论文下载地址:https://arxiv.org/abs/1612.00593
代码:https://github.com/charlesq34/pointnet
论文中文翻译:https://blog.csdn.net/qq_41895003/article/details/105217366
https://blog.csdn.net/qq_37314249/article/details/103605076
一、 存在的问题
3D点云是一种很重要的几何数据结构。由于其存在空间关系不规则的特点,因此不能直接将已有的图像分类分割框架套用到点云上。许多研究者会将3D点云转换为3D体素(voxel grids )或者一系列图片,然后套用到现有的深度学习框架上,取得了非常好的效果。但是将点云体素化势必会改变点云数据的原始特征,造成不必要的数据损失。因此,作者想要做的就是设计一个可以直接处理3d点云数据的深度学习框架
二、 解决的方案
1、点云特征
点云数据是在欧式空间下的点的一个子集,它具有以下三个特征:
(1)无序。
与图像中的像素阵列或体积网格中的体素阵列不同,点云是一组没有特定顺序的点集。换句话说,一个消耗N个3D点集的网络对N!种排列顺序的输入点集数据的应是不变的。
(2)点与点之间的空间关系。
这些点来自于具有距离度量的空间。这意味着点与点之间不是孤立的,并且相邻点可以形成一个有意义的集合。因此,这个模型需要从相邻点中捕捉局部结构,以及局部结构之间的结合相互作用。
(3)变换下的不变性。作为一个几何物体,点集的学习表示对某些变换应该是不变的。例如,旋转和平移不能改变全局点云类别或点的分割情况。
2、解决方法
针对点云的特征提出解决问题的方法
(1)无序性的解决方案:目前文献中使用的方法包括
将无序的数据重排序、
用数据的所有排列进行数据增强然后使用RNN模型、
用对称函数来保证排列不变性。
