原文:http://3dobe.com/archives/44/
引言
做搜索技术的不可能不接触分词器。个人认为为什么搜索引擎无法被数据库所替代的原因主要有两点,一个是在数据量比较大的时候,搜索引擎的查询速度快,第二点在于,搜索引擎能做到比数据库更理解用户。第一点好理解,每当数据库的单个表大了,就是一件头疼的事,还有在较大数据量级的情况下,你让数据库去做模糊查询,那也是一件比较吃力的事(当然前缀匹配会好得多),设计上就应当避免。关于第二点,搜索引擎如何理解用户,肯定不是简单的靠匹配,这里面可以加入很多的处理,甚至加入各种自然语言处理的高级技术,而比较通用且基本的方法就是靠分词器来完成,而且这是一种比较简单而且高效的处理方法。
分词技术是搜索技术里面的一块基石。很多人用过,如果你只是为了简单快速地搭一个搜索引擎,你确实不用了解太深。但一旦涉及效果问题,分词器上就可以做很多文章。例如, 在实我们际用作电商领域的搜索的工作中,类目预判的实现就极须依赖分词,至少需要做到可以对分词器动态加规则。再一个简单的例子,如果你的优化方法就是对不同的词分权重,提高一些重点词的权重的话,你就需要依赖并理解分词器。本文将根据ik分配器的原码对其实现做一定分析。其中的重点,主要3点,1、词典树的构建,即将现在的词典加载到一个内存结构中去, 2、词的匹配查找,也就相当生成对一个句话中词的切分方式,3、歧义判断,即对不同切分方式的判定,哪种应是更合理的。 代码原网址为:[https://code.google.com/p/ik-analyzer/](https://code.google.com/p/ik-analyzer/) 已上传github,可访问:[https://github.com/quentinxxz/Search/tree/master/IKAnalyzer2012FF_hf1_source/](https://github.com/quentinxxz/Search/tree/master/IKAnalyzer2012FF_hf1_source/)
词典
做后台数据相关操作,一切工作的源头都是数据来源了。IK分词器为我们词供了三类词表分别是:1、主词表 main2012.dic 2、量词表quantifier.dic 3、停用词stopword.dic。
Dictionary为字典管理类中,分别加载了这个词典到内存结构中。具体的字典代码,位于org.wltea.analyzer.dic.DictSegment。 这个类实现了一个分词器的一个核心数据结构,即Tire Tree。
Tire Tree(字典树)是一种结构相当简单的树型结构,用于构建词典,通过前缀字符逐一比较对方式,快速查找词,所以有时也称为前缀树。具体的例子如下。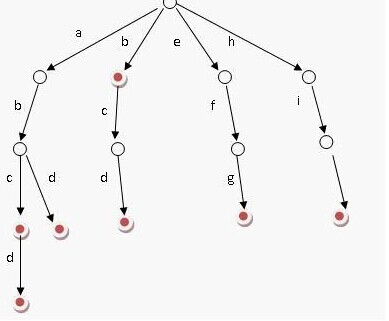
图1
从左来看,abc,abcd,abd,b,bcd…..这些词就是存在树中的单词。当然中文字符也可以一样处理,但中文字符的数目远多于26个,不应该以位置代表字符(英文的话,可以每节点包完一个长度为26的数组),如此的话,这棵tire tree会变得相当扩散,并占用内存,因而有一个tire Tree的变种,三叉字典树(Ternary Tree),保证占用较小的内存。Ternary Tree不在ik分词器中使用,所以不在此详述,请参考文章http://www.cnblogs.com/rush/archive/2012/12/30/2839996.html
IK中采用的是一种比方简单的实现。先看一下,DictSegment类的成员:
class DictSegment implements Comparable<DictSegment>{
//公用字典表,存储汉字
private static final Map<Character , Character> charMap = new HashMap<Character , Character>(16 , 0.95f);
//数组大小上限
private static final int ARRAY_LENGTH_LIMIT = 3;
//Map存储结构
private Map<Character , DictSegment> childrenMap;
//数组方式存储结构
private DictSegment[] childrenArray;
//当前节点上存储的字符
private Character nodeChar;
//当前节点存储的Segment数目
//storeSize <=ARRAY_LENGTH_LIMIT ,使用数组存储, storeSize >ARRAY_LENGTH_LIMIT ,则使用Map存储
private int storeSize = 0;
//当前DictSegment状态 ,默认 0 , 1表示从根节点到当前节点的路径表示一个词
private int nodeState = 0;
……
