAProxy实现了Mycat多节点的集群高可用和负载均衡,而HAProxy自身的高可用则可以通过Keepalived来实现
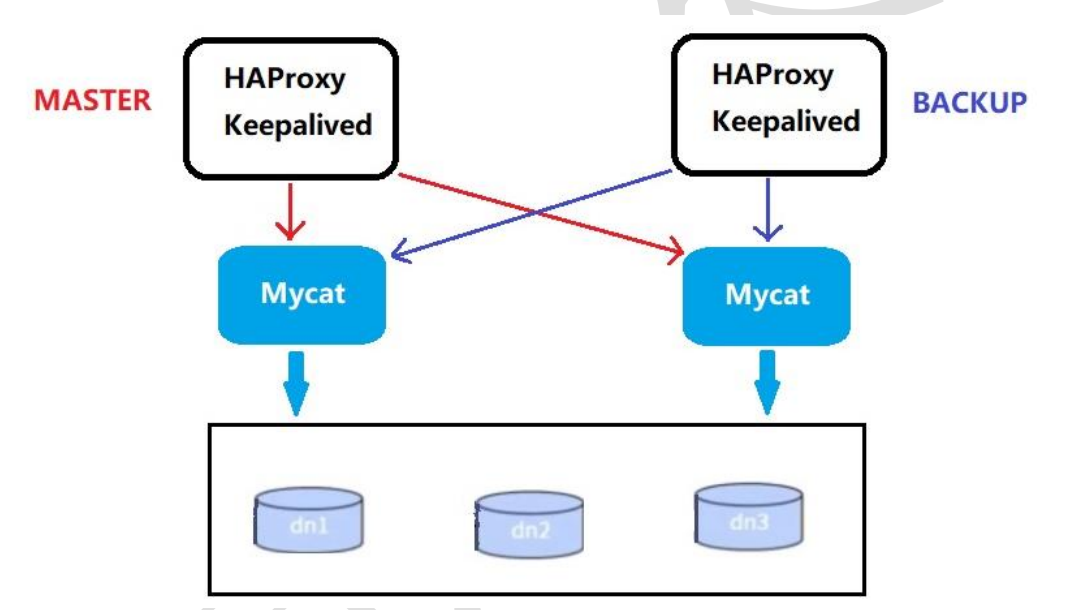
| 编号 | 角色 | IP地址 |
|---|---|---|
| 1 | Mycat1 | 192.168.83.133 |
| 2 | Mycat2 | 192.168.0.105 |
| 3 | HAProxy(master) | 192.168.83.133 (48066) |
| 4 | HAProxy(backup) | 192.168.83.133 (48600) |
| 5 | Keepalived(master) | 虚拟ip 192.168.83.200 |
| 6 | Keepalived(backup) | |
| 7 | 若干mysql服务器 |
安装配置HAProxy
安装
-
解压编译安装
#解压到/usr/local/haproxy tar -zxvf haproxy-2.0.19.tar.gz #进入解压后的目录,查看内核版本,进行编译 cd /usr/local/haproxy/haproxy-2.0.19 uname -r make TARGET=linux310 PREFIX=/usr/local/haproxy/haproxy-2.0.19 ARCH=x86_64 # ARGET=linux310,内核版本,使用uname -r查看内核,如:3.10.0-514.el7,此时该参数就为linux310; #ARCH=x86_64,系统位数; #PREFIX=/usr/local/haprpxy #/usr/local/haprpxy,为haprpxy安装路径。 #编译完成后,进行安装 make install PREFIX=/usr/local/haproxy/haproxy-2.0.19 #安装完成后,创建目录、创建HAProxy配置文件 mkdir -p /usr/data/haproxy/ vim /usr/local/haproxy/haproxy.conf #6向配置文件中插入以下配置信息,并保存 global log 127.0.0.1 local0 #log 127.0.0.1 local1 notice #log loghost local0 info maxconn 4096 chroot /usr/local/haproxy pidfile /usr/data/haproxy/haproxy.pid uid 99 gid 99 daemon #debug #quiet defaults log global mode tcp option abortonclose option redispatch retries 3 maxconn 2000 timeout connect 5000 timeout client 50000 timeout server 50000 listen proxy_status bind :48066 mode tcp balance roundrobin server mycat_1 192.168.83.133:8066 check inter 10s server mycat_2 192.168.0.105:8066 check inter 10s frontend admin_stats bind :7777 mode http stats enable option httplog maxconn 10 stats refresh 30s stats uri /admin stats auth admin:123123 stats hide-version stats admin if TRUE
启动验证
-
验证
#1启动HAProxy /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf #2查看HAProxy进程 ps -ef|grep haproxy #3打开浏览器访问 http://192.168.140.125:7777/admin #在弹出框输入用户名:admin密码:123123
