软件设计最大的敌人,就是应付需求不断的变化。变化有时候是无穷尽的,于是项目开发就在反复的修改、更新中无限期地延迟交付的日期。变化如悬在头顶的达摩克斯之剑,令许多软件工程专家一筹莫展。正如无法找到解决软件开发的“银弹”,要彻底将变化扼杀在摇篮之中,看来也是不可能完成的任务。那么,积极地面对“变化”,方才是可取的态度。于是,极限编程(XP)的倡导者与布道者Kent Beck提出要“拥抱变化”,从软件工程方法的角度,提出了应对“变化”的解决方案。而本文则试图从软件设计方法的角度,来探讨如何在软件设计过程中,解决未来可能的变化,其方法就是——封装变化。
《封装变化》系列共分为三部分:
1、Part One
2、Part Two
3、Part Three
1、Part One
2、Part Two
3、Part Three
软件设计最大的敌人,就是应付需求不断的变化。变化有时候是无穷尽的,于是项目开发就在反复的修改、更新中无限期地延迟交付的日期。变化如悬在头顶的达摩克斯之剑,令许多软件工程专家一筹莫展。正如无法找到解决软件开发的“银弹”,要彻底将变化扼杀在摇篮之中,看来也是不可能完成的任务。那么,积极地面对“变化”,方才是可取的态度。于是,极限编程(XP)的倡导者与布道者Kent Beck提出要“拥抱变化”,从软件工程方法的角度,提出了应对“变化”的解决方案。而本文则试图从软件设计方法的角度,来探讨如何在软件设计过程中,解决未来可能的变化,其方法就是——封装变化。
设计模式是“封装变化”方法的最佳阐释。无论是创建型模式、结构型模式还是行为型模式,归根结底都是寻找软件中可能存在的“变化”,然后利用抽象的方式对这些变化进行封装。由于抽象没有具体的实现,就代表了一种无限的可能性,使得其扩展成为了可能。所以,我们在设计之初,除了要实现需求所设定的用例之外,还需要标定可能或已经存在的“变化”之处。封装变化,最重要的一点就是发现变化,或者说是寻找变化。
GOF对设计模式的分类,已经彰显了“封装变化”的内涵与精髓。创建型模式的目的就是封装对象创建的变化。例如Factory Method模式和Abstract Factory模式,建立了专门的抽象的工厂类,以此来封装未来对象的创建所引起的可能变化。而Builder模式则是对对象内部的创建进行封装,由于细节对抽象的可替换性,使得将来面对对象内部创建方式的变化,可以灵活的进行扩展或替换。
至于结构型模式,它关注的是对象之间组合的方式。本质上说,如果对象结构可能存在变化,主要在于其依赖关系的改变。当然对于结构型模式来说,处理变化的方式不仅仅是封装与抽象那么简单,还要合理地利用继承与聚合的方法,灵活地表达对象之间的依赖关系。例如Decorator模式,描述的就是对象间可能存在的多种组合方式,这种组合方式是一种装饰者与被装饰者之间的关系,因此封装这种组合方式,抽象出专门的装饰对象显然正是“封装变化”的体现。同样地,Bridge模式封装的则是对象实现的依赖关系,而Composite模式所要解决的则是对象间存在的递归关系。
行为型模式关注的是对象的行为。行为型模式需要做的是对变化的行为进行抽象,通过封装以达到整个架构的可扩展性。例如策略模式,就是将可能存在变化的策略或算法抽象为一个独立的接口或抽象类,以实现策略扩展的目的。Command模式、State模式、Vistor模式、Iterator模式概莫如是。或者封装一个请求(Command模式),或者封装一种状态(State模式),或者封装“访问”的方式(Visitor模式),或者封装“遍历”算法(Iterator模式)。而这些所要封装的行为,恰恰是软件架构中最不稳定的部分,其扩展的可能性也最大。将这些行为封装起来,利用抽象的特性,就提供了扩展的可能。
利用设计模式,通过封装变化的方法,可以最大限度的保证软件的可扩展性。面对纷繁复杂的需求变化,虽然不可能完全解决因为变化带来的可怕梦魇,然而,如能在设计之初预见某些变化,仍有可能在一定程度上避免未来存在的变化为软件架构带来的灾难性伤害。从此点看,虽然没有“银弹”,但从软件设计方法的角度来看,设计模式也是一枚不错的“铜弹”了。
考虑一个日志记录工具。目前需要提供一个方便的日志,使得客户可以轻松地完成日志的记录。该日志要求被记录到指定的文本文件中,记录的内容属于字符串类型,其值由客户提供。我们可以非常容易地定义一个日志对象:
public class Log
{
public void Write(string target, string log)
{
//实现内容;
}
}
public class Log
{
public void Write(string target, string log)
{
//实现内容;
}
}
当客户需要调用日志的功能时,可以创建日志对象,完成日志的记录:
