可迭代的:对象下有__iter__方法的都是可迭代的对象 迭代器:对象.__iter__()得到的结果就是迭代器 迭代器的特性: 迭代器.__next__() 取下一个值 优点: 1.提供了一种统一的迭代对象的方式,不依赖于索引 2.惰性计算 缺点: 1.无法获取迭代器的长度 2.一次性的,只能往后取值,不能往前退,不能像索引那样去取得某个位置的值 生成器:函数内带有yield关键字,那么这个函数执行的结果就是生成器 生成器本质就是迭代器 def func(): n=0 while True: yield n n+=1 g=func() res=next(g) res=next(g) for i in g: pass 总结yield的功能: 1.相当于把__iter__和__next__方法封装到函数内部 2.与return比,return只能返回一次,而yield能返回多次 3.函数暂停已经继续运行的状态是通过yield保存的 yield的表达式形式: food=yield def eater(name): print('%s start to eat' %name) while True: food=yield print('%s eat %s' %(name,food)) e=eater('zhejiangF4') #e.send与next(e)的区别 #1.如果函数内yield是表达式形式,那么必须先next(e) #2.二者的共同之处是都可以让函数在上次暂停的位置继续运行,不一样的地方在于 send在触发下一次代码的执行时,会顺便给yield传一个值 #协程函数的定义? #协程函数的应用?
定义一个简单的装饰器,完成,协和函数先next这个动作、
def init(func): def wrapper(*args,**kwargs): res=func(*args,**kwargs) next(res) return res return wrapper @init #eater=init(eater) def eater(name): print('%s start to eat' % name) food_list=[] while True: food = yield food_list print('%s eat %s' % (name, food)) food_list.append(food) e = eater('zhejiangF4') #wrapper('zhengjiangF4') # print(e) # next(e) #e.send(None) print(e.send('123')) print(e.send('123')) print(e.send('123')) print(e.send('123')) print(e.send('123'))
写个函数,源源不断往外,爬网页
from urllib.request import urlopen def get(): while True: url=yield res=urlopen(url).read() print(res) g=get() next(g) g.send('http://www.python.org')
一个功能,递归,查找,文 件夹下的文件
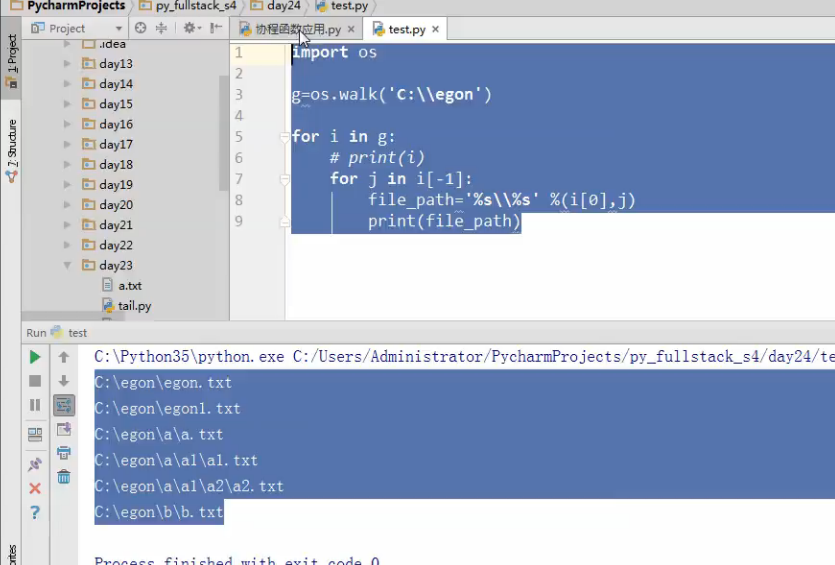
面向过程,编程思想例题
#grep -rl 'python' C:egon import os,time def init(func): def wrapper(*args,**kwargs): res=func(*args,**kwargs) next(res) return res return wrapper #找到一个绝对路径,往下一个阶段发一个 @init def search(target): '找到文件的绝对路径' while True: dir_name=yield #dir_name='C:\egon' print('车间search开始生产产品:文件的绝对路径') time.sleep(2) g = os.walk(dir_name) for i in g: # print(i) for j in i[-1]: file_path = '%s\%s' % (i[0], j) target.send(file_path) @init def opener(target): '打开文件,获取文件句柄' while True: file_path=yield print('车间opener开始生产产品:文件句柄') time.sleep(2) with open(file_path) as f: target.send((file_path,f)) @init def cat(target): '读取文件内容' while True: file_path,f=yield print('车间cat开始生产产品:文件的一行内容') time.sleep(2) for line in f: target.send((file_path,line)) @init def grep(pattern,target): '过滤一行内容中有无python' while True: file_path,line=yield print('车间grep开始生产产品:包含python这一行内容的文件路径') time.sleep(0.2) if pattern in line: target.send(file_path) @init def printer(): '打印文件路径' while True: file_path=yield print('车间printer开始生产产品:得到最终的产品') time.sleep(2) print(file_path) g=search(opener(cat(grep('python',printer())))) g.send('C:\egon') g.send('D:\dir1') g.send('E:\dir2') #面向过程的编程思想:流水线式的编程思想,在设计程序时,需要把整个流程设计出来 #优点: #1:体系结构更加清晰 #2:简化程序的复杂度 #缺点: #1:可扩展性极其的差,所以说面向过程的应用场景是:不需要经常变化的软件,如:linux内核,httpd,git等软件
列表生成式
面试经常会问到