如果Mycat主备机均已启动,则可以看到如下图
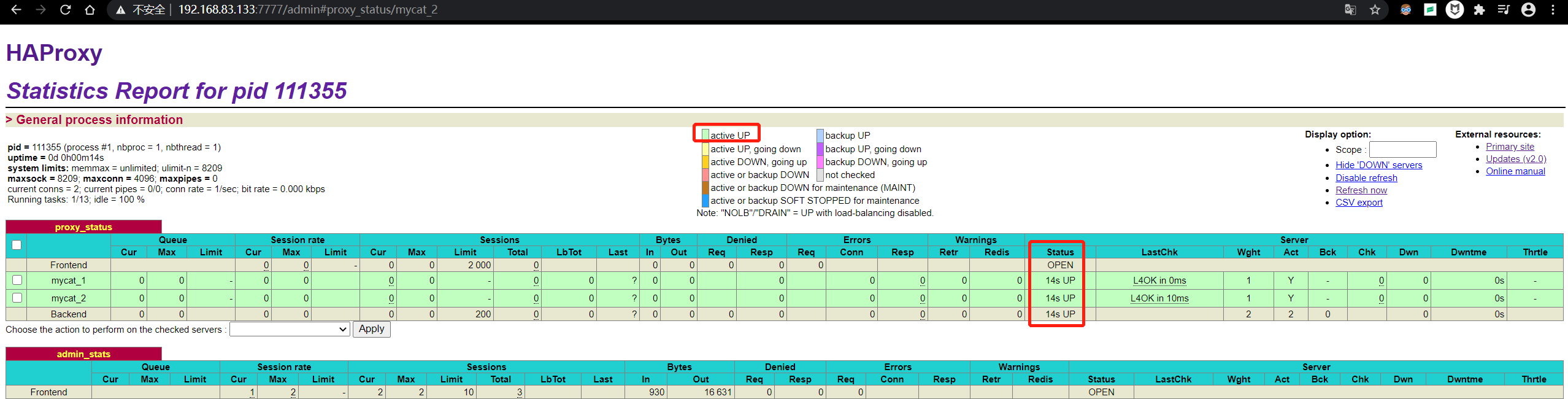
#4验证负载均衡,通过HAProxy访问Mycat 48066为HAproxy配置的端口 mysql -umycat -h 192.168.83.133 -P 48066 -p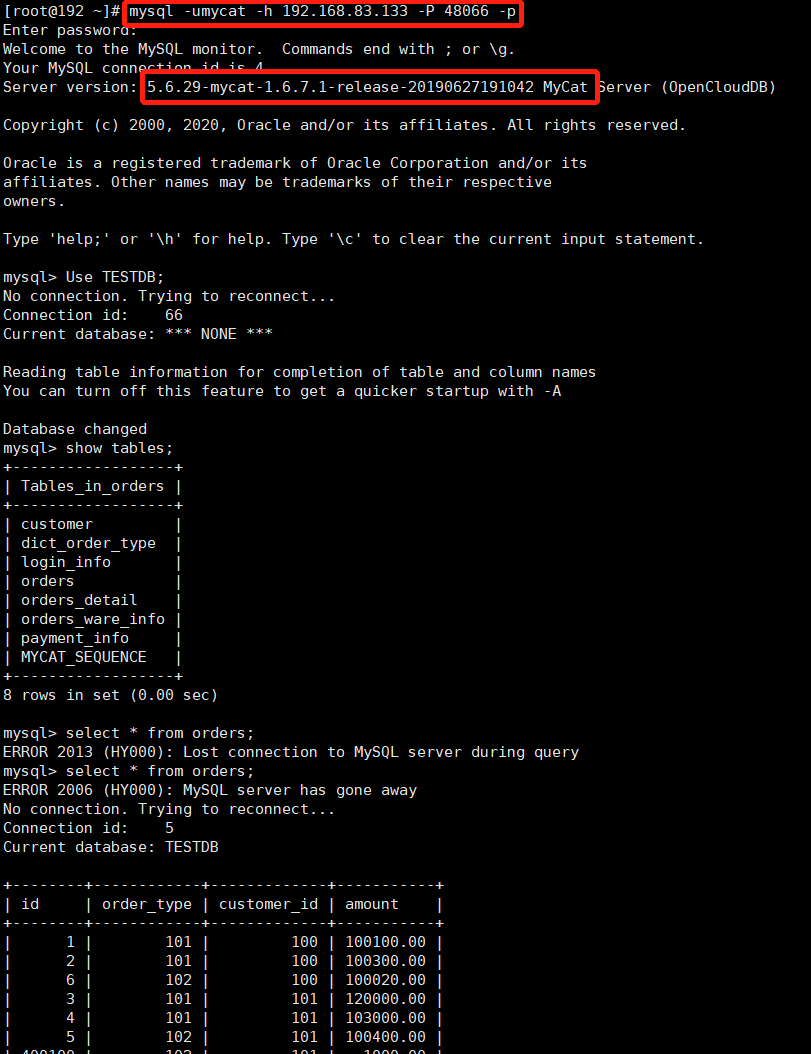
配置Keepalived
安装Keepalived
-
解压安装配置
#1.解压 tar -zxvf keepalived-1.4.4.tar.gz #2.安装依赖插件 yum install -y gcc openssl-devel popt-devel #3.进入解压后的目录,进行配置,进行编译 /usr/local/keepalived/keepalived-1.4.4 ./configure --prefix=/usr/local/kp #4进行编译,完成后进行安装 make && make install #5运行前配置 cp /usr/local/keepalived/keepalived-1.4.4/keepalived/etc/init.d/keepalived /etc/init.d/ mkdir /etc/keepalived cp /usr/local/kp/etc/keepalived/keepalived.conf /etc/keepalived/ cp /usr/local/keepalived/keepalived-1.4.4/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ cp /usr/local/kp/sbin/keepalived /usr/sbin/ #6修改配置文件 (清空覆盖 注意修改自己的ip地址) vim /etc/keepalived/keepalived.conf-
conf
