论文地址:https://arxiv.org/abs/1905.08705
代码:https://github.com/FrankCAN/GAPointNet
摘要
由于点云在非欧几里得空间中具有不规则和稀疏的结构,利用点云的细粒度语义特征仍然具有挑战性。在现有的研究中,PointNet提供了一种在无序三维点云上直接学习形状特征的有效方法,并取得了较好的性能。然而,有助于更好的上下文学习的局部特性没有被考虑。同时,注意机制通过对邻近节点的关注,可以有效地捕获基于图的数据上的节点表示。在本文中,我们提出了一种新的用于点云的神经网络,称为GAPNet,通过在多层感知器(MLP)层中嵌入图注意机制来学习局部几何表示。首先,我们引入了一个GAPLayer,通过在邻域上突出不同的注意权重来学习每个点的注意特征。其次,为了挖掘足够的特征,采用了多头机制,允许GAPLayer聚合来自独立头的不同特征。第三,我们提出了在邻域上使用注意力池化层来捕获局部签名,以增强网络的鲁棒性。最后,GAPNet应用多层MLP层来关注特征和局部特征,充分提取局部几何结构。文中在ModelNet40和ShapeNet部件数据集上对提出的GAPNet体系结构进行了测试,并实现在形状分类和部件分割任务的最先进的性能。
一、引言
点云数据变得越来越受欢迎的在一个广泛的应用,如:自动驾驶、机器人地图和导航、3 d形状表示和建模[7],许多研究人员关注形状分析和理解,特别是当卷积神经网络(cnn)实现计算机视觉任务的重要的成功。然而,CNNs严重依赖标准网格结构的数据,导致对点云等不规则、无序的几何数据性能低下。因此,充分利用来自点云的上下文信息仍然是一个具有挑战性的问题。
为了充分利用CNN的优势,一些方法[13,24,19]在使用CNN架构之前,先将非结构化点云映射到标准的3D网格中。然而,由于点云结构具有典型的稀疏性,这些体积表示在内存和计算效率方面并不高效。与在网格点云上应用CNNs不同,PointNet[16]首创了直接在不规则点云上应用深度学习的方法。特别地,PointNet使输入点云对排列不变性,并通过独立地在每个点上应用多层感知器(MLP)网络和对称函数来利用点的特征。然而,它只捕捉全局特征而没有局部信息。PointNet++ [18]扩展了PointNet模型,构造了一个层次神经网络,递归地应用设计的采样层和分组层,通过PointNet来提取局部特征。DGCNN[25]对点和对应边进行边缘卷积,进一步利用局部信息。KC-Net[20]改编自点云配准方法,构建核相关层来度量点的几何亲和力。
注意机制已被证明在许多领域是有效的,如机器翻译任务[21,1]、基于视觉的任务[14]和基于图的任务[22]。灵感来自于图注意力网络[22],我们主要集中在充分利用细粒度的局部特征点云在三维形状分类和部分分割任务的注意方式。总结我们工作的主要贡献如下:
- 我们提出了一个多头GAPLayer来捕捉上下文的注意特征,通过指示不同的邻居对每个点的重要性。独立的头并行地处理来自表示空间的不同特征,并进一步聚合在一起,以获得足够的特征提取能力。