#三元表达式 # name='alex' # name='egon' # # res='SB' if name == 'alex' else 'shuai' # print(res) # egg_list=[] # # for i in range(100): # egg_list.append('egg%s' %i) # print(egg_list) # #先进行for循环,然后,再去判断if子句,然后,再去执行%i把值打印出来 # l=['egg%s' %i for i in range(100) if i > 50] # print(l) l=[1,2,3,4] s='hello' #把列表l中的每个数字分别与下字符串中的每个字母拼成元组,拼一遍,如(1,'h')(1,'e'),也可以不加if判断,默认全是真 # l1=[(num,s1) for num in l if num > 2 for s1 in s] # print(l1) # l1=[] # for num in l: # for s1 in s: # t=(num,s1) # l1.append(t) # print(l1) 把下面的,列出文件夹下的文件和列表,进行,列表生成式的改进,列表生成式,本身就是append往里面 # import os # g=os.walk('C:\egon') # file_path_list=[] # for i in g: # # print(i) # for j in i[-1]: # file_path_list.append('%s\%s' %(i[0],j)) # # print(file_path_list) # # g=os.walk('C:\egon') # l1=['%s\%s' %(i[0],j) for i in g for j in i[-1]] # print(l1)
模拟数据库查询

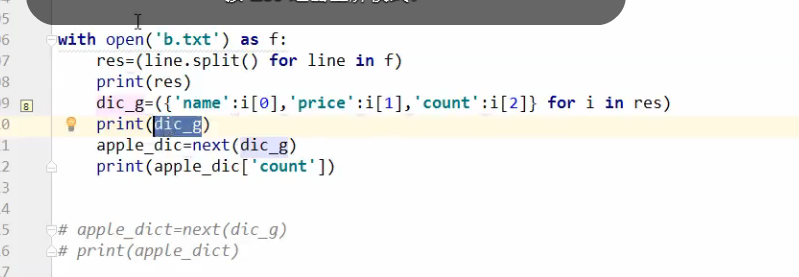
# # l=['egg%s' %i for i in range(100)] # print(l) 如果用列表生成式,列表是保存在内存中的如果数据太大,直接 死掉,所以这时候就要用到生成器,表达式 也很简单,直接用()括起来就行,然后,再每次next,或者用for来进行迭代,但是要注意,生成器,也即迭代器, 是一次性的,再用,还要再生成 # g=l=('egg%s' %i for i in range(1000000000000000000000000000000000000)) # print(g) # print(next(g)) # print(next(g)) # for i in g: # print(i) # f=open('a.txt'),a这个文件,每一行两边都有空格,需要把空格 去掉 # l=[] # for line in f: # line=line.strip() # l.append(line) # # print(l) # f.seek(0) # l1=[line.strip() for line in f] 列表生成式是中括号,一次全放内存,不推荐, # print(l1) # # f.seek(0) 此鼠标,要返回首页,很好的解释了,迭代器,是一次性的 # g=(line.strip() for line in f) 生成器表达式,惰性的,用一个取一个,不用担心卡死内存 # print(g) # print(next(g)) # f=open('a.txt') # g=(line.strip() for line in f) # l=list(g) # print(l) sum这个函数,()中传的只要是个可迭代的对像,他像for一样,一次next一个,把你传进去的变量, 最后求和 # nums_g=(i for i in range(3)) # # # print(sum([1,2,3,4])) # print(sum(nums_g)) 下图中的b.txt类似于等,把文件里面的值求和 mac 10000 1 电脑 5000 1 # money_l=[] # with open('b.txt') as f: # for line in f: # goods=line.split() # res=float(goods[-1])*float(goods[-2]) # money_l.append(res) # print(money_l) #下面是用声明式编程,进行的求和 # f=open('b.txt') # g=(float(line.split()[-1])*float(line.split()[-2]) for line in f) # # print(sum(g)) # with open('b.txt') as f: # print(sum((float(line.split()[-1])*float(line.split()[-2]) for line in f))) # res=[] # with open('b.txt') as f: # for line in f: # # print(line) # l=line.split() # # print(l) # d={} # d['name']=l[0] # d['price']=l[1] # d['count']=l[2] # res.append(d) # print(res) # with open('b.txt') as f: # res=(line.split() for line in f) # print(res) # dic_g=({'name':i[0],'price':i[1],'count':i[2]} for i in res) # print(dic_g) # apple_dic=next(dic_g) # print(apple_dic['count']) # apple_dict=next(dic_g) # print(apple_dict) #取出单价>10000 with open('b.txt') as f: res=(line.split() for line in f) # print(res) dic_g=({'name':i[0],'price':i[1],'count':i[2]} for i in res if float(i[1]) > 10000) print(dic_g) print(list(dic_g)) # for i in dic_g: # print(i)