实验平台:
Virtual Box 4.3.24
CentOS7
JDK 1.8.0_60
Hadoop 2.6.0
Hadoop基本安装配置主要包括以下几个步骤:
1)创建Hadoop用户
2)安装Java
3)设置SSH登陆权限
4)单机安装配置
5)伪分布式安装配置
1.1 创建Hadoop用户
linux创建用户的命令是useradd,设置密码的命令是passwd
在CentOS下,首先我们通过useradd命令创建一个Hadoop用户组,它的密码也是Hadoop:
useradd hadoop #设置hadoop用户组 passwd hadoop #配置hadoop用户组的密码
在/home文件夹下,出现了一个hadoop文件夹
![]()
1.2 安装JDK
到oracle官网下载一个jdk。并复制到/usr/lib/jvm下
cp jdk-8u60-linux-x64.tar.gz /usr/lib/jvm
接着解压缩
tar -zxvf jdk-8u60-linux-x64.tar.gz
z表示解压gzip属性的
x表示解压,c表示压缩
v表示显示过程
f表示接档案名字
用编辑器打开.bashrc文件:
vi ~/.bashrc
在第一行加入
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_60
export JAVA_BIN=$JAVA_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
接着还要使刚才的更改生效:
source ~/.bashrc
使用echo命令查看环境变量:
[root@localhost jvm]# echo $JAVA_HOME /usr/lib/jvm/jdk1.8.0_60
配置成功,可以用java -version命令查看jdk是否安装成功

1.3 配置SSH
CentOS7默认安装了OpenSSH(client),我们只要启动就好了。在shell下键入以下命令:
service sshd start
我们还要安装ssh server,在shell下执行:
yum install openssh-server
安装完后可以使用命令ssh localhost来ssh登陆本机,由于是首次登陆,会出现如下提示

按照提示输入yes,然后输入用户hadoop的密码,就可以登陆本机了。但这样每次都要输入密码,我们需要把ssh配置成不需要密码也能访问。
键入exit推出刚才建立的链接
![]()
生成SSH密钥:
[root@localhost hadoop]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): #直接回车 Enter passphrase (empty for no passphrase): #直接回车 Enter same passphrase again: #直接回车 Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 93:6c:b7:39:e7:06:7f:13:d3:65:5a:47:5e:43:f3:6a root@localhost.localdomain The key's randomart image is: +--[ RSA 2048]----+ | .o | | .=| | o+| | . . .*| | S . E=o| | . o.o .+ .| | +o. o | | +o o | | ... . | +-----------------+
生成密钥成功,密钥被放在/root/.ssh/id_rsa.pub位置。接着将密钥加入授权
cd /root/.ssh cp id_rsa.pub authorized_keys #将刚才生成的密钥加入授权
接着再执行ssh localhost命令,可以发现已经不需要再输入登陆密码了

1.4 安装hadoop
把下载好的hadoop压缩包(注意是binary文件,不要下成source了)解压到/usr/local目录下
tar -zxvf ./hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
将得到的文件夹改名为hadoop
mv ./hadoop-2.6.0/ ./hadoop
进入hadoop文件夹下的bin文件夹,可以通过hadoop version命令查看是否安装成功
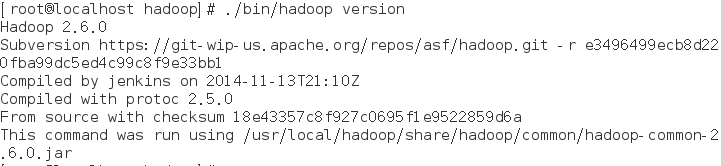
如图所示,hadoop已经安装成功。接着我们可以运行hadoop官方的例子来测试功能是否正常,我们运行WordCount的例子来检验hadoop是否安装成功。首先在hadoop目录下创建input文件夹来存放输入数据;然后将./etc/hadoop/下的配置文件拷贝到input文件夹中;接着在hadoop目录下新建output文件夹,用来存放输出数据。
mkdir input
cp etc/hadoop/*.xml input mkdir output
最后执行如下代码,调用了hadoop的grep功能:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
接着查看输出数据的内容
cat ./output/*
运行上面命令后可以得到以下结果
1 dfsadmin
1.5 hadoop伪分布式配置
伪分布式安装时指在一台机器上模拟一个小的集群。当Hadoop在单节点上以伪分布式的方式运行时,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。不管是真分布式还是伪分布式都需要通过配置文件对各组件的协同工作进行设置,对于伪分布式配置,我们需要修改core-site.xml,hdfs-site.xml和mapred-site-xml(最新hadoop没有这个文件)这三个文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中。