global_defs { notification_email { xlcocoon@foxmail.com } notification_email_from keepalived@showjoy.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_instance VI_1 { #主机配MASTER,备机配BACKUP state MASTER #所在机器网卡 interface ens33 virtual_router_id 51 #数值越大优先级越高 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { #虚拟IP 192.168.83.200 } } virtual_server 192.168.83.200 48066 { delay_loop 6 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP real_server 192.168.83.133 48066 { weight 1 TCP_CHECK { connect_timeout 3 retry 3 delay_before_retry 3 } } real_server 192.168.83.133 48600 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } }
-
启动验证
-
#1启动Keepalived service keepalived start #2登录验证 mysql -umycat -p123456 -h 192.168.83.200 -P 48066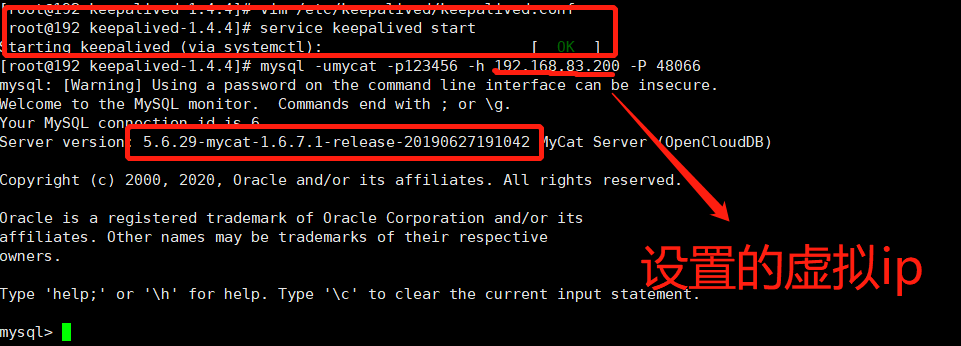
测试高可用
-
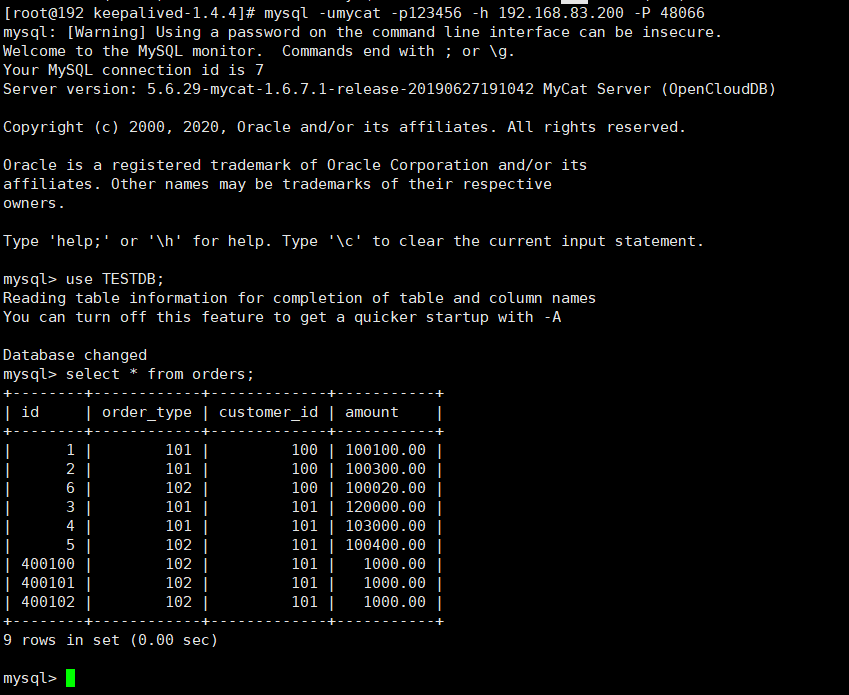
第一步:关闭一个Mycat
-
第二步:通过虚拟ip查询数据
mysql -umycat -p123456 -h 192.168.83.200 -P 48066
