每个文件都有一个与之关联的用户 ID( UID)和组 ID( GID),籍此可以判定文件的属主和属组。
15.3.1 新建文件的属主
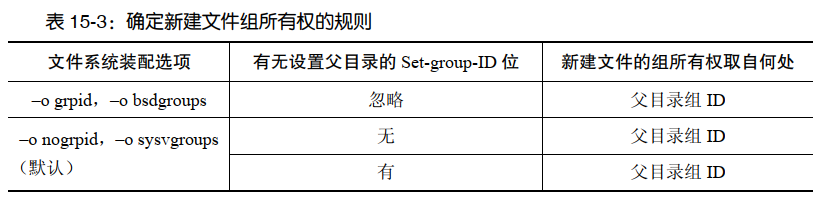
文件创建时,其用户 ID“取自”进程的有效用户 ID。而新建文件的组 ID 则“取自”进程的有效组 ID(等同于 System V 系统的默认行为),或父目录的组 ID( BSD 系统的行为)。 当为项目创建目录时,需要该目录下的所有文件隶属于某一特定组,并且可为该组所有成员所访问。这时,采用后一种行为就非常实用。新建文件的组 ID 在这两者间如何取舍是由多种因素决定的,新文件所在文件系统的类型就是其中之一。这里先介绍一下 ext2 和某些其他类型文件系统所遵循的规则。 为求精确,本节所使用的术语有效用户 ID 或组 ID,实际是指文件系统用户 ID 或组 ID 装配 ext2 文件系统时, mount 命令要么带有-o grpid 的选项(或等效的-o bsdgroups 选项),要么带有-o nogrpid 选项(或等效的-o sysvgroups 选项)。(若两者均未指定, mount 命令的默认选项为-o nogrpid。 )若指定了-o grpid 选项,那么新建文件总是继承其父目录的组 ID。
若指定了-o nogrpid 选项,那么在默认情况下,新建文件的组 ID 则“取自”进程的有效组 ID。不过,如果已将目录的 set-group-ID 位置位(通过 chmod g+s 命令),那么文件的组 ID 又将从其父目录处继承。表 15-3 对上述规则做了总结
15.3.2 改变文件属主: chown()、 fchown()和 lchown()
系统调用 chown()、 lchown()和 fchown()可用来改变文件的属主(用户 ID)和属组(组ID)。
include<sys/unistd.h> int chown(const char *pathname,uid_t owner,gid_t group); int lchown(const char *pathname,uid_t owner,gid_t group); int fchown(int fd,uid_t owner,gid_t group);
以上 3 个系统调用之间的区别类似于 stat()系统调用一族。 chown()改变由 pathname 参数命名文件的所有权。 lchown()用途与 chown()相同,不同之处在于若参数 pathname 为一符号链接,则将会改变链接文件本身的所有权,而与该链接所指代的文件无干。 fchown()也会改变文件的所有权,只是文件由打开文件描述符 fd 所引用。 参数 owner 和 group 分别为文件指定新的用户 ID 和组 ID。若只打算改变其中之一,只需将另一参数置为-1,即可令与之相关的 ID 保持不变。 Linux2.2 之前, chown()不对符号链接进行解引用。从 Linux 2.2 开始, chown()的语义发生了变化,并且添加了新系统调用 lchown(),以提供老系统调用 chown()的行为。 只有特权级进程(CAP_CHOWN)才能使用 chown()改变文件的用户 ID。 非特权级进程可使用 chown()将自己所拥有文件的组 ID 改为其所从属的任一属组的 ID,前提是进程的有效用户ID 与文件的用户 ID 相匹配。特权级进程则可将文件的组 ID 修改为任意值。