修改core-site.xml,将
<configuration> </configuration>
改为
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<name>标签代表了配置项的名字,<value>项设置的是配置的值。对于core-site.xml文件,我们只需要在其中制定HDFS的地址和端口号,端口号按照官方文档配置为9000即可。然后我们修改hdfs-site.xml文件。修改后如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置完成后,首先需要初始化文件系统,由于hadoop的很多工作是在自带的HDFS文件系统上完成的,因此需要将文件系统初始化以后才能进一步开始计算任务,在bin目录下执行namenode的格式化:
./hdfs namenode -format
15/10/10 19:28:30 INFO util.ExitUtil: Exiting with status 0
15/10/10 19:28:30 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1
************************************************************/
退出状态为0表示初始化成功,如果为1表示格式化失败。
接着开启命名节点和数据节点的守护进程:

启动完成后,输入jps命令就可以查看是否启动成功,如果启动成功,将会看到3个进程:
Jps、NameNode、DataNode和SecondaryNameNode
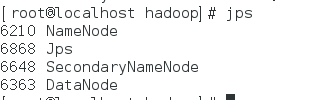
成功启动后,可以访问 Web 界面 http://localhost:50070 来查看 Hadoop 的信息。

上面单机实例中我们用grep读取的是本地数据,而在伪分布式中我们读取的则是HDFS中的数据,为此,我们需要建立一个HDFS文件系统。
bin/hdfs dfs -mkdir -p /user/hadoop/input
由于创建的是hadoop文件系统,在linux的文件系统下不会显示。 接着把etc/hadoop 下的所有文件拷贝到HDFS文件夹input中去
bin/hdfs dfs -put etc/hadoop/*.xml /user/hadoop/input
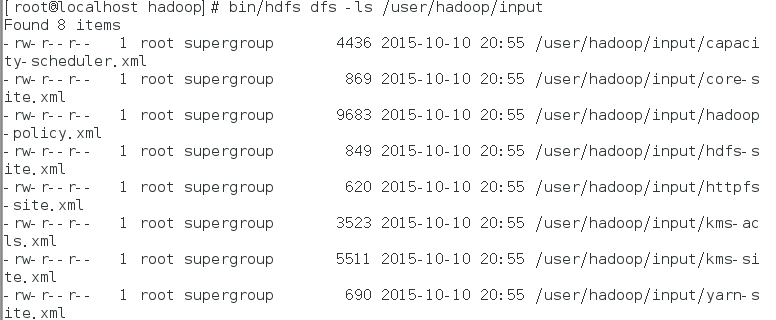
复制完成后,可以通过如下命令查看文件列表:
bin/hdfs dfs -ls /user/hadoop/input
接着执行
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'

接着执行
bin/hdfs dfs -cat /user/hadoop/output/*
得到结果:

Hadoop运行程序时,默认输出目录不能存在,因此再次运行需要执行如下命令删除 output文件夹:
bin/hdfs dfs -rm -r /user/hadoop/output
过程中遇到的错误:
执行start-dfs.sh后,datanode等进程没有启动,原因是root用户启动了这些进程,先要把这些连接释放掉
参考:
http://www.powerxing.com/install-hadoop/
http://www.centoscn.com/CentOS/config/2013/0926/1713.html
《大数据技术原理与应用》 林子雨著