## Mycat安全设置
### 权限配置
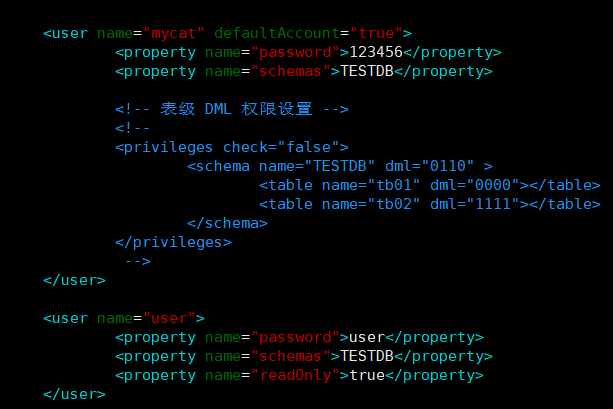
#### user标签权限控制
* 目前Mycat对于中间件的连续控制并没有做太复杂的控制,只做了中间件逻辑库级别的读写权限控制。是通过`server.xml` 的user标签进行配置
* 配置说明
| 标签属性 | 说明 |
| -------- | ------------------------------------------------------------ |
| name | 应用连接中间件逻辑库的用户名 |
| password | 该用户对应的密码 |
| schemas | 应用当前连接的逻辑库。schemas中可以配置一个或多个 |
| readOnly | 应用连接中间件逻辑库所具有的权限。true为只读,false为读写都有,默认为false |
* 测试案例
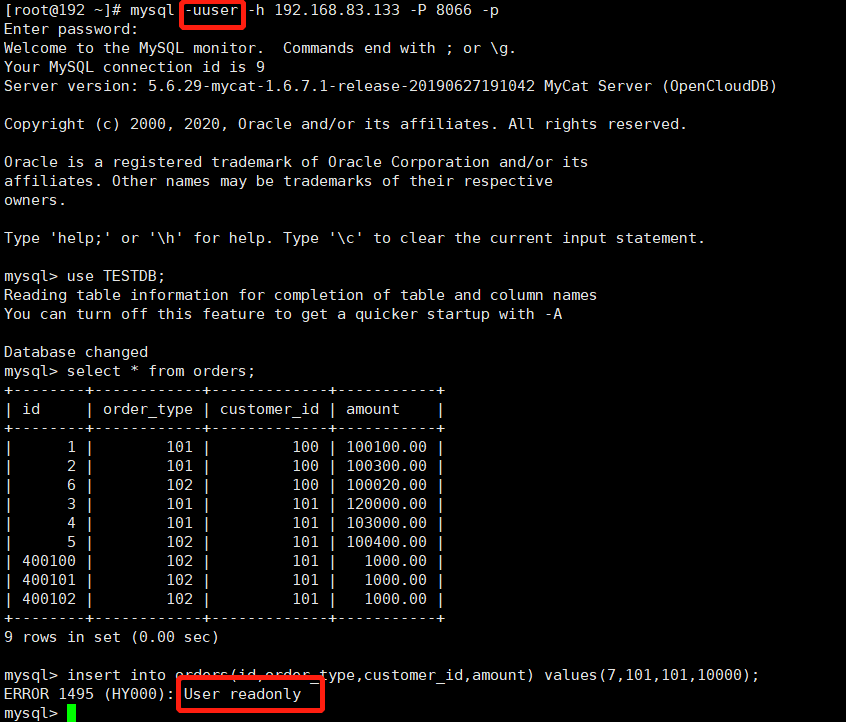
* 测试一
使用user用户,权限为只读(readOnly:true)
验证是否可以查询出数据,验证是否可以写入数据
结论:只读,不可写
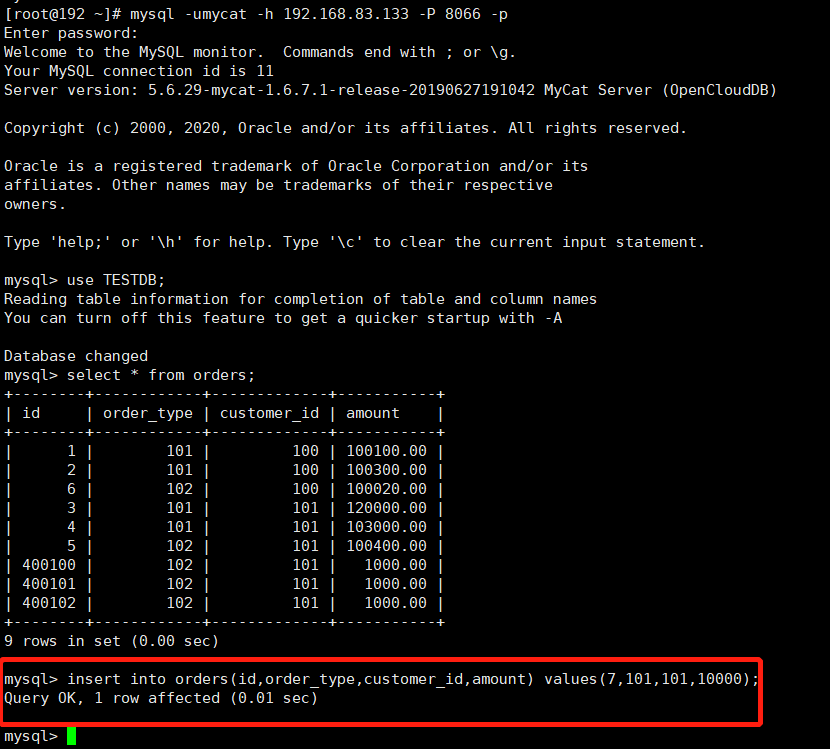
* 测试二
```
#使用mycat用户,权限为可读写(readOnly:false)
# 验证是否可以查询出数据,验证是否可以写入数据
结论:可读可写
```
#### privileges标签权限控制
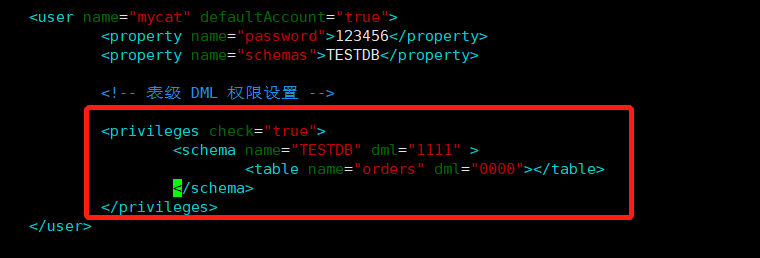
* 在user标签下的`privileges`标签可以对逻辑库(schema)、表(table)进行精细化的DML权限控制
`privileges`标签下的`check`属性,如为`true`开启权限检查,为`false`不开启,默认为`false`
由于Mycat 一个用户的`schemas`属性可配置多个逻辑库(schema),所以 `privileges`的下级节点schema节点同样可配置多个,对多库多表进行细粒度的DML权限控制