如果文件组的属主或属组发生了改变, 那么 set-user-ID 和 set-group-ID 权限位也会随之关闭。这一安全举措是为了防止如下行为:普通用户若能打开某一可执行文件的 set-user-ID(或 set-group-ID)位,然后再设法令其为某些特权级用户(或组)所拥有,就能在执行该文件时获得特权用户身份。 改变文件的属主和属组时,如果已然屏蔽了属组的可执行权限位,或者要改变的是目录的所有权时,那么将不会屏蔽 set-group-ID 权限位。在上述两种情况下, set-group-ID 位的用途并非是去创建一个启用了 set-group-ID 的程序,因此将该位屏蔽并不可取。 set-group-ID 的其他用途如下所示。 若屏蔽了属组的可执行权限位, 则可利用 set-group-ID 权限位来启用强制文件锁定。 当作用于目录时,可利用 set-group-ID 位来控制在该目录下创建文件的所有权。
程序清单 15-2 演示了 chown()的用法, 该程序允许用户改变任意数量文件(由命令行参数指定)的属主和属组。 (该程序使用程序清单 8-1 中的 userIdFromName()和 groupIdFromName()函数,将用户名和组名转换为相应的数字 ID。 )
15.4 文件权限
本节将介绍应用于文件和目录的权限方案。尽管此处所讨论的权限主要是针对普通文件和目录,但其规则可适用于所有文件类型,包括设备文件、 FIFO 以及 UNIX 域套接字等。此外, System V 和 POSIX 进程间通信对象(共享内存、信号量和消息队列)也具有权限掩码,而适用于此类对象的权限规则也与文件的权限规则相类似。
15.4.1 普通文件的权限
如 15.1 节所述, stat 结构中 st_mod 字段的低 12 位定义了文件权限。其中的前 3 位为专用位,分别是 set-user-ID 位、 set-group-ID 位和 sticky 位(在图 15-1 中分别被标注为 U、 G、 T位),将在 15.4.5 节中详细介绍。其余 9 位则构成了定义权限的掩码,分别授予访问文件的各类用户。文件权限掩码分为 3 类。 Owner(亦称为 user):授予文件属主的权限。chmod(1)之类的命令使用术语 user 的缩写 u 来指代该类权限。 Group:授予文件属组成员用户的权限。 Other:授予其他用户的权限。 可为每一类用户授予的权限如下所示。 Read:可阅读文件的内容。 Write:可更改文件的内容。 Execute:可以执行文件(亦即,文件是程序或脚本)。要执行脚本文件需同时具备读权限和执行权限。 执行 ls–l 命令,可查看文件的权限和所有权,如下所示
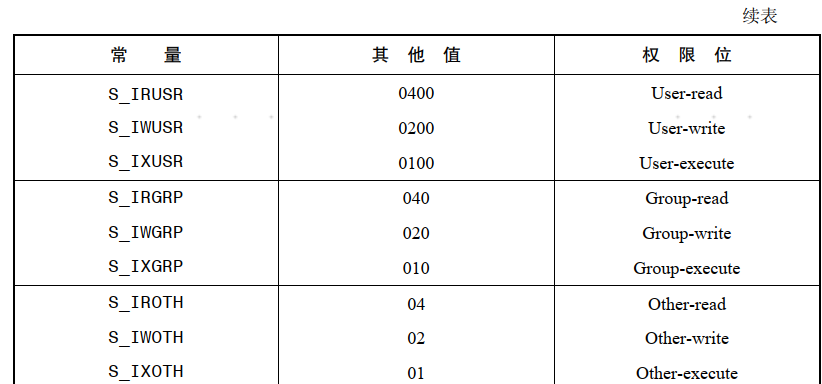
头文件<sys/stat.h>定义了可与 stat 结构中 st_mode 相与( &)的常量,用于检查特定权限位置位与否。 ( <fcntl.h>为 open()系统调用提供了原型,在程序中包含该头文件也可定义这些常量。 )表 15-4 列出了这些常量

程序清单 15-3 声明的函数 filePermStr(), 会针对给定的文件权限掩码返回一个静态分配的字符串,以 ls(1)所采用的风格来表示该掩码。
15.4.2 目录权限
目录与文件拥有相同的权限方案,只是对 3 种权限的含义另有所指。
读权限:可列出(比如,通过 ls 命令)目录之下的内容(即目录下的文件名)。在实验验证对目录读权限位的操作时,应当了解有些 Linux 发行版对 ls 做了别名处理,命令所携带的一些选项(比如, -F)需要访问目录中文件的 i 节点信息,而这又需要拥有对目录的执行权限。为确保使用的是 ls 命令本身,执行时要给出命令的完整路径名( /bin/ls)。
写权限:可在目录内创建、删除文件。注意,要删除文件,对文件本身无需有任何权限。
