检查点是flink处理分布式任务中故障的重要机制,通过周期性保存任务状态,可以实现在个别任务发生故障时恢复程序的功能。
flink检查点算法中用到了一种名为检查点分隔符的特殊标记,和水位线相似,这些检查点分隔符会通过数据源算子注入到数据流中,每个检查点分隔符都会带有一个编号,这样就把一个数据流从逻辑上分为两个部分,所有先于检查点分隔符的记录引起的状态都会包含在分隔符所对应的检查点之中,之后的数据引起的状态变更会记录在下一个检查点中。
具体流程是:
1.jobmanager周期性向每个数据源任务发送一个新的检查点编号,以此启动检查点生成流程
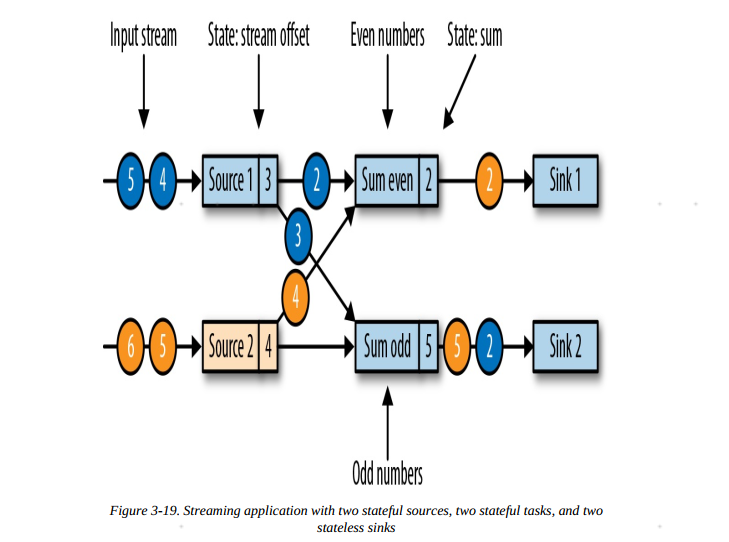
2.数据源任务收到消息后,暂停发出记录,生成数据源本地的偏移量状态offset,并生成一个检查点分隔符广播至所有下游任务

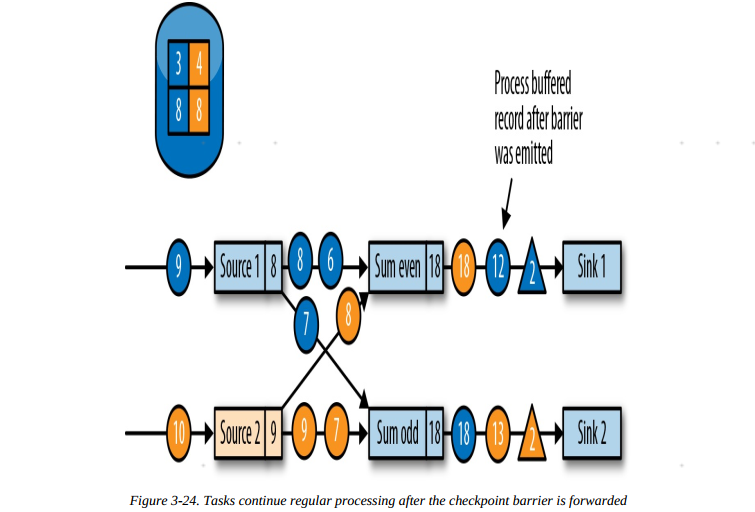
3.当一个任务收到检查点分隔符时,会等待所有上游链路的同一个分隔符,已经收到分隔符的链路的数据会缓存
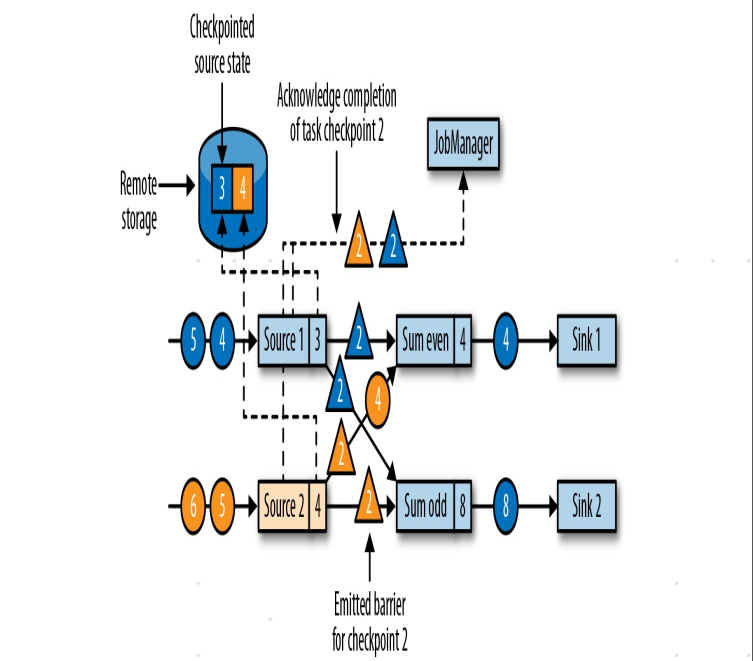
4.任务收到所有上游链路检查点分隔符后,生成当前状态的检查点,同时把检查点分隔符向下游任务传递