```xml
#server.xml配置文件privileges部分
#配置orders表没有增删改查权限
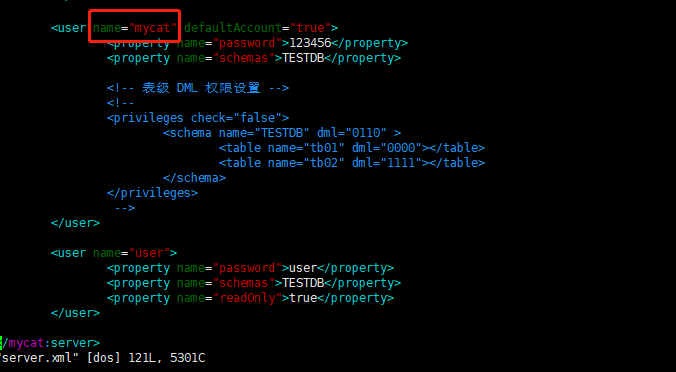
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<privileges check="true">
<schema name="TESTDB" dml="1111" >
<table name="orders" dml="0000"></table>
<!--<table name="tb02" dml="1111"></table>-->
</schema>
</privileges>
</user>
-
配置说明
DML权限 增加(insert) 更新(update) 查询(select) 删除(delete) 0000 禁止 禁止 禁止 禁止 0010 禁止 禁止 允许 禁止 1110 允许 禁止 禁止 禁止 1111 允许 允许 允许 允许 -
测试案例(重启Mycat)
-
测试一
使用mycat用户,privileges配置orders表权限为禁止增删改查(dml="0000") 验证是否可以查询出数据,验证是否可以写入数据 结论:orders表禁止读写,其他表可读可写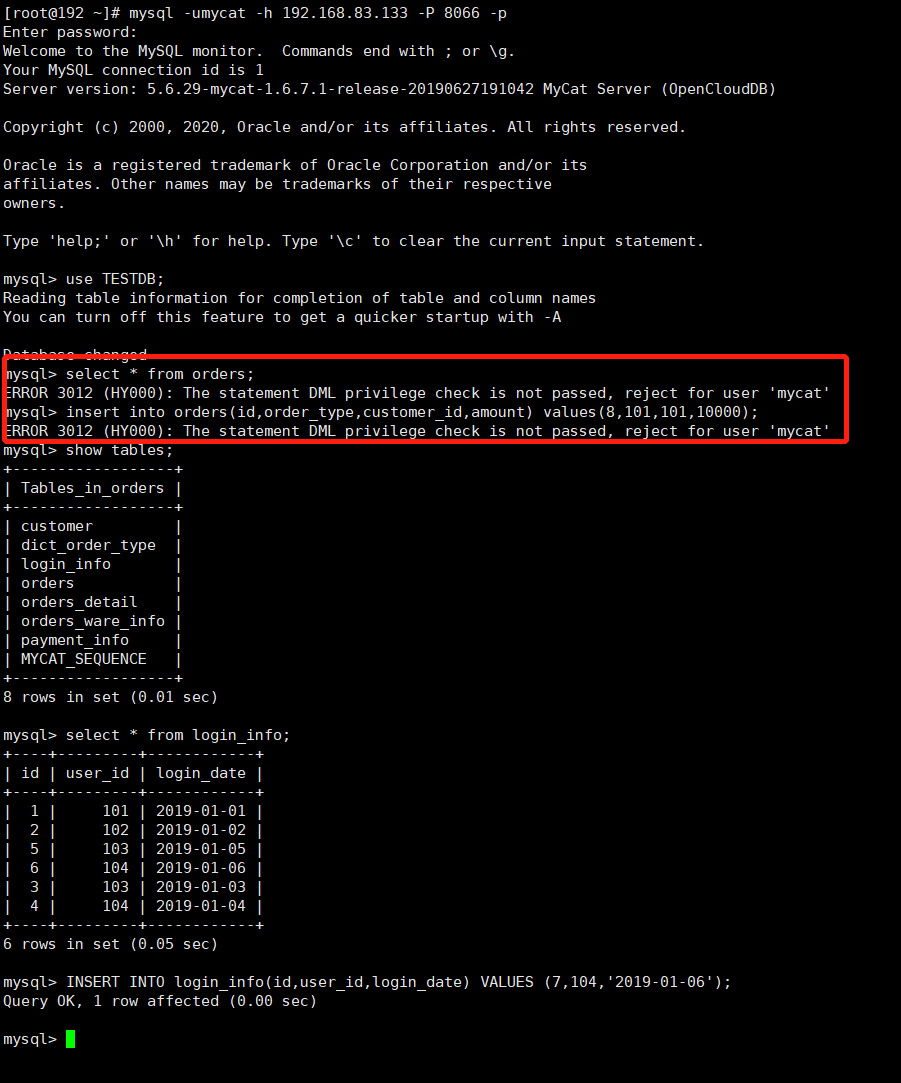
-
SQL拦截
firewall标签用来定义防火墙;firewall下whitehost标签用来定义IP白名单,balckList用来定义SQL黑名单
白名单
-
可以通过设置白名单,实现某些主机某些用户可以访问Mycat,而其他主机用户禁止访问
#设置白名单 #server.xml配置文件firewall标签 #配置只有192.168.83.133 主机可以通过mycat用户访问 <firewall> <whitehost> <host host="192.168.83.133" user="mycat"/> </whitehost> </firewall> -
