1. 设计需求
flash设备区别与一般的块设备,有如下特点:
- 存在坏块
- 使用寿命较短
- 存储介质不稳定
- 读写速度慢
- 不支持随机访问(nand)
- 只能通过擦除将0改成1
- 最小读写单位为page or sub-page
- 便宜
2. 需求分析
基于可用性、可靠性、可扩展性、性能这4个需求属性展开的分析如下。其中可用性分超级块操作、文件操作和目录操作;可靠性分掉电保护、坏块管理、磨损均衡,错误预测、冗余校验和冗余备份;可扩展性分node和LEB;读写性能分缓存、压缩和异地更新。
其中坏块管理、磨损均衡、错误预测等功能由UBI子系统实现,UBIFS不予关心。后面会就这4个维度展开专题详细介绍。
![]()
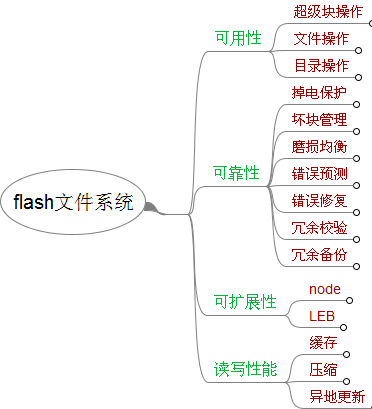
其中坏块管理、磨损均衡、错误预测等功能由UBI子系统实现,UBIFS不予关心。后面会就这4个维度展开专题详细介绍。
3. 对象模型设计
UBIFS有32个文件,41个公共数据对象,其中ubifs_info有近300个字段。而且基于性能和扩展性的考虑,ubifs对象采用了多种数据结构描述:如B+树、RB树、优先队列、链表、数组。总体复杂度高,对象关系复杂。
我们不妨通过分析ubifs的关键路径--写操作,来分析ubifs的设计决策。ubifs层位于通用块层和ubi层之间,通用块层的核心对象是inode和super_block,ubi层的核心对象是LEB。写操作就是要根据inode,进过ubifs层的处理,找到ubi层的LEB,并把数据写入到存储介质上。首先构造ubifs的核心对象ubifs_node,ubifs_node一诞生,就面临如下几个问题:
1) 如何构建ubifs_node组织结构;
2) 如何根据inode创建ubifs_node;
3) 如何通过inode找到ubifs_node;
4) 如何通过ubifs_node找到LEB;
5) 如何给ubifs_node分配LEB;
前3个问题,ubifs通过构造TNC B+树来解决,后2个问题通过LPT B+树来解决。这也是ubifs的另外2个核心对象。B+树的优点是查找快速,但是B+树的更新往往会导致从根节点到目标叶节点路径上所有节点的更新。如何管理TNC和LPT树又有几个问题需要解决:
1) 构造问题:树根节点如何找到;树中间节点和叶节点如何存储到介质上;
2) 读问题:树节点如何根据各种目的进行快速索引;
3) 写问题:树节点如何安全快速地进行添加、更新、删除等操作;
由于TNC和LPT树的规模、目的差异都很大,以上的几个问题的解决方法也不尽相同,后面再分专题进行介绍。其核心对象模型和对象关系设计如下。其中细线条代表关联关系,粗线条代表组合关系,黑色代表内存对象,红色代表flash对象,即需要写入flash的数据。
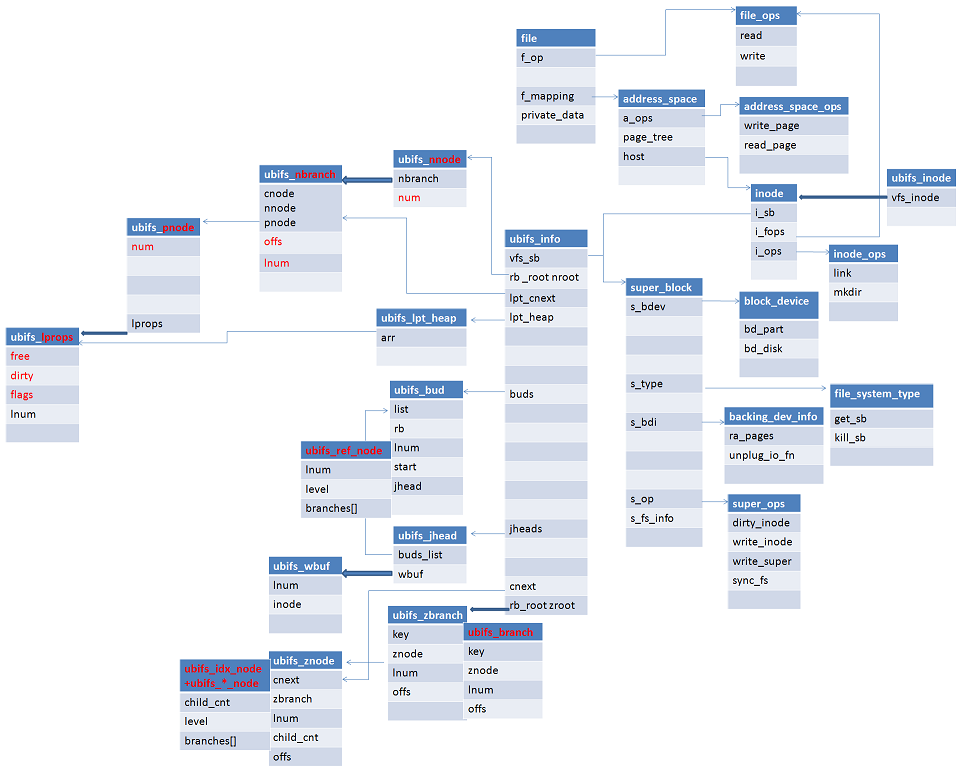
b) 页缓存层核心对象address_space;
c) 通用块层核心数据对象super_block,inode;
d) ubifs层核心数据对象ubifs_info。
其中ubifs_info主要维护三个对象:LPT、TNC和journal,其主要字段解释如下:
![]()

我们不妨通过分析ubifs的关键路径--写操作,来分析ubifs的设计决策。ubifs层位于通用块层和ubi层之间,通用块层的核心对象是inode和super_block,ubi层的核心对象是LEB。写操作就是要根据inode,进过ubifs层的处理,找到ubi层的LEB,并把数据写入到存储介质上。首先构造ubifs的核心对象ubifs_node,ubifs_node一诞生,就面临如下几个问题:
1) 如何构建ubifs_node组织结构;
2) 如何根据inode创建ubifs_node;
3) 如何通过inode找到ubifs_node;
4) 如何通过ubifs_node找到LEB;
5) 如何给ubifs_node分配LEB;
前3个问题,ubifs通过构造TNC B+树来解决,后2个问题通过LPT B+树来解决。这也是ubifs的另外2个核心对象。B+树的优点是查找快速,但是B+树的更新往往会导致从根节点到目标叶节点路径上所有节点的更新。如何管理TNC和LPT树又有几个问题需要解决:
1) 构造问题:树根节点如何找到;树中间节点和叶节点如何存储到介质上;
2) 读问题:树节点如何根据各种目的进行快速索引;
3) 写问题:树节点如何安全快速地进行添加、更新、删除等操作;