这里有两种方式去存储,根据ARRAY_LENGTH_LIMIT作为阈值来决定,如果当子节点数,不太于阈值时,采用数组的方式childrenArray来存储,当子节点数大于阈值时,采用Map的方式childrenMap来存储,childrenMap是采用HashMap实现的。这样做好处在于,节省内存空间。因为HashMap的方式的方式,肯定是需要预先分配内存的,就可能会存在浪费的现象,但如果全都采用数组去存组(后续采用二分的方式查找),你就无法获得O(1)的算法复杂度。所以这里采用了两者方式,当子节点数很少时,用数组存储,当子结点数较多时候,则全部迁至hashMap中去。在构建过程中,会将每个词一步步地加入到字典树中,这是一个递归的过程:
/**
* 加载填充词典片段
* @param charArray
* @param begin
* @param length
* @param enabled
*/
private synchronized void fillSegment(char[] charArray , int begin , int length , int enabled){
……
//搜索当前节点的存储,查询对应keyChar的keyChar,如果没有则创建
DictSegment ds = lookforSegment(keyChar , enabled);
if(ds != null){
//处理keyChar对应的segment
if(length > 1){
//词元还没有完全加入词典树
ds.fillSegment(charArray, begin + 1, length - 1 , enabled);
}else if (length == 1){
//已经是词元的最后一个char,设置当前节点状态为enabled,
//enabled=1表明一个完整的词,enabled=0表示从词典中屏蔽当前词
ds.nodeState = enabled;
}
}
}
其中lookforSegment,就会在所在子树的子节点中查找,如果是少于ARRAY_LENGTH_LIMIT阈值,则是为数组存储,采用二分查找;如果大于ARRAY_LENGTH_LIMIT阈值,则为HashMap存储,直接查找。
词语切分
IK分词器,基本可分为两种模式,一种为smart模式,一种为非smart模式。例如原文:
张三说的确实在理
smart模式的下分词结果为:
张三 | 说的 | 确实 | 在理
而非smart模式下的分词结果为:
张三 | 三 | 说的 | 的确 | 的 | 确实 | 实在 | 在理
可见非smart模式所做的就是将能够分出来的词全部输出;smart模式下,IK分词器则会根据内在方法输出一个认为最合理的分词结果,这就涉及到了歧义判断。
首来看一下最基本的一些元素结构类:
public class Lexeme implements Comparable<Lexeme>{
……
//词元的起始位移
private int offset;
//词元的相对起始位置
private int begin;
//词元的长度
private int length;
//词元文本
private String lexemeText;
//词元类型
private int lexemeType;
……
这里的Lexeme(词元),就可以理解为是一个词语或个单词。其中的begin,是指其在输入文本中的位置。注意,它是实现Comparable的,起始位置靠前的优先,长度较长的优先,这可以用来决定一个词在一条分词结果的词元链中的位置,可以用于得到上面例子中分词结果中的各个词的顺序。
/*
* 词元在排序集合中的比较算法
* @see java.lang.Comparable#compareTo(java.lang.Object)
*/
public int compareTo(Lexeme other) {
//起始位置优先
if(this.begin < other.getBegin()){
return -1;
}else if(this.begin == other.getBegin()){
//词元长度优先
if(this.length > other.getLength()){
return -1;
}else if(this.length == other.getLength()){
return 0;
}else {//this.length < other.getLength()
return 1;
}
}else{//this.begin > other.getBegin()
return 1;
}
}
还有一个重要的结构就是词元链,声明如下
/**
* Lexeme链(路径)
*/
class LexemePath extends QuickSortSet implements Comparable<LexemePath>