- 我们提出了自注意力和邻域注意力机制,以允许GAPLayer通过考虑自几何信息和与相应邻域的局部相关性来计算注意系数。
- 为了提高网络的鲁棒性,提出了一种基于邻域的注意力池层来识别最重要的特征。
- 我们的GAPNet将GAPLayer和注意力池层集成到堆叠的多层感知器(MLP)层或现有的流水线(如PointNet)中,以更好地从无序的点云中提取局部上下文特征。
二、相关工作
基于体素网格的特征学习
体素化是一种将稀疏不规则的点云转换为标准网格结构的直观方法,之后可以使用标准的CNNs进行特征提取。Voxnet[13]体素将点云转化为一个体素网格,表示每个体素的空间占用情况,然后是一个3D CNN处理被占用体素来预测对象的类别。然而,三维密集和稀疏占用的体积网格会导致高空间分辨率的大内存和计算成本。因此,提出了一些改进措施来解决稀疏性问题。Kd-Net[9]利用kd-tree[2]构建高效的三维空间划分结构和深度架构来学习点云的表示。类似地,OctNet[19]对一组浅八叉树生成的混合网格八叉树结构进行三维卷积,以实现高分辨率。
直接从非结构化点云中学习特征
PointNet[16]是在原始点云上直接应用深度学习的先驱工作。更详细地说,多层感知器(MLP)网络和对称函数(如max pooling)被应用于每一个单独的点来提取全局特征。该方法为理解非结构化点云提供了一种有效的方法,但由于该体系结构只在独立的点上工作,而没有度量局部区域内点之间的关系,因此无法捕获局部特征。为了解决这个问题,PointNet++[18]构造了一个递归地应用带有采样层和分组层的PointNet的层级神经网络,以利用局部表示。DGCNN[25]通过提出一种边缘卷积运算(EdgeConv)对PointNet进行了扩展,该运算应用于边缘特征,将每个点和连接到相邻对的对应边缘聚合在一起。为了发挥标准CNN操作的优势,PointCNN[11]尝试学习一个X-conv算子将一个给定的无序点集变换为一个潜在的正则序,然后使用典型的CNN架构提取局部特征。
从多视图模型中学习特征
为了应用标准的CNN操作,同时又避免基于体积的方法中计算量大的问题,一些研究者对基于多视图的方法很感兴趣。例如,[17,23]将典型的二维CNN架构应用于由三维点云上的多视图投影生成的多个二维图像视图,从而间接地学习点云的特征。但是,由于二维图像缺乏深度信息,这些多视角方法无法实现对点云的语义分割任务,导致对图像中每一个点进行分类的难度很大。
几何深度学习的学习特征
几何深度学习[4]是一组新兴技术的现代术语,这些技术试图通过深度神经网络来处理非欧几里得结构化数据(如3D点云、社交网络或遗传网络)。图CNNs[5,6,28]在许多任务中显示了图表示的优势,对于非欧几里得数据,它可以自然地处理这些不规则结构。PointGCN[29]构建了一个graph CNN架构来捕获局部结构并对点云进行分类,这也证明了几何深度学习在无序点云分析方面具有巨大的潜力。