可执行权限:可访问目录中的文件。因此,有时也将对目录的执行权限称为 search(搜索)权限。 访问文件时, 需要拥有对路径名所列所有目录的执行权限。 例如, 想读取文件/home/mtk/x,则需拥有对目录/、 /home 以及/home/mtk 的执行权限(还要有对文件 x 自身的读权限)。若当前 的 工 作 目 录 为 /home/mtk/sub1 , 访 问 相 对 路 径 名 ../sub2/x 时 , 需 握 有 /home/mtk 和/home/mtk/sub2 这两个目录的可执行权限(不必有对/或/home 的执行权限)。 拥有对目录的读权限,用户只是能查看目录中的文件列表。要想访问目录内文件的内容或是这些文件的 i 节点信息,还需握有对目录的执行权限。 反之,若拥有对目录的可执行权限,而无读权限,只要知道目录内文件的名称,仍可对其进行访问,但不能列出目录下的内容(即目录所含的其他文件名)。在控制对公共目录内容的访问时,这是一种常用技术,简单而且实用。 要想在目录中添加或删除文件,需要同时拥有对该目录的执行和写权限。
15.4.3 权限检查算法
只要在访问文件或目录的系统调用中指定了路径名称,内核就会检查相应文件的权限。 如果赋予系统调用的路径名还包含目录前缀时,那么内核除去会检查对文件本身所需的权限以外,还会检查前缀所含每个目录的可执行权限。
内核会使用进程的有效用户 ID、有效组 ID以及辅助组 ID,来执行权限检查。 (准确说来, Linux 内核会使用文件系统用户 ID 和组 ID,而非相应的有效用户 ID 和组 ID,来进行文件权限检查,这一点 9.5 节已经提及。 )
一旦调用 open()打开了文件,针对返回描述符的后续系统调用(比如, read()、 write()、fstat()、 fcntl(),以及 mmap())将不再进行任何权限检查。 检查文件权限时,内核所遵循的规则如下。 1. 对于特权级进程,授予其所有访问权限。 2. 若进程的有效用户 ID 与文件的用户 ID(属主)相同,内核会根据文件的属主权限,授予进程相应的访问权限。比方说,若文件权限掩码中的属主读权限( owner-read permission)位被置位,则授予进程读权限。否则,则拒绝进程对文件的读取操作。 3. 若进程的有效组 ID 或任一附属组 ID 与文件的组 ID(属组)相匹配,内核会根据文件的属组权限,授予进程对文件的相应访问权限。 4. 若以上三点皆不满足,内核会根据文件的 other(其他)权限,授予进程相应权限。 其实,内核代码在实现上述检查规则时,在构造上也颇具匠心。只有当进程通过其他测试未能获得所需要的权限时,才去检查进程是否属于特权级进程。这就省去了对 ASU 进程记账标志的设置,该标志用于标记进程是否曾利用过超级用户特权(见 28.1 节)。 内核会依次执行针对属主、属组以及其他用户的权限检查,只要匹配上述检查规则之一,便会停止检查。这样得出的结果可能会在意料之外,比方说,若组权限超过了属主权限,那么文件属主所拥有的权限要低于组成员的权限,如下例所示
若为文件的其他用户分配的权限大于文件属主或属组,上述论述也同样适用。 由于文件的权限及所有权信息都维护于文件的 i 节点之内,故而也为指向同一 i 节点的所有文件名(链接)所共享。 Linux2.6 支持访问控制列表,从而可以以每用户或每组为基础来定义文件权限。 若文件与一 ACL 挂钩,内核则会在上述算法的基础上略作改动。
检查特权级别进程的权限
上文曾提及,若进程为特权级进程,则内核在检查权限时将授予进程所有的访问权限。这一论述成立,其实还要加个限制条件。对于非目录文件,仅当该文件的 3 种权限类型(至少)之一具有可执行权限时, Linux 才会将该权限赋予一特权级进程。
而在其他一些 UNIX 的实行中,即使文件的任何权限类型都不具有可执行权限,特权级进程还是能执行该文件。而 当访问目录时,特权级进程总是拥有可执行(搜索)权限。