Log log = new Log();
log.Write(“error.log”, “log”);
Log log = new Log();
log.Write(“error.log”, “log”);
然而随着日志记录的频繁使用,有关日志的文件越来越多,日志的查询与管理也变得越不方便。此时,客户提出,需要改变日志的记录方式,将日志内容写入到指定的数据表中。显然,如果仍然按照前面的设计,具有较大的局限性。
现在我们回到设计之初,想象一下对于日志API的设计,需要考虑到这样的变化吗?这里存在两种设计理念,即渐进的设计和计划的设计。从本例来分析,要求设计者在设计初就考虑到日志记录方式在未来的可能变化,并不容易。再者,如果在最开始就考虑全面的设计,会产生设计上的冗余。因此,采用计划的设计固然具有一定的前瞻性,但一方面对设计者的要求过高,同时也会产生一些缺陷。那么,采用渐进的设计时,遇到需求变化时,利用重构的方法,改进现有的设计,又需要考虑未来的再一次变化吗?这是一个见仁见智的问题。对于本例而言,我们完全可以直接修改Write()方法,接受一个类型判断的参数,从而解决此问题。但这样的设计,自然要担负因为未来可能的再一次变化,而导致代码大量修改的危险,例如,我们要求日志记录到指定的Xml文件中。
所以,变化是完全可能的。在时间和技术能力允许的情况下,我更倾向于将变化对设计带来的影响降低到最低。此时,我们需要封装变化。
在封装变化之前,我们需要弄清楚究竟是什么发生了变化?从需求看,是日志记录的方式发生了变化。从这个概念分析,可能会导致两种不同的结果。一种情形是,我们将日志记录的方式视为一种行为,确切的说,是用户的一种请求。另一种情形则从对象的角度来分析,我们将各种方式的日志看作不同的对象,它们调用接口相同的行为,区别仅在于创建的是不同的对象。前者需要我们封装“用户请求的变化”,而后者需要我们封装“日志对象创建的变化”。
封装“用户请求的变化”,在这里就是封装日志记录可能的变化。也就是说,我们需要把日志记录行为抽象为一个单独的接口,然后才分别定义不同的实现。如图一所示:
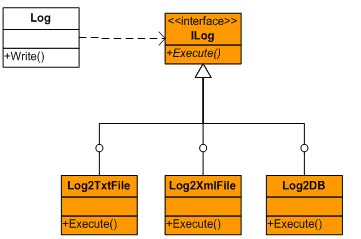
图一:封装日志记录行为的变化
如果熟悉设计模式,可以看到图一所表示的结构正是Command模式的体现。由于我们对日志记录行为进行了接口抽象,用户就可以自由地扩展日志记录的方式,只需要实现ILog接口即可。至于Log对象,则存在与ILog接口的弱依赖关系:
public class Log
{
private ILog log;
public Log(ILog log)
{
this.log = log;
}
{
private ILog log;
public Log(ILog log)
{
this.log = log;
}
public void Write(string target, string logValue)
{
log.Execute(target, logValue);
}
}
{
log.Execute(target, logValue);
}
}
我们也可以通过封装“日志对象创建的变化”实现日志API的可扩展性。在这种情况下,日志会根据记录方式的不同,被定义为不同的对象。当我们需要记录日志时,就创建相应的日志对象,然后调用该对象的Write()方法,实现日志的记录。此时,可能会发生变化的是需要创建的日志对象,那么要封装这种变化,就可以定义一个抽象的工厂类,专门负责日志对象的创建,如图二所示:
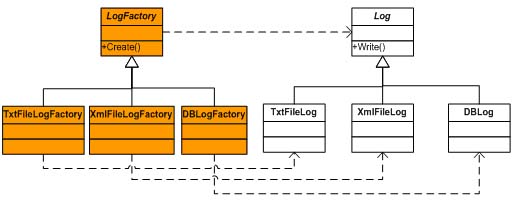
图二:封装日志对象创建的变化
图二是Factory Method模式的体现,由抽象类LogFactory专门负责Log对象的创建。如果用户需要记录相应的日志,例如要求日志记录到数据库,需要先创建具体的LogFactory对象:
LogFactory factory = new DBLogFactory();
LogFactory factory = new DBLogFactory();
当在应用程序中,需要记录日志,那么再通过LogFactory对象来获取新的Log对象:
Log log = factory.Create();
log.Write(“ErrorLog”, “log”);
Log log = factory.Create();
log.Write(“ErrorLog”, “log”);
如果用户需要改变日志记录的方式为文本文件时,仅需要修改LogFactory对象的创建即可:
LogFactory factory = new TxtFileLogFactory();为了更好地理解“封装对象创建的变化”,我们再来看一个例子。假如,我们需要设计一个数据库组件,它能够访问微软的Sql Server数据库。根据ADO.Net的知识,我们需要使用如下的对象:
SqlConnection, SqlCommand, SqlDataAdapter等。
LogFactory factory = new TxtFileLogFactory();为了更好地理解“封装对象创建的变化”,我们再来看一个例子。假如,我们需要设计一个数据库组件,它能够访问微软的Sql Server数据库。根据ADO.Net的知识,我们需要使用如下的对象:
SqlConnection, SqlCommand, SqlDataAdapter等。
如果仅就Sql Server而言,在访问数据库时,我们可以直接创建这些对象:
SqlConnection connection = new SqlConnection(strConnection);
SqlCommand command = new SqlCommand(connection);
SqlDataAdapter adapter = new SqlDataAdapter();
SqlConnection connection = new SqlConnection(strConnection);
SqlCommand command = new SqlCommand(connection);
SqlDataAdapter adapter = new SqlDataAdapter();
在一个数据库组件中,充斥着如上的语句,显然是不合理的。它充满了僵化的坏味道,一旦要求支持其他数据库时,原有的设计就需要彻底的修改,这为扩展带来了困难。
那么我们来思考一下,以上的设计应该做怎样的修改?假定该数据库组件要求或者将来要求支持多种数据库,那么对于Connection,Command,DataAdapter等对象而言,就不能具体化为Sql Server的对象。也就是说,我们需要为这些对象建立一个继承的层次结构,为他们分别建立抽象的父类,或者接口。然后针对不同的数据库,定义不同的具体类,这些具体类又都继承或实现各自的父类,例如Connection对象:
<appSettings>
<add key=”db” value=”SqlDBFactory”/>
</appSettings>
<add key=”db” value=”SqlDBFactory”/>
</appSettings>
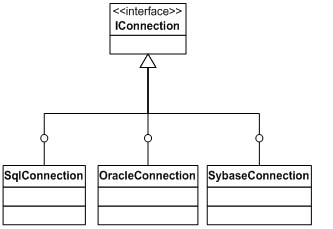
图三:Connection对象的层次结构
我为Connection对象抽象了一个统一的IConnection接口,而支持各种数据库的Connection对象都实现了IConnection接口。同样的,Command对象和DataAdapter对象也采用了相似的结构。现在,我们要创建对象的时候,可以利用多态的原理创建:
IConnection connection = new SqlConnection(strConnection);
IConnection connection = new SqlConnection(strConnection);
从这个结构可以看到,根据访问的数据库的不同,对象的创建可能会发生变化。也就是说,我们需要设计的数据库组件,以现在的结构来看,仍然存在无法应对对象创建发生变化的问题。利用“封装变化”的原理,我们有必要把创建对象的责任单独抽象出来,以进行有效地封装。例如,如上的创建对象的代码,就应该由专门的对象来负责。我们仍然可以建立一个专门的抽象工厂类DBFactory,并由它负责创建Connection,Command,DataAdapter对象。至于实现该抽象类的具体类,则与目标对象的结构相同,根据数据库类型的不同,定义不同的工厂类,类图如图四所示:
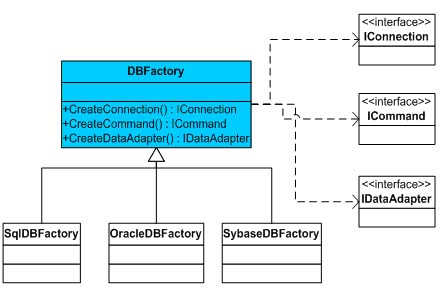
图四:DBFactory的类图
图四是一个典型的Abstract Factory模式的体现。类DBFactory中的各个方法均为abstract方法,所以我们也可以用接口来代替该类的定义。继承DBFactory类的各个具体类,则创建相对应的数据库类型的对象。以SqlDBFactory类为例,创建各自对象的代码如下:
public class SqlDBFactory: DBFactory
{
public override IConnection CreateConnection(string strConnection)
{
return new SqlConnection(strConnection);
}
public class SqlDBFactory: DBFactory
{
public override IConnection CreateConnection(string strConnection)