三、GAPNet架构
在本节中,我们提出了我们的GAPNet模型,以更好地学习形状分类和部分分割任务中非结构化点云的局部表示。我们详细介绍了由三个组件组成的模型:GAPLayer(图2所示的基于多头图注意力的点网络层)、注意力池化层和GAPNet架构(图3所示)。
令X = { xi∈RF;i = 1,2,…, N }是无序点和模型输入的原始集合,具有F维,其中N是点的数量,xi是可能包含3D空间坐标(x; y; z ),颜色,强度,表面法线等。为简单起见,在此研究中,我们设置F = 3,仅使用3D坐标作为输入特征。
3.1 GAPLayer
局部结构表示
考虑到在实际应用中,点云中的样本数量可能非常大(如自主车辆),由于每一个点在每一个其他点上的权重分配非常小,让每一个点都去关注所有其他点将导致高计算成本和梯度消失问题。因此,我们构造了有向k最近邻图G =(V; E)来表示点云的局部结构,其中V ={1,2,…,N}是点的节点,E=V x Ni是连接相邻点对的边,Ni是点xi的邻居集。我们将边缘特征定义为yij =(xi - xij),其中i∈V,j∈Ni,并且xij指示点xi到相邻点xj。
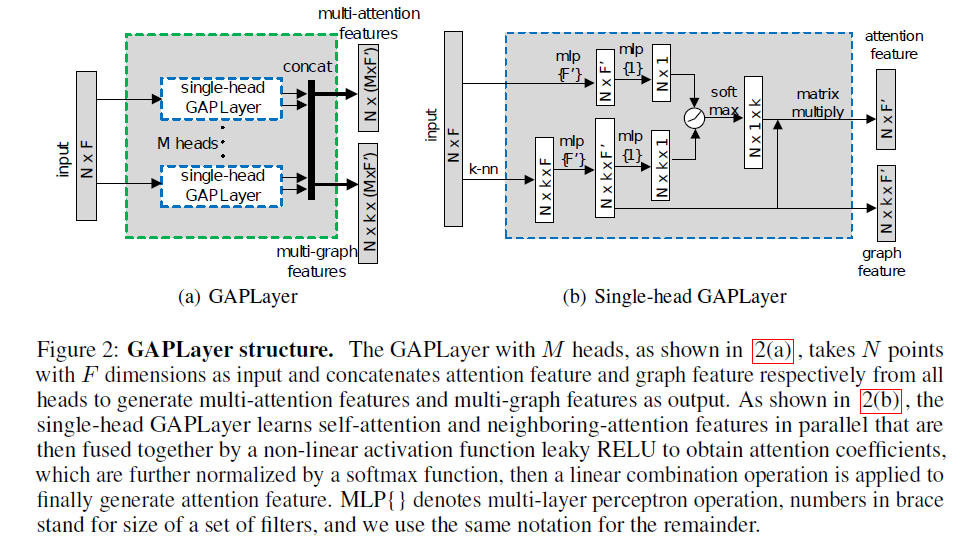
单头GAPLayer
为了方便读者,我们首先介绍一个单头GAPLayer以点云数据作为输入,与多头机制结合,通过我们网络中的特性通道将所有头连接在一起。单头GAPLayer的结构如图2(b)所示。
为了对不同的邻域给予不同的注意,我们提出了自注意机制和邻域注意机制来获取每个点对其邻域的注意系数,如图1所示。自注意力机制通过考虑每个点的自几何信息来学习自系数,而邻域注意力机制通过考虑邻域来关注局部系数。
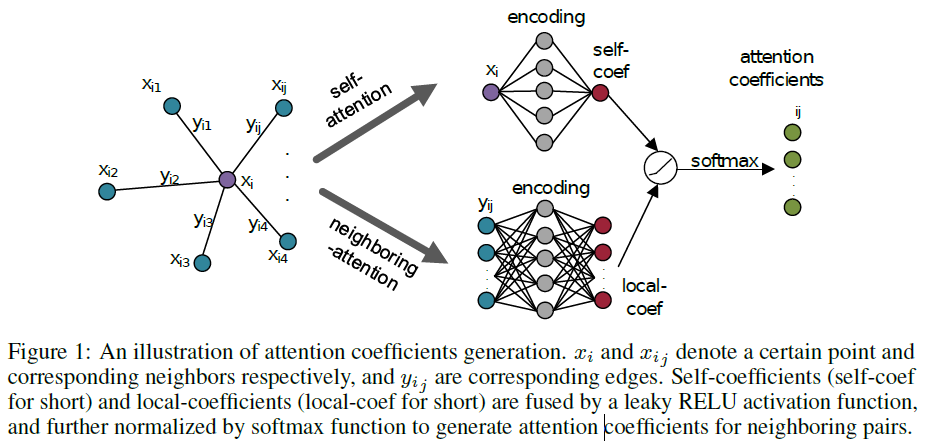
作为第一步,我们对点云的节点和边缘进行编码,其输出维度F’由公式1和2定义。

我们将方程3定义的自系数h(x’i;θ)和局部系数h(y’ij; θ)融合起来获得注意力系数,其中h(x’i;θ)和h(y’ij;θ)是单层神经网络 具有一维输出。 LeakyReLU()表示非线性激活函数LeakyReLU。
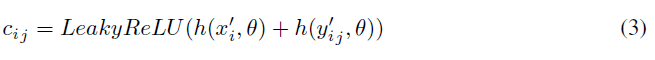


多头机制
为了获得充分的结构信息和稳定网络,我们将M个独立的单头GAPlayer连接在一起,生成具有M个F’通道的多头注意力特征。方程被定义为6。如图2(a)所示,multi-head GAPLayer(简称GAPLayer)的输出是将对应头的注意力特征和图特征进行拼接的多头注意力特征和多图特征。

3.2注意力池化层
为了增强网络的鲁棒性和提高网络性能,我们在多图特征的相邻通道上定义了一个注意力池化层。我们使用最大池化作为我们的注意力池化操作,它识别头部之间最重要的特征,以捕获局部签名表示Yi,被定义为公式7。局部签名连接到中间层,用于捕获全局特征。

3.3 GAPNet架构