15.4.4 检查对文件的访问权限: access()
如上节所述,当进程访问文件时,系统会以其 effective(有效)用户 ID、 effective(有效)组ID 以及附属组 ID 来确定权限。当然,对于程序(比如, set-user-ID 或 set-group-ID 程序)来说,根据进程的 real(真实)用户 ID 和组 ID 来检查对文件的访问权限,也并非没有可能。 系统调用 access()就是根据进程的真实用户 ID 和组 ID(以及附属组 ID),去检查对pathname 参数所指定文件的访问权限。 若 pathname 为符号链接, access()将对其解引用。 参数 mode 是由表 15-5 中常量相或( |)而成的位掩码。若由 pathname 所指定的文件具备mode 参数包含的所有权限, access()将返回 0; 只要有一项权限未得到满足(或者有错误发生),access()则返回-1。
由于对某一文件调用 access()与对同一文件的后续操作之间存在时间差,因此(不论间隔多么短暂)执行后续操作时,也无法保证在对文件的后续操作时由 access()所返回的信息依然正确。在某些应用程序设计中,上述情形可能会导致安全漏洞。 比方说,假设有一 set-user-ID-root 程序,使用 access()来检查程序的真实用户 id 是否可以访问某文件,如果可以访问,就对其执行( open()或 exec()之类的)操作。 问题是,若输入 access()的路径名为符号链接,而恶意用户可抢在第二步检查之前设法更改该链接,使其指向另一文件,则最终会导致 set-user-ID-root 去操作真实用户 ID 并无权限的文件。
正因如此,建议杜绝使用 access()。对于前文所举示例,可以暂时更改 set-user-ID 进程的 有效(或文件系统)用户 ID 来实施( open()或 exec()之类的)文件操作,并通过对返回值和errno 的检查来判断,操作失败是否应归咎于权限问题。 GNU C 库提供了一个功能相似的非标准函数 euidaccess()(及其同义函数 eaccess()),该函数使用进程的有效用户 ID 来检查对文件的访问权限。
15.4.5 Set-User-ID、 Set-Group-ID 和 Sticky 位
除了 9 位用来表明属主、属组和其他用户的权限之外,文件权限掩码还另设有 3 个附加位,分别为 set-user-ID (bit 04000)、 set-group-ID (bit 02000)和 sticky (bit 01000)位。
9.3 节讨论了创建特权级程序时对 set-user-ID 和 set-group-ID 权限位的使用。 set-group-ID 位还有两种其他用途:对于在以 nogrpid 选项装配的目录下所新建的文件,控制其群组从属关系;可用于强制锁定文件。以上两种用途分别在 15.3.1 节和 55.4 节有所介绍。本节将重点讨论 sticky 位的用途。 在老的 UNIX 实现中,提供 sticky 位的目的在于让常用程序的运行速度更快。若对某程序文件设置了 sticky 位,则首次执行程序时,系统会将其文本1拷贝保存于交换区中,即“粘”( stick)在交换区内,故而能提高后续执行的加载速度。
现代 UNIX 实现对内存的管理更为精准,故而也将权限位的这一用法束之高阁 在现代 UNIX 实现(包括 Linux)中, sticky 权限位所起的作用全然不同于老的 UNIX 实现。作用于目录时, sticky 权限位起限制删除位的作用。
