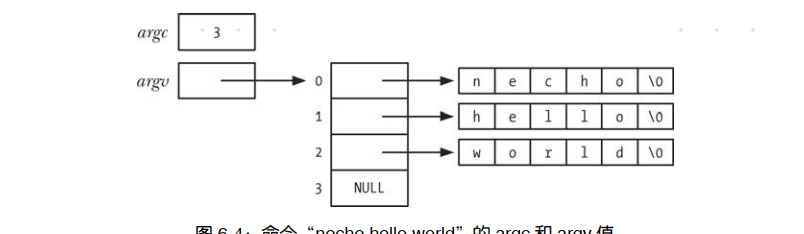
每个 C 语言程序都必须有一个称为 main()的函数,作为程序启动的起点。当执行程序时,命令行参数通过两个入参提供给 main()函数。 第一个参数 int argc,表示命令行参数的个数。第二个参数 char *argv[],是一个指向命令行参数的指针数组,每一参数又都是以空字符(null) 结尾的字符串。第一个字符串是该程序的名称。 argv 中的指针列表以 NULL 指针结尾。 argv[0]包含了调用程序的名称,可以利用这一特性玩个实用的小技巧。首先为同一程序创建多个链接(即名称不同),然后让该程序查看 argv[0],并根据调用程序的名称来执行不同任务。 gzip(1)、 gunzip(1)和 zcat(1)命令是该技术应用的一个例子,这些命令链接的都是同一可执行文件。 图 6-4 展示了执行程序清单 6-2 中程序所传入参 argc 和 argv 的数据结构。该图使用 C 语言符号“ �”来表示每个字符串末尾的终止空字节。
程序清单 6-2 中的程序回显了其命令行参数,逐一按行输出,前面还冠以要显示的 argv成员名称
因为 argv 列表以 NULL 值终止,所以可以将程序清单 6-2 中的程序主体改写如下,且每行只输出一个命令行实参:
char **p;
for(p=argv;*p!=NULL;p++){
puts(*p)
}
argc/argv 参数机制的局限之一在于这些变量仅对 main()函数可用。在保证可移植性的同时,为使这些命令行参数能为其他函数所用,必须把 argv 以参数形式传递给这些函数,或是设置一个指向 argv 的全局变量。 要想从程序内任一位置访问这些信息的部分或者全部内容,还有两个方法,但是会破坏程序的可移植性。 1.通过 linux 系统专有的/proc/PID/cmdline 文件可以读取任一进程的命令行参数,每个参数都以空(null)字节终止。(程序可以通过/proc/self/cmdline 文件访问自己的命令行参数。) 2.GNU C 语言库提供有两个全局变量, 可在程序内任一位置使用以获取调用该程序时的程序名称(即命令行的第一个参数)。第一个全局变量 program_invocation_ name,提供了用于调用该程序的完整路径名。第二个全局变量 program_invocation_ short_name,提供了不含目录的程序名称, 即路径名的基本名称(basename)部分, 定义_GNU_SOURCE 宏后即可从<errno.h>中获得对这两个全局变量的声明。 正如图 6-1 所示, argv 和 environ 数组,以及这些参数最初指向的字符串,都驻留在进程栈之上的一个单一、连续的内存区域。
许多程序使用 getopt()库函数解析命令行选项(即以“ -”符号开头的参数)。
6.7 环境列表
每一个进程都有与其相关的称之为环境列表(environment list)的字符串数组。其中每个字符串都以名称=值(name=value)形式定义。因此,环境是“名称-值”的成对集合,可存储任何信息。常将列表中的名称称为环境变量。
新进程在创建之时,会继承其父进程的环境副本。这是一种原始的进程间通信方式,却颇为常用。环境变量提供了将信息从父进程传递给子进程的方法。由于子进程只有在创建时才能获得其父进程的环境副本,所以这一信息传递是单向的、一次性的。
子进程创建后,父、子进程均可更改各自的环境变量,且这些变更对对方而言不再可见。环境变量的常见用途之一是在 shell 中。通过在自身环境中放置变量值, shell 就可确保把这些值传递给其所创建的进程, 并以此来执行用户命令。 例如, 环境变量 SHELL 被设置为 shell程序本身的路径名,如果程序需要执行 shell 时,大多会将此变量视为需要执行的 shell 名称。
可以通过设置环境变量来改变一些库函数的行为。正因如此,用户无需修改程序代码或者重新链接相关库,就能控制调用该函数的应用程序行为。 getopt()函数就是其中一例,可通过设置 POSIXLY_CORRECT 环境变量来改变此函数的行为。
大多数 shell 使用 export 命令向环境中添加变量值
在 bash shell 和 Korn shell 中,可以简写为:
export SHELL=/bin/bash
在 C shell 中,使用的则是 setenv 命令:
setenv SHELL /bin/bash