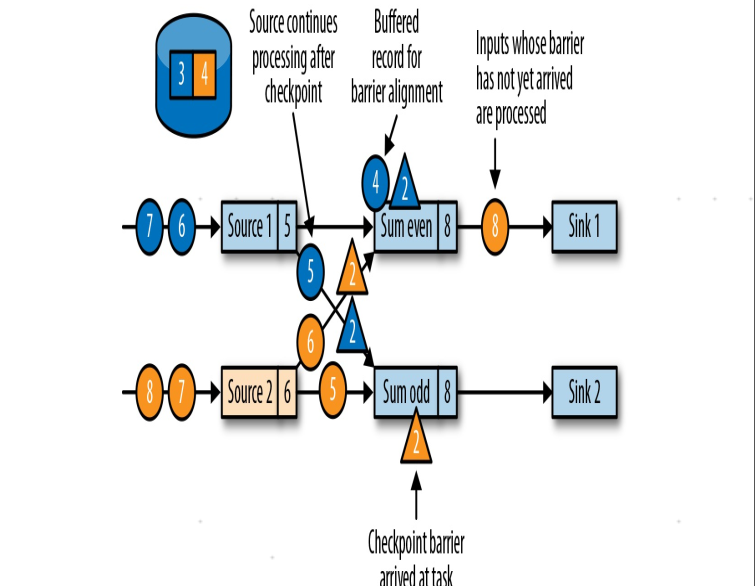
5.下游任务进行同样的操作,最终分隔符到底数据汇任务,数据汇任务执行分隔符对齐,将自身状态写入检查点
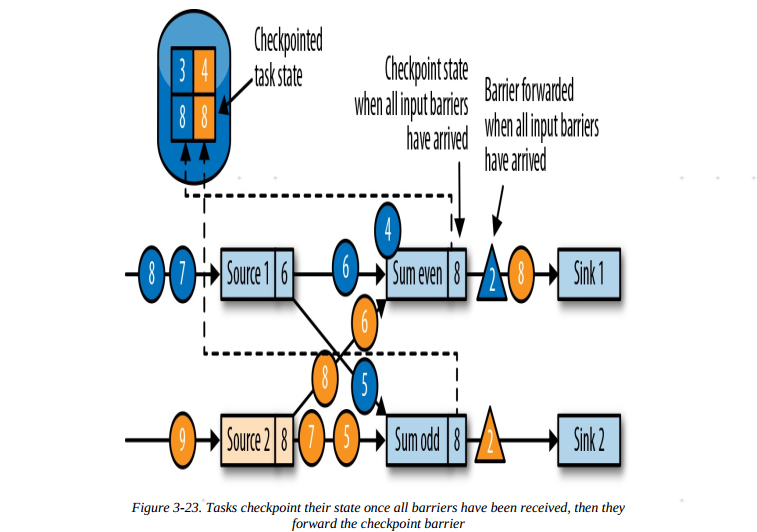
6.当所有任务的检查点都生成之后,jobmanager将此次检查点任务标记为完成。
7.应用在故障时就可以通过这个检查点进行恢复。

二、检查点与保存点
(一)原理相同:savepoint是通过checkpoint机制创建的,所以savepoint本质上是特殊的checkpoint。
(二)目的不同:checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从早先打下的checkpoint恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。
(三)维护不同:checkpoint面向Flink Runtime本身,由Flink的各个JobManager定时触发快照并自动清理,flink自己维护;savepoint面向用户,命令行触发或者web控制台触发,完全根据用户的需要触发与清理。