为目录设置该位,则表明仅当非特权进程具有对目录的写权限, 且为文件或目录的属主时, 才能对目录下的文件进行删除( unlink()、rmdir())和重命名( rename())操作。(具有 CAP_FOWNER 能力的进程可省去对属主的检查。 ) 可藉此机制来创建为多个用户共享的一个目录,各个用户可在其下创建或删除属于自己的文件,但不能删除隶属于其他用户的文件。为/tmp 目录设置 sticky 权限位,原因正在于此。 可通过 chmod 命令(chmod +t file)或 chmod()系统调用来设置文件的 sticky 权限位。若对某文件设置了 sticky 权限位,则当执行 ls–l 命令显示该文件时,会在其他用户执行权限字段上看到字母 T,其大小写则要取决于是否对文件开启了其他用户执行权限位,如下所示:
chmod +t tfile
ls -l tfile
15.4.6 进程的文件模式创建掩码: umask()
本节将针对新建文件或目录的权限设置展开深入讨论。对于新建文件,内核会使用 open()或 creat()中 mode 参数所指定的权限。对于新建目录,则会根据 mkdir()的 mode 参数来设置权 限。然而,文件模式创建掩码(简称为 umask)会对这些设置进行修改。
umask 是一种进程属性,当进程新建文件或目录时,该属性用于指明应屏蔽哪些权限位。 进程的 umask 通常继承自其父 shell,其结果往往正如人们所期望的那样:用户可以使用shell 的内置命令 umask 来改变 shell 进程的 umask,从而控制在 shell 下运行程序的 umask。 大多数 shell 的初始化文件会将 umask 默认置为八进制值 022 (----w--w-)。其含义为对于同组或其他用户,应总是屏蔽写权限。因此,假定 open()调用中的 mode 参数为 0666(即令所有用户享有读、写权限,通常如此),那么对新建文件来说,其属主拥有读、写权限,所有其他用户只具有读权限(针对文件执行 ls–l 命令,会显示“ rw-r--r—”)。
同理,假定将 mkdir()的 mode 参数指定为 0777(即所有用户享有所有权限),那么对于新建目录来说,其属主享有所有权限,同组和其他用户则只拥有读取和执行权限(即 rwxr-xr-x)。 系统调用 umask()将进程的 umask 改变为 mask 参数所指定的值 可以以八进制数或是表 15-4 中所列常量相或( |)来指定 mask 参数。
对 umask()的调用总会成功,并返回进程的前一 umask。 程序清单 15-5 演示了 umask()与 open()和 mkdir()的相互配合。运行该程序的结果如下
15.4.7 更改文件权限: chmod()和 fchmod()
可利用系统调用 chmod()和 fchmod()去修改文件权限
系统调用 chmod()更改由 pathname 参数所指定文件的权限。若该参数所指为符号链接,调用 chmod()会改变符号链接所指代文件的访问权限,而非对符号链接自身的访问权限。 (符号链接自创建起,其所有权限便为所有用户共享,且这些权限也不得更改。对符号链接解引用时,将忽略所有这些权限。 ) 系统调用 fchmod()更改由打开文件描述符 fd 所指代文件的权限。参数 mode 用于描述文件的新权限,可以采用八进制数字形式,亦或是由表 15-4 所列权限位相或( |)而成的掩码。
要想更改文件权限,进程要么具有特权级别( CAP_FOWNER), 要么其有效用户 ID 于文件的用户 ID(属主)相匹配。 (准确说来,对于 Linux 系统上的非特权级进程,需与文件用户 ID 相匹配的是进程的文件系统用户 ID,而非其有效用户 ID ) 要将文件权限设为使所有用户仅具有读权限,需执行如下系统调用:
if (chmod("file",S_IRUSER|S_IRGRP|S_IROTH)==-1)
errExit("chmod");