{
return new SqlConnection(strConnection);
}
public override ICommand CreateCommand(IConnection connection)
{
return new SqlCommand(connection);
}
{
return new SqlCommand(connection);
}
public override IDataAdapter CreateDataAdapter()
{
return new SqlDataAdapter();
}
}
{
return new SqlDataAdapter();
}
}
现在要创建访问Sql Server数据库的相关对象,就可以利用工厂类来获得。首先,我们可以在程序的初始化部分创建工厂对象:
DBFactory factory = new SqlDBFactory();
DBFactory factory = new SqlDBFactory();
然后利用该工厂对象创建相应的Connection,Command等对象:
IConnection connection = factory.CreateConnection(strConnection);
ICommand command = factory.CreateCommand(connection);
IConnection connection = factory.CreateConnection(strConnection);
ICommand command = factory.CreateCommand(connection);
由于我们利用了封装变化的原理,建立了专门的工厂类,以封装对象创建的变化。可以看到,当我们引入工厂类后,Connection,Command等对象的创建语句中,已经成功地消除了其与具体的数据库类型相依赖的关系。在如上的代码中,并未出现Sql之类的具体类型,如SqlConnection、SqlCommand等。也就是说,现在创建对象的方式是完全抽象的,是与具体实现无关的。无论是访问何种数据库,都与这几行代码无关。至于涉及到的数据库类型的变化,则全部抽象到DBFactory抽象类中了。需要更改访问数据库的类型,我们也只需要修改创建工厂对象的那一行代码,例如将Sql Server类型修改为Oracle类型:
DBFactory factory = new OracleDBFactory();
DBFactory factory = new OracleDBFactory();
很显然,这样的方式提高了数据库组件的可扩展性。我们将可能发生变化的部分封装起来,放到程序固定的部分,例如初始化部分,或者作为全局变量,更可以将这些可能发生变化的地方,放到配置文件中,通过读取配置文件的值,创建相对应的对象。如此一来,不需要修改代码,也不需要重新编译,仅仅是修改xml文件,就能实现数据库类型的改变。例如,我们创建如下的配置文件:
创建工厂对象的代码则相应修改如下:
string factoryName = ConfigurationSettings.AppSettings[“db”].ToString();
//DBLib为数据库组件的程序集:
DBFactory factory = (DBFactory)Activator.CreateInstance(“DBLib”,factoryName).Unwrap();
string factoryName = ConfigurationSettings.AppSettings[“db”].ToString();
//DBLib为数据库组件的程序集:
DBFactory factory = (DBFactory)Activator.CreateInstance(“DBLib”,factoryName).Unwrap();
为数据库组件的程序集:当我们需要将访问的数据库类型修改为Oracle数据库时,只需要将配置文件中的Value值修改为“OracleDBFactory”即可。这种结构具有很好的可扩展性,较好地解决了未来可能发生的需求变化所带来的问题。
设想这样一个需求,我们需要为自己的框架提供一个负责排序的组件。目前需要实现的是冒泡排序算法和快速排序算法,根据“面向接口编程”的思想,我们可以为这些排序算法提供一个统一的接口ISort,在这个接口中有一个方法Sort(),它能接受一个object数组参数。对数组进行排序后,返回该数组。接口的定义如下:
public interface ISort
{
void Sort(ref object[] beSorted);
}
{
void Sort(ref object[] beSorted);