测试 (重启Mycat)
-
192.168.0.105 访问Mycat (拒绝,没有权限)

-
192.168.83.133 访问Mycat (成功)
-
黑名单
-
可以通过设置黑名单,实现 Mycat 对具体 SQL 操作的拦截,如增删改查等操作的拦截
#设置黑名单 #server.xml配置文件firewall标签 #配置禁止mycat用户进行删除操作 <firewall> <whitehost> <host host="192.168.140.128" user="mycat"/> </whitehost> <blacklist check="true"> <property name="deleteAllow">false</property> </blacklist> </firewall>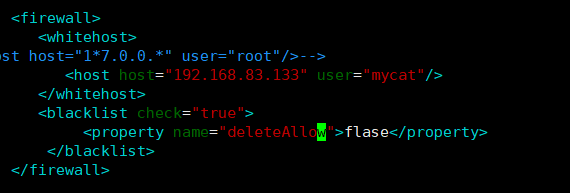
-
配置说明
配置项 缺省值 描述 selectAllow true 是否允许执行SELECT语句 deleteAllow true 是否允许执行DELETE语句 updateAllow true 是否允许执行update语句 insertAllow true 是否允许执行 INSERT 语句 createTableAllow true 是否允许创建表 setAllow true 是否允许使用 SET 语法 alterTableAllow true 是否允许执行 Alter Table 语句 dropTableAllow true 是否允许修改表 commitAllow true 是否允许执行 commit 操作 rollbackAllow true 是否允许执行 roll back 操作 -
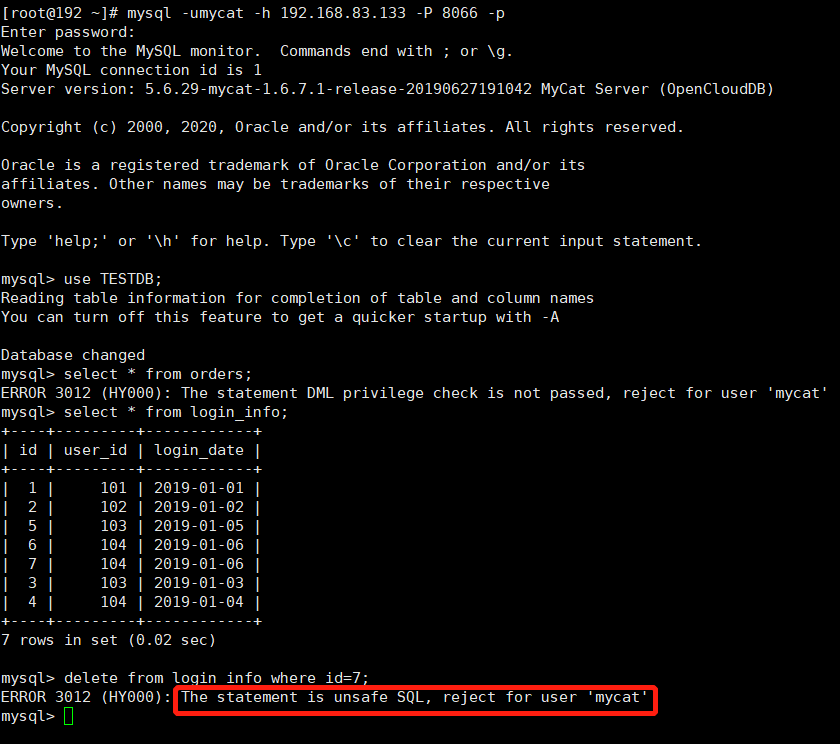
测试(重启Mycat)
Mycat监控工具
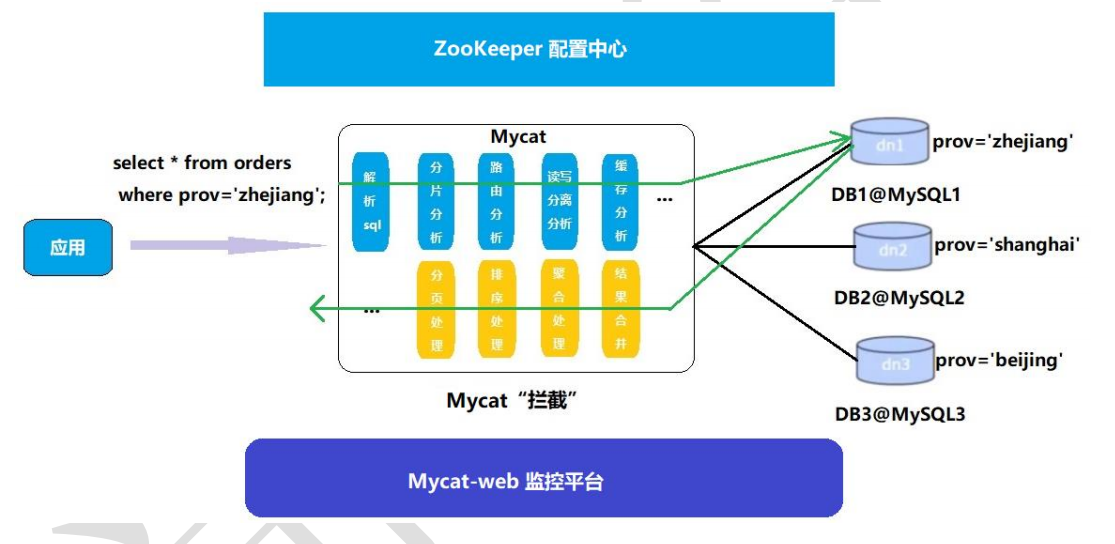