要修改文件的特定权限位,需先调用 stat()来获取文件的现有权限,调整想修改的权限位,然后使用 chmod()去更新权限
struct stat sb; mode_t mode; if(stat("myfile",&sb)==-1) errExit("stat"); mode=(sb.st_mode|S_IWUSR)& ~S_IROTH if (chmod("file",mode)==-1) errExit("chmod");
执行以上代码,等价于执行如下 shell 命令:
chmod u+w o-r myfile
15.3.1 节曾提及,若一目录驻留于以– o bsdgroups 选项装配的 ext2 文件系统之上,或是驻留于以– o sysvgroups 选项装配的 ext2 文件系统上,并且开启了该目录的 set-group-ID 权限位,那么在该目录下新建的文件会继承其父目录(而非文件创建进程的有效组 ID)的组所有权。
可能会出现这样一种情况,即文件的组 ID 与创建文件进程的任一组 ID 都不匹配。正因如此,当非特权级(不具备 CAP_FSETID 能力的)进程调用 chmod() (或 fchmod())时,若文件的组 ID 不等于进程的有效组 ID 或是任一辅助组 ID,内核则总是清除文件的 set-group-ID 权限位。这一安全举措意在防止用户为其不隶属的组创建 set-group-ID 程序。以下 shell 命令演 示了上述安全措施所堵住的安全漏洞。
15.5 i节点标志
某些 Linux 文件系统允许为文件和目录设置各种各样的 i-node flags(I 节点标志)。该特性是一种非标准的 Linux 扩展功能。
ext2 是首个支持 i 节点标志的 Linux 文件系统,有时人们也将这些标志称为 ext2 扩展文件属性。随后,其他文件系统,诸如 Btrfs、 ext3、 ext4、 Reiserfs(自 Linux 2.4.19 起)、 XFS以及 JFS(自 Linux 2.6.17 起),也纷纷加入对 i 节点标志的支持
在 shell 中,可通过执行 chattr 和 lsattr 命令来设置和查看 i 节点标志,如下例所示:
在程序中,可利用 ioctl()系统调用来获取并修改 i 节点标志,本节稍后会加以详述。 对普通文件或目录均可设置 i 节点标志。大多数 i 节点标志是供普通文件使用的,也有少部分兼供(或专供)目录使用。表 15-6 对于所支持的 i 节点标志作了总结,展示了程序调用ioctl()时所使用的相应标志名称(定义于<linux/fs.h>中), 以及配合 chattr 命令使用的选项字母
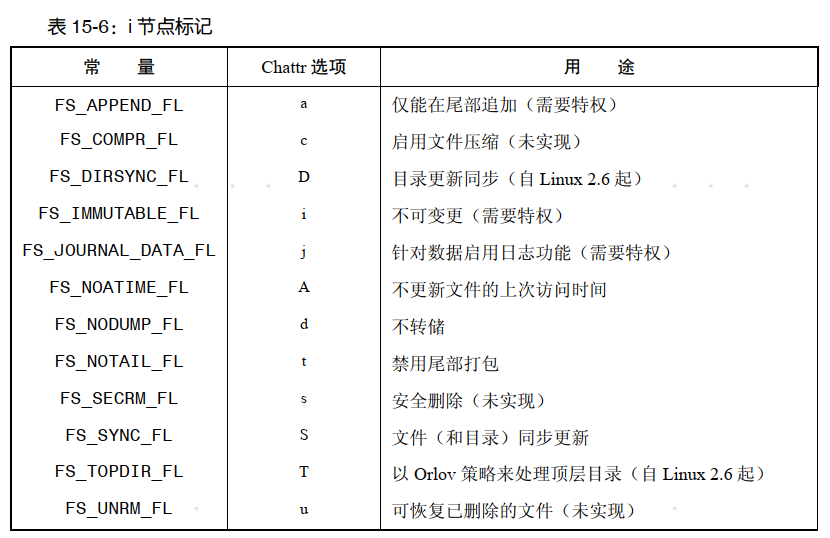
FL 系列变量及其含义如下所示
FS_APPEND_FL 仅当指定 O_APPEND 标志时,方能打开文件并写入。 例 如 , 可 以 用 该 标 志 来 写 入 日 志 文 件 。 只 有 特 权 级 进 程 ( 具 备CAP_LINUX_IMMUTABLE 能力)方可设置该标志。
FS_COMPR_FL 文件内容经压缩后存储于磁盘之上。在主流的纯 Linux 文件系统上, FS_COMPR_FL 不属于标配特性。
FS_DIRSYNC_FL(自 Linux 2.6 以后) 使得对目录的更新(例如: open(pathname, O_CREAT)、 link()、 unlink()、 mkdir())同步发生。这类似于 13.3 节所述的文件同步更新机制。同样,目录同步更新也存在性能问题。这一设置可以只应用于目录。
