转自:http://shanewfx.github.io/blog/2013/08/14/caprure-audio-on-windows/
前一段时间接到一个任务,需要采集到声卡的输出信号,以便与麦克风的输入信号进行混音。
对于上面3种方式,render和capture方式应该比较好理解, 也都是系统有API直接支持的方式, loopback方式就比较奇怪了,在XP上该方式系统实际都没有正式支持, loopback的录制方式实际上也涉及到CD的版权问题。
之前一直没有研究过音频的相关技术,这次就顺便抽出一点时间去了解了一下Windows上采集音频的相关技术。
对于音频处理的技术,主要有如下几种:
采集麦克风输入
采集声卡输出
将音频数据送入声卡进行播放
对多路音频输入进行混音处理
1.Windows上音频处理的API
在Windows操作系统上,常用的音频处理技术主要包括:
Wave系列API函数、
DirectSound、
Core Audio。
其中,Core Audio只可以在Vista以上(包括Vista)的操作系统中才能使用,主要用来取代Wave系列API函数和DirectSound。
Core Audio实现的功能也比较强大,能实现对麦克风的采集、声卡输出的采集、控制声音的播放。
而Wave系列的API函数主要是用来实现对麦克风输入的采集(使用WaveIn系列API函数)和控制声音的播放(使用后WaveOut系列函数)。
DirectSound能够实现的功能估计和Wave系列API差不多,可能会更强一些(由于没有使用过DirectSound,不太肯定!)。
为了实现采集模块对操作系统的兼容性更好,基本上对麦克风输入的采集使用WaveIn系列API函数比较多;
在Windows XP系统中,没有直接提供对声卡输出进行采集的API,因此,在Windows XP要实现对声卡输出的采集会比较麻烦。 通常可选用支持混音的声卡,然后通过使用声卡的混音模块来实现采集,但并不是所有的声卡都支持混音的功能,这样的方案不具备通用性。
要实现通用性,可以采用虚拟声卡的方式来实现,从驱动层获取声卡的输出数据,但这种方案实现难度会比较大。
而在Vista以上的系统中,如Win7,则可以使用Core Audio中的API函数来实现采集声卡输出的功能。
对于混音模块的实现,目前基本是使用自定义的混音算法来完成功能,系统没有直接的API函数可供调用。
2.使用WaveIn系列API函数实现麦克风输入采集
涉及的API函数:
waveInOpen
开启音频采集设备,成功后会返回设备句柄,后续的API都需要使用该句柄
调用模块需要提供一个回调函数(waveInProc),以接收采集的音频数据
waveInClose
关闭音频采集模块
成功后,由waveInOpen返回的设备句柄将不再有效
waveInPrepareHeader
准备音频采集数据缓存的空间
waveInUnprepareHeader
清空音频采集的数据缓存
waveInAddBuffer
将准备好的音频数据缓存提供给音频采集设备
在调用该API之前需要先调用waveInPrepareHeader
waveInStart
控制音频采集设备开始对音频数据的采集
waveInStop
控制音频采集设备停止对音频数据的采集
音频采集设备采集到音频数据后,会调用在waveInOpen中设置的回调函数。
其中参数包括一个消息类型,根据其消息类型就可以进行相应的操作。
如接收到WIM_DATA消息,则说明有新的音频数据被采集到,这样就可以根据需要来对这些音频数据进行处理。
(示例以后补上)
3.使用Core Audio实现对声卡输出的捕捉
涉及的接口有:
IMMDeviceEnumerator
IMMDevice
IAudioClient
IAudioCaptureClient
主要过程:
创建多媒体设备枚举器(IMMDeviceEnumerator)
通过多媒体设备枚举器获取声卡接口(IMMDevice)
通过声卡接口获取声卡客户端接口(IAudioClient)
通过声卡客户端接口(IAudioClient)可获取声卡输出的音频参数、初始化声卡、获取声卡输出缓冲区的大小、开启/停止对声卡输出的采集
通过声卡采集客户端接口(IAudioCaptureClient)可获取采集的声卡输出数据,并对内部缓冲区进行控制
(示例以后补上)
4.常用的混音算法
混音算法就是将多路音频输入信号根据某种规则进行运算(多路音频信号相加后做限幅处理),得到一路混合后的音频,并以此作为输出的过程。
我目前还做过这一块,搜索了一下基本有如下几种混音算法:
将多路音频输入信号直接相加取和作为输出
将多路音频输入信号直接相加取和后,再除以混音通道数,防止溢出
将多路音频输入信号直接相加取和后,做Clip操作(将数据限定在最大值和最小值之间),如有溢出就设最大值
将多路音频输入信号直接相加取和后,做饱和处理,接近最大值时进行扭曲
将多路音频输入信号直接相加取和后,做归一化处理,全部乘个系数,使幅值归一化
将多路音频输入信号直接相加取和后,使用衰减因子限制幅值
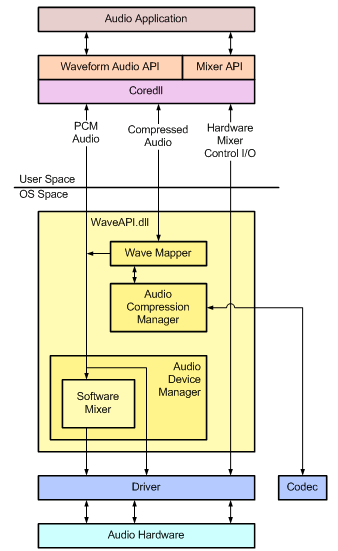
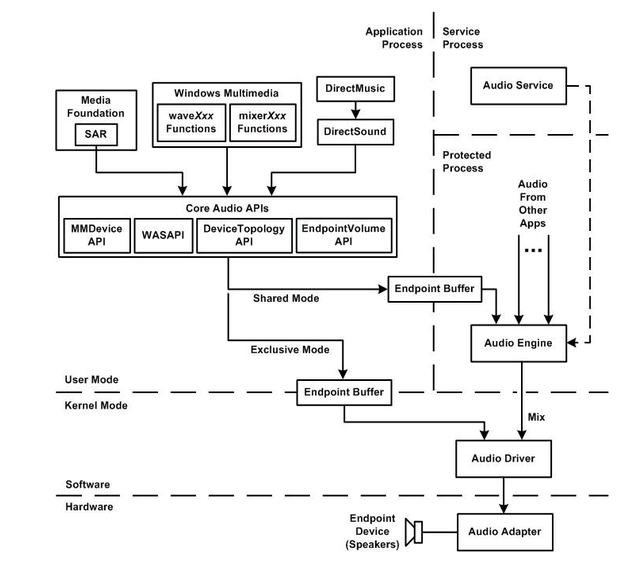
可 以看到原来Auido的API (waveXXX, mixerXXX和DirectSound)都依赖下层的新封装的Core Audio APIs,而且这些APi都工作在用户模式, 也就是说声音的合成是在用户模式下通过软件实现的。在Vista之后, 可以看到我们可以单独控制每个应用程序的声音了, 因为每路Audio都可以工作在不同的Audio session了。通过新的Core Audio API, 我们可以很容易的实现声卡声音的抓取