}
其类图如下:
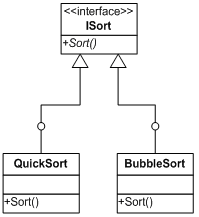
然而一般对于排序而言,排列是有顺序之分的,例如升序,或者降序,返回的结果也不相同。最简单的方法我们可以利用if语句来实现这一目的,例如在QuickSort类中:
public class QuickSort:ISort
{
private string m_SortType;
{
private string m_SortType;
public QuickSort(string sortType)
{
m_SortType = sortType;
}
{
m_SortType = sortType;
}
public void Sort(ref object[] beSorted)
{
if (m_SortType.ToUpper().Trim() == “ASCENDING”)
{
//执行升序的快速排序;
}
else
{
//执行降序的快速排序;
}
}
}
{
if (m_SortType.ToUpper().Trim() == “ASCENDING”)
{
//执行升序的快速排序;
}
else
{
//执行降序的快速排序;
}
}
}
当然,我们也可以将string类型的SortType定义为枚举类型,减少出现错误的可能性。然而仔细阅读代码,我们可以发现这样的代码是非常僵化的,一旦需要扩展,如果要求我们增加新的排序顺序,例如字典顺序,那么我们面临的工作会非常繁重。也就是说,变化产生了。通过分析,我们发现所谓排序的顺序,恰恰是排序算法中最关键的一环,它决定了谁排列在前,谁排列在后。然而它并不属于排序算法,而是一种比较的策略,后者说是比较的行为。
如果仔细分析实现ISort接口的类,例如QuickSort类,它在实现排序算法的时候,需要对两个对象作比较。按照重构的做法,实质上我们可以在Sort方法中抽取出一个私有方法Compare(),通过返回的布尔值,决定哪个对象在前,哪个对象在后。显然,可能发生变化的是这个比较行为,利用“封装抽象”的原理,就应该为该行为建立一个专有的接口ICompare,然而分别定义实现升序、降序或者字典排序的类对象。
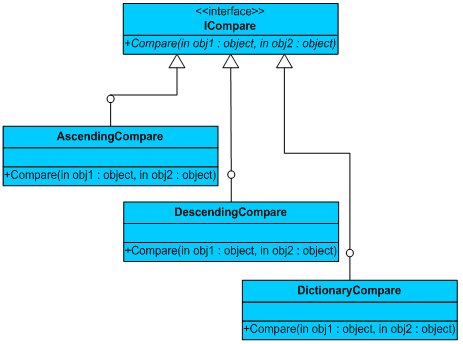
我们在每一个实现了ISort接口的类构造函数中,引入ICompare接口对象,从而建立起排序算法与比较算法的弱耦合关系(因为这个关系与抽象的ICompare接口相关),例如QuickSort类:
public class QuickSort:ISort
{
private ICompare m_Compare;
public QuickSort(ICompare compare)
{
m_Compare= compare;
}
public void Sort(ref object[] beSorted)
{
//实现略
for (int i = 0; i < beSorted.Length - 1; i++)
{
if (m_Compare.Compare(beSorted[i],beSorted[i+1))
{
//略;
}
}
//实现略
}
}
{
private ICompare m_Compare;
public QuickSort(ICompare compare)
{
m_Compare= compare;
}
public void Sort(ref object[] beSorted)
{
//实现略
for (int i = 0; i < beSorted.Length - 1; i++)
{
if (m_Compare.Compare(beSorted[i],beSorted[i+1))
{
//略;
}
}
//实现略
}
}
最后的类图如下:
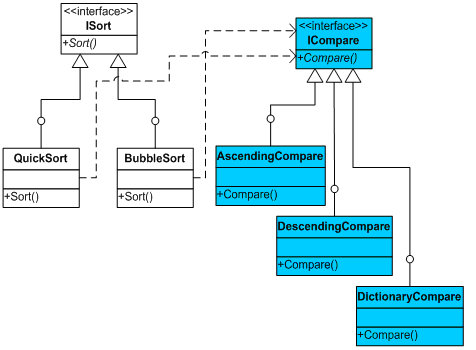
通过对比较策略的封装,以应对它的变化,显然是Stategy模式的设计。事实上,这里的排序算法也可能是变化的,例如实现二叉树排序。由于我们已经引入了“面向接口编程”的思想,我们完全可以轻易的添加一个新的类BinaryTreeSort,来实现ISort接口。对于调用方而言,ISort接口的实现,同样是一个Strategy模式。此时的类结构,完全是一个对扩展开发的状态,它完全能够适应类库调用者新需求的变化。
再以PetShop为例,在这个项目中涉及到订单的管理,例如插入订单。考虑到访问量的关系,PetShop为订单管理提供了同步和异步的方式。显然,在实际应用中只能使用这两种方式的其中一种,并由具体的应用环境所决定。那么为了应对这样一种可能会很频繁的变化,我们仍然需要利用“封装变化”的原理,建立抽象级别的对象,也就是IOrderStrategy接口:
public interface IOrderStrategy
{
void Insert(PetShop.Model.OrderInfo order);
}
{
void Insert(PetShop.Model.OrderInfo order);
}
然后定义两个类OrderSynchronous和OrderAsynchronous。类结构如下:
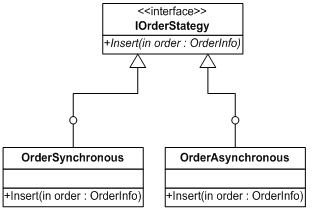
在PetShop中,由于用户随时都可能会改变插入订单的策略,因此对于业务层的订单领域对象而言,不能与具体的订单策略对象产生耦合关系。也就是说,在领域对象Order类中,不能new一个具体的订单策略对象,如下面的代码:
IOrderStrategy orderInsertStrategy = new OrderSynchronous();
在Martin Fowler的文章《IoC容器和Dependency Injection模式》中,提出了解决这类问题的办法,他称之为依赖注入。不过由于PetShop并没有使用诸如Sping.Net等IoC容器,因此解决依赖问题,通常是利用配置文件结合反射来完成的。在领域对象Order类中,是这样实现的:
public class Order
{
private static readonly IOrderStategy orderInsertStrategy = LoadInsertStrategy();
private static IOrderStrategy LoadInsertStrategy()
{
// Look up which strategy to use from config file
string path = ConfigurationManager.AppSettings[”OrderStrategyAssembly”];
string className = ConfigurationManager.AppSettings[”OrderStrategyClass”];
{
private static readonly IOrderStategy orderInsertStrategy = LoadInsertStrategy();
private static IOrderStrategy LoadInsertStrategy()
{
// Look up which strategy to use from config file
string path = ConfigurationManager.AppSettings[”OrderStrategyAssembly”];
string className = ConfigurationManager.AppSettings[”OrderStrategyClass”];
// Load the appropriate assembly and class
return (IOrderStrategy)Assembly.Load(path).CreateInstance(className);
}
}
return (IOrderStrategy)Assembly.Load(path).CreateInstance(className);
}
}
在配置文件web.config中,配置如下的Section:
<add key=”OrderStrategyAssembly” value=”PetShop.BLL”/>
<add key=”OrderStrategyClass” value=”PetShop.BLL.OrderSynchronous”/>
<add key=”OrderStrategyAssembly” value=”PetShop.BLL”/>
<add key=”OrderStrategyClass” value=”PetShop.BLL.OrderSynchronous”/>
这其实是一种折中的Service Locator模式。将定位并创建依赖对象的逻辑直接放到对象中,在PetShop的例子中,不失为一种好方法。毕竟在这个例子中,需要依赖注入的对象并不太多。但我们也可以认为是一种无奈的妥协的办法,一旦这种依赖注入的逻辑增多,为给程序者带来一定的麻烦,这时就需要一个专门的轻量级IoC容器了。
写到这里,似乎已经脱离了“封装变化”的主题。但事实上我们需要明白,利用抽象的方式封装变化,固然是应对需求变化的王道,但它也仅仅能解除调用者与被调用者相对的耦合关系,只要还涉及到具体对象的创建,即使引入了工厂模式,但具体的工厂对象的创建仍然是必不可少的。那么,对于这样一些业已被封装变化的对象,我们还应该充分利用“依赖注入”的方式来彻底解除两者之间的耦合。