FS_IMMUTABLE_FL 将文件设置为不可更改,既不能更新文件数据( write()和 truncate()),也不能改变文件元数据(即 chmod()、 chown()、 unlink()、 link()、 rename()、 rmdir()、 utime()、 setxattr() 和 removexattr())只有特权级进程(具备 CAP_LINUX_IMMUTABLE 能力的进程)可为文件设置这一标志。该标志一旦设定,即便是特权级进程也无法改变文件的内容或元数据。
FS_JOURNAL_DATA_FL 对数据启用日志功能。只有 ext3 和 ext4 文件系统才支持该标志。这些文件系统提供 3 种层次的日志记录: journal(日志)、 ordered(排序),以及 writeback(回写)。所有模式都会记录对文件元数据的更新,而 journal(日志)模式额外还记录了对文件数据的变更。而在以排序或回写模式运行日志功能的文件系统上,特权级(具有 CAP_SYS_RESOURCE 能力的)进程可以为单个文件设置此标志,从而启用对该文件数据更新的日志功能。
FS_NOATIME_FL 访问文件时不更新文件的上次访问时间。这省去了每次访问文件时对 I 节点的更新,故而改进了 I/O 性能。
FS_NODUMP_FL 在使用 dump(8)备份系统时跳过具有此标志的文件。正如 dump(8)手册页所载,该标志有效与否取决于此命令的-h 选项。
FS_NOTAIL_FL 禁用尾部打包。只有 Reiserfs 文件系统才支持该标志。此标志屏蔽了 Reiserfs 的尾部打包特性,即尝试将小文件(或是较大文件的最后一段)与其元数据置于同一磁盘块中装配 Reiserfs 文件系统时, mount 如带有–o notail 选项将对整个文件系统禁用尾部打包。
FS_SECRM_FL 安全删除文件。该特性尚未实现,其用意在于删除文件时能够万无一失,将被删除文件的数据覆盖掉,以免磁盘扫描程序能够读取并重建该文件。
FS_SYNC_FL 令对文件的更新保持同步。当应用于文件时,该标志将致使对文件的写入操作同步完成(就好像对该文件执行的所有 open()调用都引用了 O_SYNC 标志一样)。当应用于目录时,该标志的作用等同于前述的同步目录更新标志。
FS_TOPDIR_FL(自 Linux 2.6 起) 这标志着将在 Orlov 块分配策略的指导下对某一目录进行特殊处理。 Orlov 策略的灵感来自于 BSD 系统,是对 ext2 文件系统块分配策略的一种改良,试图增大相关文件(例如:同一目录下的各个文件)在磁盘中比邻而居的几率,进而缩短磁盘的寻道时间
FS_UNRM_FL 允许该文件在遭删除后能得以恢复。由于可在内核之外实现文件的恢复机制,因此该特性尚未实现。
一般而言,如果针对某一目录设置了 i 节点标志,那么新建于其下的文件和子目录会自动将其继承。不过也有例外。
FS_DIRSYNC_FL (chattr +D)标志只能应用于目录,故而也只能为新建于该目录下的子目录所继承。 当将 FS_IMMUTABLE_FL (chattr +i)标志应用于目录时,不会有创建于该目录下的文件或子目录继承此标志,因为该标志会阻止在此目录中添加任何新的条目。 在程序中可以分别调用 ioctl()的 FS_IOC_GETFLAGS 和 FS_IOC_SETFLAGS 操作,来获取和修改 i 节点标志(这两个常量定义于<linux/fs.h>)。
以下代码演示了如何为打开文件描述符 fd 所指代的文件设置 FS_NOATIME_FL 标志。 想改变文件的 i 节点标志,至少要满足下列两种条件之一:
其一,进程的有效用户 ID 需匹配文件的用户 ID(属主);
其二,进程享有特权级别(具备 CAP_FOWNER 能力)。
严格说来, 对于 Linux 上运行的非特权进程,与文件的用户 ID 相匹配的是其文件系统用户 ID,而非有效用户 ID(详见 9.5 节