上述命令把一个值永久地添加到 shell 环境中,此后这个 shell 创建的所有子进程都将继承此 环境。在任一时刻,可以使用 unset 命令撤销一个环境变量(在 C shell 中则使用 unsetenv 命令)。 在 Bourne shell 和其衍生 shell(诸如 bash shell 和 Korn shell)中,可使用下列语法向执行 某应用程序的环境中添加一个变量值,而不影响其父 shell(和后续命令):
NAME=value program
此命令仅向执行特定程序的子进程环境添加了一个(环境变量)定义。如果希望(多个变量对该程序有效),可以在 program 前放置多对赋值(以空格分隔)
printenv 命令显示当前的环境列表
由以上输出可知,环境列表的排列是无序的,列表中的字符串顺序不过是最易于实现的排列形式。一般而言,无序的环境列表不是问题,因为通常都是访问单个的环境变量,而非环境列表中按序排列的一串。 通过 Linux 专有的/proc/PID/environ 文件检查任一进程的环境列表, 每一个“ NAME=value”对都以空字节终止。
从程序中访问环境
在 C 语言程序中,可以使用全局变量 char **environ 访问环境列表。 ( C 运行时启动代码定义了该变量并以环境列表位置为其赋值。 ) environ 与 argv 参数类似,指向一个以 NULL 结尾的指针列表,每个指针又指向一个以空字节终止的字符串。图 6-5 所示为与上述 printenv 命令输出环境相对应的环境列表数据结构

程序清单 6-3 中的程序通过访问 environ 变量来展示该进程环境中的所有值。该程序的输出结果与 printenv 命令的输出结果相同。程序中的循环利用指针来遍历 environ 变量。虽然可以把 environ 当成数组来使用(正如程序清单 6-2 中 argv 的用法),但这多少有些生硬,因为环境列表中各项的排列不分先后,而且也没有变量(相当于 argc)用来指定环境列表的长度。
另外,还可以通过声明 main()函数中的第三个参数来访问环境列表:
int main(int argc,char *argv[],char *envp[])
该参数随即可被视为 environ 变量来使用, 所不同的是, 该参数的作用域在 main()函数内。虽然 UNIX 系统普遍实现了这一特性,但还是要避免使用,因为除了局限于作用域限制外,该特性也不在 SUSv3 的规范之列。 getenv()函数能够从进程环境中检索单个值。
向 getenv()函数提供环境变量名称,该函数将返回相应字符串指针。因此,就前面所示的环境(列表)示例来看,如果指定 SHELL 为参数 name,那么将返回/bin/bash。如果不存在指定名称的环境变量,那么 getenv()函数将返回 NULL。 以下是使用 getenv()函数时可移植性方面的注意事项。 1.应用程序不应修改 getenv()函数返回的字符串, 这是由于该字符串实际上属于环境的一部分(即 name=value 字符串的 value 部分)。若需要改变一个环境变量的值,可以使用 setenv()函数或 putenv()函数。 2.SUSv3 允许 getenv()函数的实现使用静态分配的缓冲区返回执行结果,后续对 getenv()、setenv()、 putenv()或者 unsetenv()的函数调用可以重写该缓冲区。虽然 glibc 库的 getenv()函数实现并未这样使用静态缓冲区,但具备可移植性的程序如需保留 getenv()调用返回的字符串,就应先将返回字符串复制到其他位置,之后方可对上述函数发起调用
修改环境
有时,对进程来说,修改其环境变量很有用处。原因之一是这一修改对该进程后续创建的所有子进程均可见。 另一个可能的原因在于设定某一变量, 以求对于将要载入进程内存的新程序(“execed”)可见。从这个意义上讲,环境不仅是一种进程间通信的形式,还是程序间通信的方法。
putenv()函数向调用进程的环境中添加一个新变量,或者修改一个已经存在的变量值。 参数 string 是一指针,指向 name=value 形式的字符串。调用 putenv()函数后,该字符串就成为环境的一部分,换言之, putenv 函数将设定 environ 变量中某一元素的指向与 string 参数的指向位置相同,而非 string 参数所指向字符串的复制副本。
因此,如果随后修改 string 参数所指的内容,这将影响该进程的环境。出于这一原因, string 参数不应为局部变量,因为定义此变量的函数一旦返回,就有可能会重写这块内存区域。