由于TNC和LPT树的规模、目的差异都很大,以上的几个问题的解决方法也不尽相同,后面再分专题进行介绍。其核心对象模型和对象关系设计如下。其中细线条代表关联关系,粗线条代表组合关系,黑色代表内存对象,红色代表flash对象,即需要写入flash的数据。
从对象模型中可以基本看出,UBIFS文件系统利用了vfs层、页缓存层和通用块层,但不进过io调度层,其在系统中的位置和系统的层次结构介绍如下:
a) vfs层核心对象file;b) 页缓存层核心对象address_space;
c) 通用块层核心数据对象super_block,inode;
d) ubifs层核心数据对象ubifs_info。
其中ubifs_info主要维护三个对象:LPT、TNC和journal,其主要字段解释如下:
- nroot: LPT的对象树;
- lpt_cnext:用于提交LPT更新的对象链表;
- lpt_heap:用于分配LEB的对象优先队列;
- buds:node位置信息对象;
- jheads:日志对象;
- zroot:node的对象树(TNC);
- cnext:用于提交node更新的对象链表;
4. 对象持久化设计
ubifs文件系统对设备空间的划分如下,其中log、LPT、orphan、main区的具体大小取决于flash的物理大小:4.1 super block area
super block 使用LEB0,其描述的文件系统基本信息,如index tree fanout, default compression type (zlib or LZO), log area size等等。由格式化工具在格式化时写入,对ubifs只读。
4.2 master node area
master area使用LEB1和LEB2,两个LEB相互备份。这个是为了恢复着想,因为有两种情况会导致主节点损坏或丢失。第一种情况就是当主节点正在被写入的时候突然断电;第二种情况是可能是flash介质自身损坏。有了两个备份的LEB,就可以根据情况去恢复。
master area保存着commit number、root index lnum和offset、start log lnum和offset、start index lnum和offset、root lpt lnum 等信息,每次提交时会更新master area上这些信息。
4.3 log area
上面我们提到了UBIFS中这样的树状结构是保存在flash中,那么就带来了一个问题,每次更新文件,相应的文件信息和数据都会发生变化,那么这颗树种的结点也会发生变化。而我们知道NANDFLASH的特点,每次重新写入之前必须擦除,可见这样频繁的操作带来的是效率的低下。为了降低片上树结点频繁的更新,UBIFS中创建了log区,按日志形式记录树节点的位置信息leb:offs修改,然后一次提交到main区上,这样就降低了更新的频率。
存于log的节点类型为UBIFS_REF_NODE,其flash的表示为ubifs_ref_node,内存的表示为ubifs_bud,主要记录node的位置信息leb:offs。ubifs_bud按RB树组织,以lnum为key。
mount时会扫描log区,读出bud并重新索引。这个过程叫回放(replay)。umount时会把bud提交到log区。
4.4 lpt area
LPT主要用对对LEB的分配、回收、状态查询(free、dirty、index、etc.)。
我们上面提到了log area的目的,就是降低数据的更新频率。但是数据如何更新呢?也就是说,这些新添加的数据写往何处?所以必须对flash中每一个块的空间使用情况有一个了解,这就是LPT(LEB properties tree)的目的。LPT也是B+树,单比index tree小很多,其主要包含三个重要的参数:free space、dirty space 和index or data。
mount时,判断如果lpt_sz(nnode, pnode所占大小)大于一个LEB,自动使能big_lpt 模式和垃圾回收功能。
LPT区只在提交时更新。
4.5 orphan area
link数为0的inode节点,这个inode号被添加到一个orphan RB-tree
commit时,孤儿树中新孤儿被写到orphan area, mount时会扫描orphan区,删除orphan节点。
4. 6 main area
文件系统的数据和索引节点,作为B+树的index node存储在main区。 具体结构如下:

5. 参考资料
linux kernel 2.6.32—— 完 ——