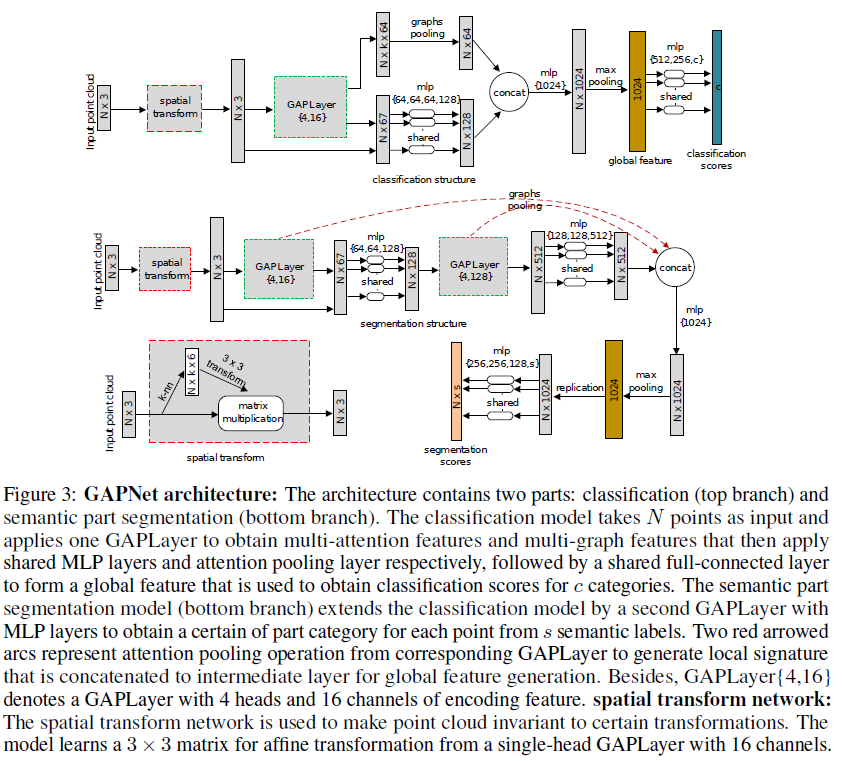
图3所示的GAPNet模型考虑了点云的形状分类和语义部分分割。体系结构类似于PointNet[16]。然而,架构之间有三个主要的区别。首先,我们使用一个注意感知的空间变换网络使点云对特定的变换不变性。其次,我们不是只处理单个点,而是在多层MLP层之前利用一个GAPLayer的局部特征。第三,利用注意力池层获取连接到中间层的局部签名
四、实验
在本节中,我们评估了我们的GAPNet模型在3D点云分类和零件分割任务中的应用,然后我们比较我们的表现与最近的最先进的方法,并进行消融研究,以调查不同的设计变化。
4.1分类
数据集
我们在ModelNet40基准测试上演示了我们的分类模型的有效性[26]用于形状分类。ModelNet40数据集包含12311个网格化的CAD模型,这些模型被划分为40个人工类别。我们分离了9,843个模型用于训练,2,468个模型用于测试。然后对单元球内的模型进行归一化,在模型表面均匀采样1024点。我们通过随机旋转、缩放点云和使用高斯噪声抖动每个点的位置来进一步增大训练数据集,所有模型的均值为零,标准差为0.01。
网络结构
分类模型如图3所示(上分支)。为了使输入点对一些几何变换(如缩放、旋转)不变,我们首先应用注意力感知空间变换网络将点云对准一个规范空间.然后该网络采用了一个具有16个通道的单头GAPLayer来捕获注意力特征,接着采用三个共享MLP层(64,128,1024)分别输出大小为64,128,1024的神经元,然后采用最大池化操作和两个全连接层(512,256)最后生成一个变换矩阵。
然后使用多头 GAPLayer生成M个F’通道的多注意特征,其中设置M = 4个人头,设置F’ = 16个编码通道。我们的多注意特征集合了点云的坐标特征,得到了上下文的注意特征,通道数为3+M x F’,然后通过4个共享的MLP层(64、64、64、128)提取细粒度特征。使用skip-connection方法连接局部签名和这些中间层,然后是共享的全连接层(1024)和特征通道上的最大池化操作,得到整个点云的全局特征。最后应用三个共享的MLP层(512、256、40)和保留概率为0.5的dropout操作,将全局特征转换为40个类别。另外,使用批处理归一化的激活函数ReLU被用在每层,邻居k设为20。
训练细节
在训练过程中,我们的优化器模型是Adam [8], momentum为0.9,我们设置批大小为32,学习率从0.005开始,然后每20 epoch被2除到0.00001。批次归一化的衰减率最初设置为0.7,逐渐增加到0.99。我们的模型是在NVIDIA GTX1080Ti GPU和TensorFlow v1.6上训练的。
结果
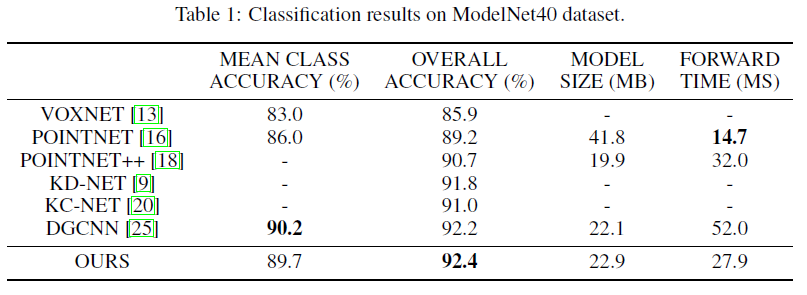
表1将我们的结果和复杂性与最近的几个最先进的工作进行了比较,我们的模型在ModelNet40基准测试中获得了最好的性能,并且它比之前的最先进的模型DGCNN的精度高出0.2%。