putenv()函数的 glibc 库实现还提供了一个非标准扩展。 如果 string 参数内容不包含一个等号( =),那么将从环境列表中移除以 string 参数命名的环境变量。
setenv()函数可以代替 putenv()函数,向环境中添加一个变量。 setenv()函数为形如 name=value 的字符串分配一块内存缓冲区,并将 name 和 value 所指向的字符串复制到此缓冲区,以此来创建一个新的环境变量。注意,不需要在 name 的结尾处或者 value 的开始处提供一个等号字符,因为 setenv()函数会在向环境添加新变量时添加等号字符。 若以 name 标识的变量在环境中已经存在,且参数 overwrite 的值为 0,则 setenv()函数将不改变环境,如果参数 overwrite 的值为非 0,则 setenv()函数总是改变环境。 这一事实—setenv()函数复制其参数(到环境中) —意味着与 putenv()函数不同,之后对 name 和 value 所指字符串内容的修改将不会影响环境。此外,使用自动变量作为 setenv()函数的参数也不会有任何问题。 unsetenv()函数从环境中移除由 name 参数标识的变量
同 setenv()函数一样,参数 name 不应包含等号字符。 setenv()函数和 unsetenv()函数均来自 BSD,不如 putenv()函数使用普遍。尽管起初的POSIX.1 标准和 SUSv2 并未定义这两个函数,但 SUSv3 已将其纳入规范。
有时, 需要清除整个环境, 然后以所选值进行重建。 例如, 为了以安全方式执行 set-user-ID程序( 38.8 节),就需要这样做。可以通过将 environ 变量赋值为 NULL 来清除环境。这也正是 clearenv()库函数的工作内容。
在某些情况下,使用 setenv()函数和 clearenv()函数可能会导致程序内存泄露。前面已然提及: setenv()函数所分配的一块内存缓冲区,随之会成为进程环境的一部分。而调用 clearenv()时则没有释放该缓冲区
反复调用这两个函数的程序,会不断产生内存泄露。实际上,这不大可能成为一个问题,因为程序通常仅在启动时调用 clearenv()函数一次,用于移除继承自其父进程环境中的所有条目。
6.8 执行非局部跳转: setjmp()和 longjmp()
使用库函数 setjmp()和 longjmp()可执行非局部跳转。术语“非局部(nonlocal)”是指跳转的目标为当前执行函数之外的某个位置。 C 语言,像许多其他编程语言一样,包含goto语句。这就好比打开了潘多拉的魔盒。若无止境的滥用,将使程序难以阅读和维护。不过偶尔也能一显身手,令程序更简单、更快速,或是兼而有之。 C 语言的 goto 语句存在一个限制,即不能从当前函数跳转到另一函数。然而,偶尔还是需要这一功能的。考虑错误处理中经常出现的如下场景:在一个深度嵌套的函数调用中发生了错误,需要放弃当前任务,从多层函数调用中返回,并在较高层级的函数中继续执行(也许甚至是在 main()中)。要做到这一点,可以让每个函数都返回一个状态值,由函数的调用者检查并做相应处理。这一方法完全有效,而且,在许多情况下,是处理这类场景的理想方法。 然而,有时候如果能从嵌套函数调用中跳出,返回该函数的调用者之一编码会更为简单。 setjmp()和 longjmp()就提供了这一功能
setjmp()调用为后续由 longjmp()调用执行的跳转确立了跳转目标。该目标正是程序发起setjmp()调用的位置。从编程角度看来,调用 longjmp()函数后,看起来就和从第二次调用 setjmp()返回时完全一样。通过查看 setjmp()返回的整数值,可以区分 setjmp 调用是初始返回还是第二次“返回”。初始调用返回值为 0,后续“伪”返回的返回值为 longjmp()调用中 val 参数所指定的任意值。通过对 val 参数使用不同值,能够区分出程序中跳转至同一目标的不同起跳位置。 如果指定 longjmp()函数的 val 参数值为 0,而 longjmp 函数对此又不做检查,就会导致模拟 setjmp()时返回值为 0,如同初次调用 setjmp()函数返回时一样。出于这一原因,如果指定val 参数值为 0,则 longjmp()调用实际会将其替换为 1。 这两个函数的入参 env 为成功实现跳转提供了黏合剂。 setjmp()函数把当前进程环境的各种信息保存到 env 参数中。调用 longjmp()时必须指定相同的 env 变量,以此来执行“伪”返回。 