一条LexmePath,你就可以认为是上述分词的一种结果,根据前后顺序组成一个链式结构。可以看到它实现了QuickSortSet,所以它本身在加入词元的时候,就在内部完成排序,形成了一个有序的链,而排序规则就是上面Lexeme的compareTo方法所实现的。你也会注意到,LexemePath也是实现Comparable接口的,这就是用于后面的歧义分析用的,下一节介绍。
另一个重要的结构是AnalyzeContext,这里面就主要存储了输入信息 的文本,切分出来的lemexePah ,分词结果等一些相关的上下文信息。
IK中默认用到三个子分词器,分别是LetterSegmenter(字母分词器),CN_QuantifierSegment(量词分词器),CJKSegmenter(中日韩分词器)。分词是会先后经过这三个分词器,我们这里重点根据CJKSegment分析。其核心是一个analyzer方法。
public void analyze(AnalyzeContext context) {
…….
//优先处理tmpHits中的hit
if(!this.tmpHits.isEmpty()){
//处理词段队列
Hit[] tmpArray = this.tmpHits.toArray(new Hit[this.tmpHits.size()]);
for(Hit hit : tmpArray){
hit = Dictionary.getSingleton().matchWithHit(context.getSegmentBuff(), context.getCursor() , hit);
if(hit.isMatch()){
//输出当前的词
Lexeme newLexeme = new Lexeme(context.getBufferOffset() , hit.getBegin() , context.getCursor() - hit.getBegin() + 1 , Lexeme.TYPE_CNWORD);
context.addLexeme(newLexeme);
if(!hit.isPrefix()){//不是词前缀,hit不需要继续匹配,移除
this.tmpHits.remove(hit);
}
}else if(hit.isUnmatch()){
//hit不是词,移除
this.tmpHits.remove(hit);
}
}
}
//*********************************
//再对当前指针位置的字符进行单字匹配
Hit singleCharHit = Dictionary.getSingleton().matchInMainDict(context.getSegmentBuff(), context.getCursor(), 1);
if(singleCharHit.isMatch()){//首字成词
//输出当前的词
Lexeme newLexeme = new Lexeme(context.getBufferOffset() , context.getCursor() , 1 , Lexeme.TYPE_CNWORD);
context.addLexeme(newLexeme);
//同时也是词前缀
if(singleCharHit.isPrefix()){
//前缀匹配则放入hit列表
this.tmpHits.add(singleCharHit);
}
}else if(singleCharHit.isPrefix()){//首字为词前缀
//前缀匹配则放入hit列表
this.tmpHits.add(singleCharHit);
}
……
}
从下半截代码看起,这里的matchInMain就是用于匹配主题表内的词的方法。这里的主词表已经加载至一个字典树之内,所以整个过程也就是一个从树根层层往下走的一个层层递归的方式,但这里只处理单字,不会去递归。而匹配的结果一共三种UNMATCH(未匹配),MATCH(匹配), PREFIX(前缀匹配),Match指完全匹配已经到达叶子节点,而PREFIX是指当前对上所经过的匹配路径存在,但未到达到叶子节点。此外一个词也可以既是MATCH也可以是PREFIX,例如图1中的abc。前缀匹配的都被存入了tempHit中去。而完整匹配的都存入context中保存。
继续看上半截代码,前缀匹配的词不应该就直接结束,因为有可能还能往后继续匹配更长的词,所以上半截代码所做的就是对这些词继续匹配。matchWithHit,就是在当前的hit的结果下继续做匹配。如果得到MATCH的结果,便可以在context中加入新的词元。
通过这样不段匹配,循环补充的方式,我们就可以得到所有的词,至少能够满足非smart模式下的需求。
歧义判断
IKArbitrator(歧义分析裁决器)是处理歧义的主要类。
如果觉着我这说不清,也可以参考的博客:http://fay19880111-yeah-net.iteye.com/blog/1523740
在上一节中,我们提到LexemePath是实现compareble接口的。