消融研究
我们还在ModelNet40基准[26]上使用不同的设置测试我们的分类模型。特别地,我们分析了GAPLayer,注意力池层,以及不同数目的多个头和编码通道的有效性。
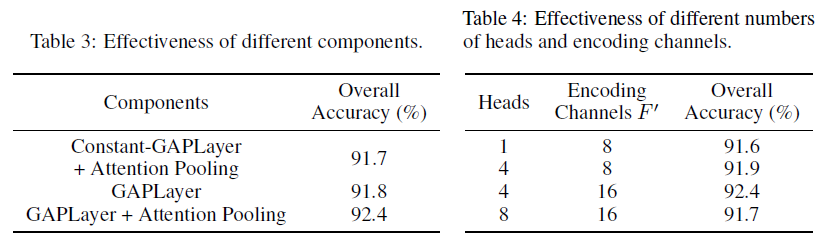
表3表示了我们的GAPLayer和注意力池层的优点。结果表明,注意力集中层的准确率为0.6%。Constant-GAPLayer表示一个与我们的GAPLayer具有相同结构的模型,但所有的系数都设置为相等的常数,这表明了图注意机制和我们的GAPLayer模型的有效性,其精确度达到0.7%。
关于不同头数M和编码通道F’的影响。从表4可以看出,适当的数目有利于局部特征提取,但随着数目的增大,性能会下降。
4.2 语义部件分割
数据集
在语义部分分割任务中,我们评估了我们在ShapeNet部件数据集[27]上的分割模型,即对网格模型中的每个点进行部件分类。数据集由16个类别的16,881个CAD形状组成,模型中的每个点都用一个包含50个部分类的类进行注释。并且每个形状模型标注了几个不超过6个的部件。我们采用与4.1节相同的采样策略,对2048个点进行均匀采样,实验中将数据集分为9843个模型进行训练,2468个模型进行测试。
模型结构
我们的分割模型如图3所示(底部分支)是为点云中的每个点预测一个部件类别标签。我们首先使用与4.1节相同的空间变压器网络和GAPLayer,然后使用共享的MLP层(64,64,128)。第二个GAPLayer具有4个头和128个编码通道,然后是共享的MLP层(128,128,512)得到512个信道的表示,这些表示与GAPLayer相应的注意力池化层生成的局部签名连接。聚合后的特征使用共享的全连接层(1024)和最大池化,得到一个全局特征,然后复制2048次,最后使用4个共享的全连接层(256,256,128,50),保留概率为0.6,将全局特征转换为50个部分类别。
训练细节
训练设置与分类任务的设置类似,只是批大小设置为8,邻居k设置为30,我们将任务分配给两个NVIDIA TESLA V100 GPUs。
结果
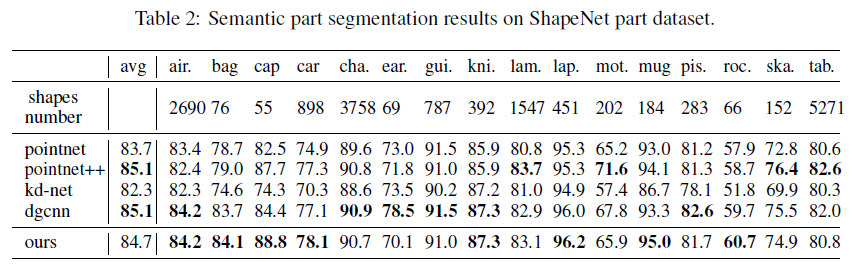
我们使用联合的平均交(mIoU)[16]作为我们的评估方案来对齐评估度量。每个形状的IoU是通过对属于同一类别的所有部分的IoU进行平均来计算的,然后mIoU就是测试数据集中所有形状的IoU的平均值。
五、结论
在本文中,我们提出了一种基于图注意的点神经网络,名为GAPNet,用于学习点云的形状表示。实验表明,在形状分类和语义部分分割任务的最新性能。该模型的成功也验证了图注意网络在图节点相似度计算和几何关系理解方面的有效性。
在未来,我们可以进一步探索几个研究途径。例如,一些应用程序,如自动驾驶汽车,通常需要处理非常大规模的点云数据。因此,如何有效、稳健地处理大规模数据将是一项值得研究的课题。此外,为非结构化数据分析开发一种高效的类似cnn的操作将是很有趣的。