作者最终选择使用max pooling来聚合全局信息,并在后面从理论上证明了,当特征维数足够大时,max pooling可以模拟论文中所述的任意对称函数f。推导略。
(2)点间关系的解决方案:
一个物体通常由特定空间内的一定数量的点云构成,也就是说这些点云之间存在空间关系。为了能有效利用这种空间关系,论文作者在计算得到全局点云特征向量后,将其与前面的点特征拼接在一起聚合特征。随后再从拼接后的特征向量中提取特征,这时既有局部信息也有全局信息。
(3)不变性解决方案:
论文作者提出了在进行特征提取之前,先对点云数据进行对齐的方式来保证不变性。对齐操作是通过训练一个小型的网络来得到转换矩阵,并直接和输入点云数据相乘来实现。
对齐网络也可以扩展到特征空间中,通过一个小网络T-Net预测出一个特征变换矩阵,乘在输出的特征向量上。
考虑到在特征空间上的变换矩阵比普通的空间变换矩阵(3维)的维度高得多,这会给优化增加不小的难度。所以另外还要在最后的softmax损失上加上一个正则化项: 。 其中A是T-Net预测得到的特征对齐矩阵。对角矩阵不会丢失输入信息,这也是我们所期望的。作者提到,加上正则化项之后训练会更稳定。
三、 网络结构
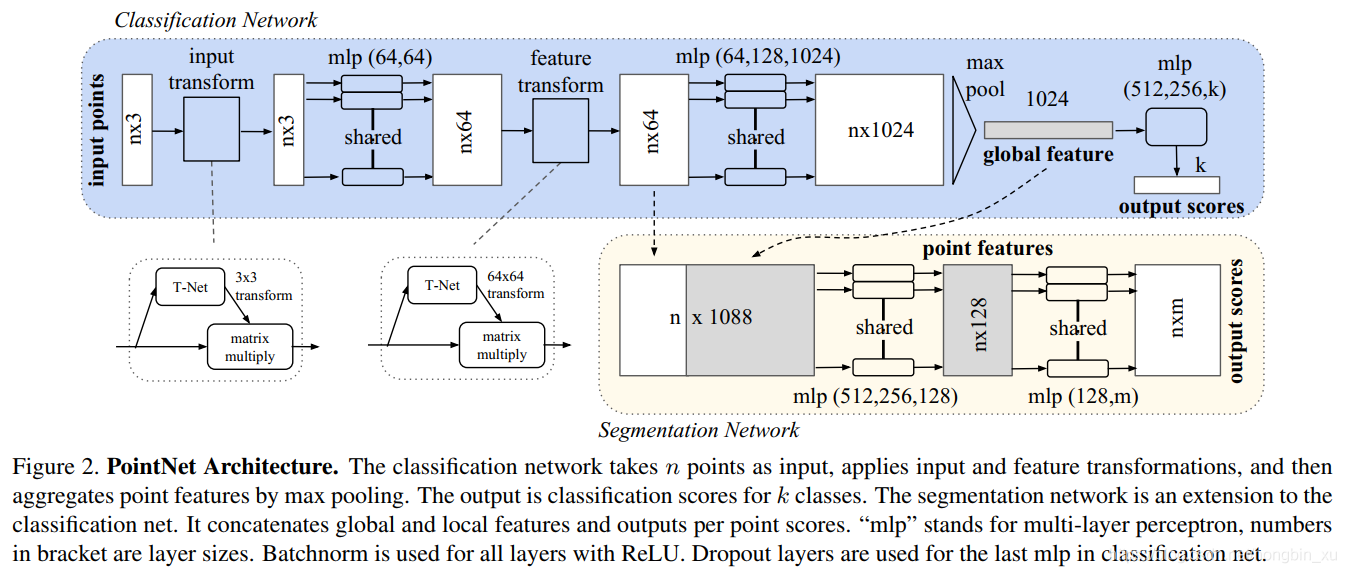
三个关键结构:
1、最大池化层,用来将从所有的点上提取得来的信息聚合到一起===》无序性
2、局部信息和全局信息结合结构===》点间关系
3、两个对齐网络T-Net,用来将输入点和特征点进行对齐 ====》不变性
点云》空间对齐》特征变换》特征对齐》特征变换》池化》特征变换==》分类
点云》空间对齐》特征变换》特征对齐》特征变换》池化》特征拼接》特征变换》特征变换》==》分割
四、 理论证明
作者对他们模型进行了进一步的理论分析,并提出了两个定理:
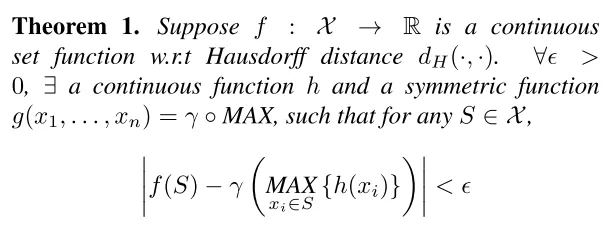
同时,作者发现PointNet模型的表征能力和maxpooling操作输出的数据维度(K)相关,K值越大,模型的表征能力越强。