public int compareTo(LexemePath o) {
//比较有效文本长度
if(this.payloadLength > o.payloadLength){
return -1;
}else if(this.payloadLength < o.payloadLength){
return 1;
}else{
//比较词元个数,越少越好
if(this.size() < o.size()){
return -1;
}else if (this.size() > o.size()){
return 1;
}else{
//路径跨度越大越好
if(this.getPathLength() > o.getPathLength()){
return -1;
}else if(this.getPathLength() < o.getPathLength()){
return 1;
}else {
//根据统计学结论,逆向切分概率高于正向切分,因此位置越靠后的优先
if(this.pathEnd > o.pathEnd){
return -1;
}else if(pathEnd < o.pathEnd){
return 1;
}else{
//词长越平均越好
if(this.getXWeight() > o.getXWeight()){
return -1;
}else if(this.getXWeight() < o.getXWeight()){
return 1;
}else {
//词元位置权重比较
if(this.getPWeight() > o.getPWeight()){
return -1;
}else if(this.getPWeight() < o.getPWeight()){
return 1;
}
}
}
}
}
}
return 0;
}
显然作者在这里定死了一些排序的规则,依次比较有效文本长度、词元个数、路径跨度…..
IKArbitrator有一个judge方法,对不同路径做了比较。
private LexemePath judge(QuickSortSet.Cell lexemeCell , int fullTextLength){
//候选路径集合
TreeSet<LexemePath> pathOptions = new TreeSet<LexemePath>();
//候选结果路径
LexemePath option = new LexemePath();
//对crossPath进行一次遍历,同时返回本次遍历中有冲突的Lexeme栈
Stack<QuickSortSet.Cell> lexemeStack = this.forwardPath(lexemeCell , option);
//当前词元链并非最理想的,加入候选路径集合
pathOptions.add(option.copy());
//存在歧义词,处理
QuickSortSet.Cell c = null;
while(!lexemeStack.isEmpty()){
c = lexemeStack.pop();
//回滚词元链
this.backPath(c.getLexeme() , option);
//从歧义词位置开始,递归,生成可选方案
this.forwardPath(c , option);
pathOptions.add(option.copy());
}
//返回集合中的最优方案
return pathOptions.first();
}
其核心处理思想是从第一个词元开始,遍历各种路径,然后加入至一个TreeSet中,实现了排序,取第一个即可。
其它说明
1、stopWord(停用词),会在最后输出结果的阶段(AnalyzeContext. getNextLexeme)被移除,不会在分析的过程中移除,否则也会存在风险。
2、可以从LexemePath的compareTo方法中看出,Ik的排序方法特别粗略,如果比较发现path1的词个数,比path2的个数少,就直接判定path1更优。其实这样的规则,并未完整的参考各个分出来的词的实际情况,我们可能想加入每个词经统计出现的频率等信息,做更全面的打分,这样IK原有的比较方法就是不可行的。
关于如何修改的思路可以参考另一篇博客,其中介绍了一种通过最短路径思路去处理的方法:http://www.hankcs.com/nlp/segment/n-shortest-path-to-the-java-implementation-and-application-segmentation.html
3、未匹配的单字,不论是否在smart模式下,最后都会输出,其处理时机在最后输出结果阶段,具体代码位于在AnalyzeContext. outputToResult方法中。
首发于iteye:http://quentinxxz.iteye.com/blog/2180215
本站链接:http://3dobe.com/archives/44/