由于对 setjmp()函数和 longjmp()函数的调用分别位于不同函数,所以应该将 env 参数定义为全局变量,或者将 env 作为函数入参来传递,后一种做法较为少见。 调用 setjmp()时, env 除了存储当前进程的其他信息外,还保存了程序计数寄存器(指向当前正在执行的机器语言指令)和栈指针寄存器(标记栈顶)的副本。这些信息能够使后续的 longjmp()调用完成两个关键步骤的操作。 1.将发起 longjmp()调用的函数与之前调用 setjmp()的函数之间的函数栈帧从栈上剥离。有时又将此过程称为“解开栈( unwinding the stack)”,这是通过将栈指针寄存器重置为 env 参数内的保存值来实现的。 2.重置程序计数寄存器,使程序得以从初始的 setjmp()调用位置继续执行。同样,此功能是通过 env 参数中的保存值(程序计数寄存器)来实现的
对 setjmp()函数的使用限制
SUSv3 和 C99 规定,对 setjmp()的调用只能在如下语境中使用。 1.构成选择或迭代语句中( if、 switch、 while 等)的整个控制表达式。
2.作为一元操作符!( not)的操作对象,其最终表达式构成了选择或迭代语句的整个控制表达式。
3.作为比较操作( ==、 !=、 <等)的一部分,另一操作对象必须是一个整数常量表达式,且其最终表达式构成选择或迭代语句的整个控制表达式。 4.作为独立的函数调用,且没有嵌入到更大的表达式之中。 注意: C 语言赋值语句不在上述列表之列。以下形式的语句是不符合标准的: 之所以规定这些限制, 是因为作为常规函数的 setjmp()实现无法保证拥有足够信息来保存所有寄存器值和封闭表达式中用到的临时栈位置, 以便于在 longjmp()调用后此类信息能得以正确恢复。因此,仅允许在足够简单且无需临时存储的表达式中调用 setjmp()。
滥用 longjmp()
如果将 env 缓冲区定义为全局变量,对所有函数可见(这也是通常用法),那么就可以执 行如下操作序列。 1. 调用函数 x(),使用 setjmp()调用在全局变量 env 中建立一个跳转目标。 2. 从函数 x()中返回。 3. 调用函数 y(),使用 env 变量调用 longjmp()函数。 这是一个严重错误,因为 longjmp()调用不能跳转到一个已经返回的函数中。思考一下,在这种情况下,longjmp()函数会对栈打什么主意—尝试将栈解开,恢复到一个不存在的栈帧位置,这无疑将引起混乱。如果幸运的话,程序会一死了之。然而,取决于栈的状态,也可能会引起调用与返回间的死循环,而程序好像真地从一个当前并未执行的函数中返回了。 (在多线程程序中有与之相类似的滥用,在线程某甲中调用 setjmp()函数,却在线程某乙中调用 longjmp()。 )
优化编译器的问题
优化编译器会重组程序的指令执行顺序,并在 CPU 寄存器中,而非 RAM 中存储某些变量。这种优化一般依赖于反映了程序词法结构的运行时( run-time)控制流程。由于 setjmp()和 longjmp()的跳转操作需在运行时才能得以确立和执行,并未在程序的词法结构中有所反映,故而编译器在进行优化时也无法将其考虑在内。此外,某些应用程序二进制接口( ABI)实现的语义要求 longjmp()函数恢复先前 setjmp()调用所保存的 CPU 寄存器副本。 这意味着 longjmp()操作会致使经过优化的变量被赋以错误值。程序清单 6-6 中的程序行为就是其中一例。
此处,在 longjmp()调用后, nvar 和 rvar 参数被重置为 setjmp()初次调用时的值。起因是优化器对代码的重组受到 longjmp()调用的干扰。作为候选优化对象的任一局部变量可能都难免会遇到这类问题,一般包含指针变量和 char、 int、 float、 long 等任何简单类型的变量。
将变量声明为 volatile,是告诉优化器不要对其进行优化,从而避免了代码重组。在上面的程序输出中,无论编译优化与否,声明为 volatile 的变量 vvar 都得到了正确处理。因为不同的优化器有着不同的优化方法,具备良好移植性的程序应在调用 setjmp()的函数中,将上述类型的所有局部变量都声明为 volatile。
尽可能避免使用 setjmp()函数和 longjmp()函数
如果说 goto 语句会使程序难以阅读,那么非局部跳转会让事情的糟糕程度增加一个数量级, 因为它能在程序中任意两个函数间传递控制。 因此, 应当慎用 setjmp()函数和 longjmp()函数。在设计和编码时花点心思来避免使用这两个函数,这通常是值得的。