Mycat-web简介
-
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白,帮 Mycat 分
担统计任务和配置管理任务
Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节点
Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮件告警等模
块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等;为优化 SQL 提供依据
Mycat-web配置使用
zookeeper安装
-
解压安装
#1 解压 tar -zxvf apache-zookeeper-3.6.1-bin.tar.gz #2 进入ZooKeeper解压后的配置目录(conf),复制配置文件并改名 cp zoo_sample.cfg zoo.cfg #3 进入ZooKeeper的命令目录(bin),运行启动命令 ./zkServer.sh start #4 ZooKeeper服务端口为2181,查看服务已经启动 netstat -ant | grep 2181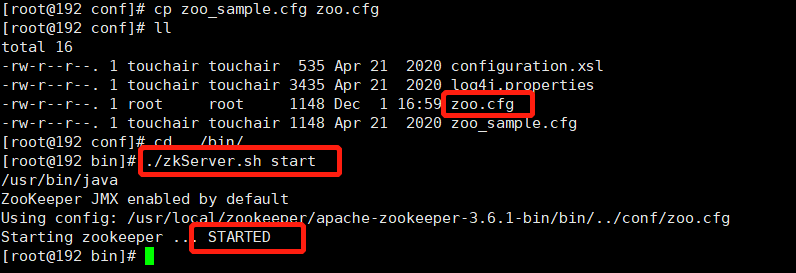

Mycat-web安装
-
# 解压 tar -zxvf Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz #启动 ./start.sh & # Mycat-web服务端口为8082,查看服务已经启动 netstat -ant | grep 8082 # 通过地址访问服务 http://192.168.83.133:8082/mycat/

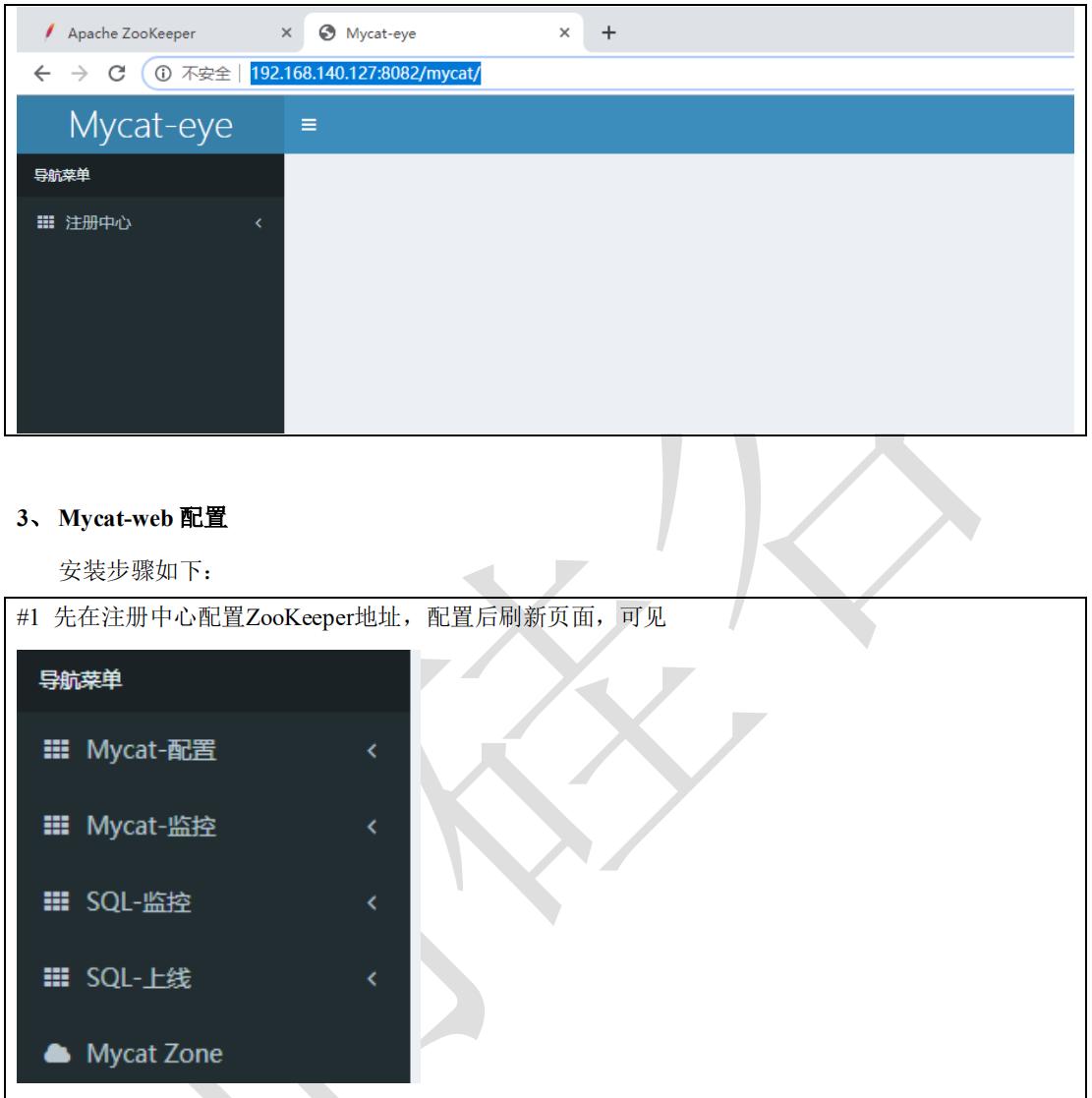
Mycat-web配置
-
新增Mycat监控实例
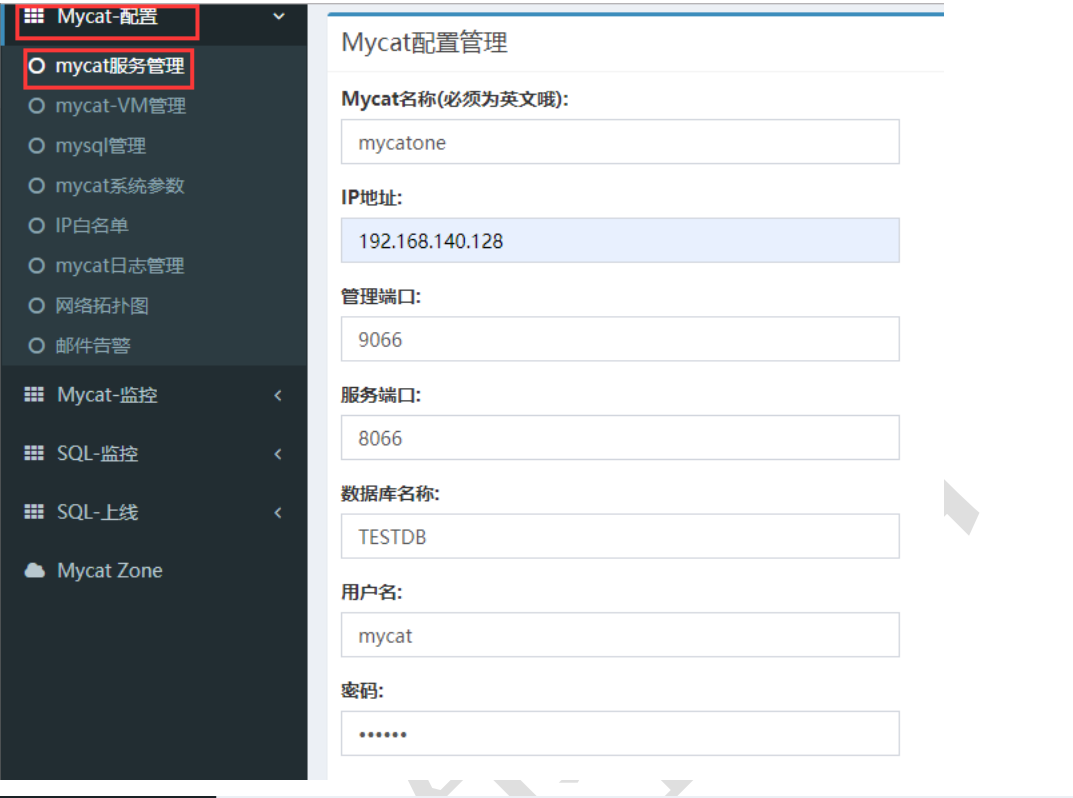
Mycat性能监控指标
-
监控分析