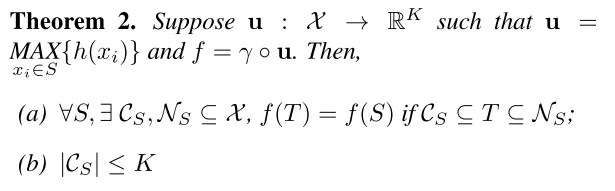
五、实验效果
1、应用
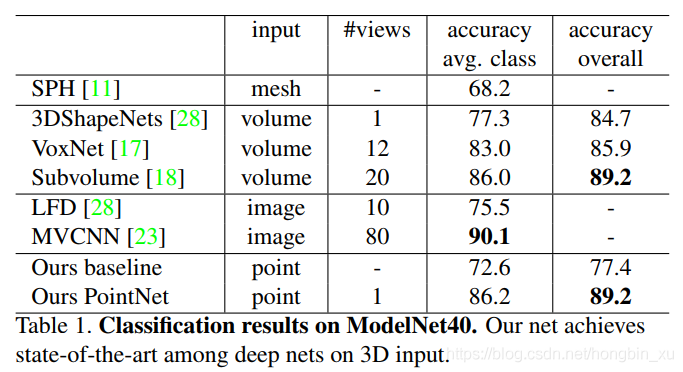
(1)分类: ModelNet40数据集
(2)部件分割:ShapeNet part数据集
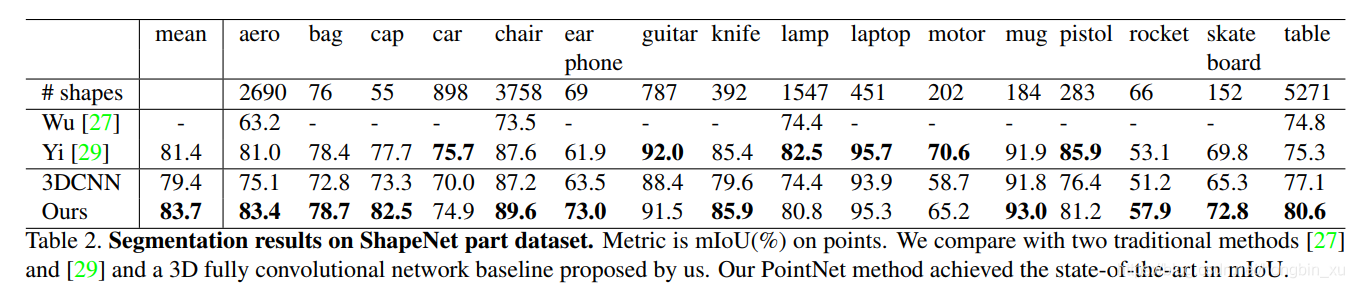
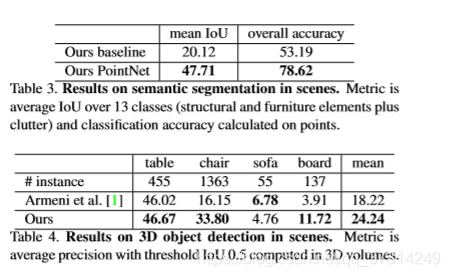
(3)语义分割/检测
2、网络结构分析
(1)针对无序性的解决方法比较
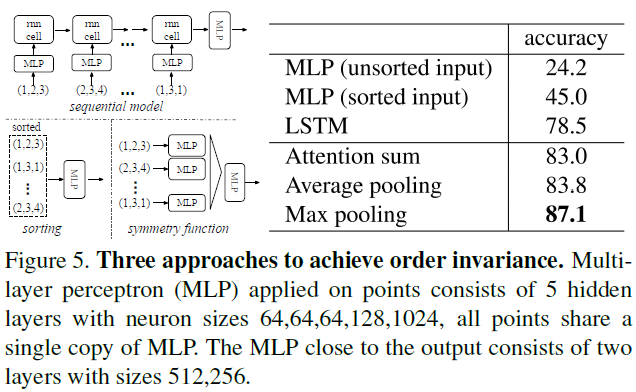
(2)输入和特征对齐的有效性验证

(3)鲁棒性测试(数据缺失、异常值、点扰动)

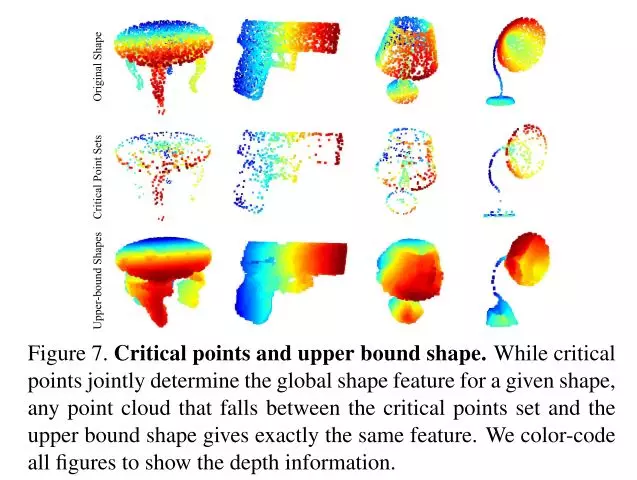
3、可视化(解释为什么鲁棒性)
通过研究是哪些点最大程度激活了神经元的值,论文发现,能够最大程度激活网络的点都是物体的主干点,将其上采样,很容易能得到原始的结构。这样的能力决定了PointNet对噪声和数据缺失的鲁棒性。如图所示,作者通过实验列出了PointNet学习到的以下几个物体的关键点。
4、时间和空间复杂度分析
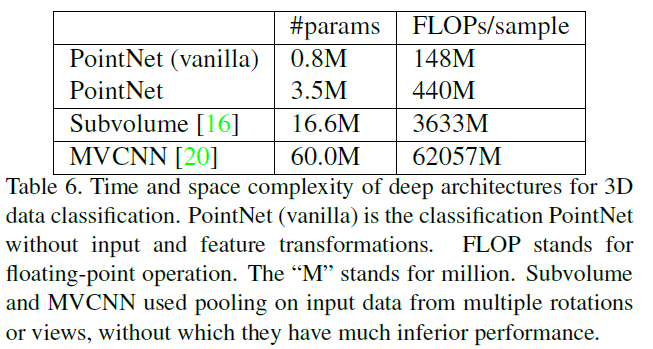
六、仍存在的问题
PointNet只关注了3D点云的全局信息,对于局部信息的利用不够充分,在平移不变性上有一定缺陷,后来作者提出了PointNet++。
七、代码分析
(略)
参考:https://cloud.tencent.com/developer/article/1640702
https://www.jiqizhixin.com/articles/2019-05-10-13
https://blog.csdn.net/hongbin_xu/article/details/84638109