scrapy-redis简介
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
有如下特征:
- 分布式爬取
可以启动多个spider工程,相互之间共享单个redis队列
- 分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这样可以根据需求启动竟可能多的处理程序来共享item的队列,进行item数据的持久化。
- scrapy即插即用的组件
Scheduler调度器 + Duplication 复制过滤器,Item Pipeline 基本的spider
scrapy-redis架构
scrapy-redis整体运行流程如下:

1. 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2. Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),
可能导致的结果就是会降低爬虫的速度,而且会占用Redis大量的存储空间。
本次分布式爬取的任务以及相关配置介绍
1、单机的scrapy程序编写
首先先在本机编写单机版的scrapy程序,具体程序见下面会介绍
2、将单机版的scrapy程序写改为scrapy-rdeis程序
首先是spider爬虫程序需要将原来的继承的类改为RedisSpider类
其次就是之前的start_urls不需要了,而是改为redis_key=“redis数据库压入时的键的名字”
# -*- coding: utf-8 -*- import scrapy from scrapy_redis.spiders import RedisSpider from datetime import datetime from quanshu.items import NovelItem,NovelChapterItem class NovelSpider(RedisSpider): name = 'novel' allowed_domains = ['www.quanshuwang.com'] # start_urls = ['http://www.quanshuwang.com/list/5_1.html'] redis_key = 'novel:start_url' # 解析每一页下所有小说的链接 def parse(self, response): # 收集小说的主页的url地址 novel_urls = response.xpath('//div[@class="mainnav"]//li/a/@href').extract() for novel_url in novel_urls: # print(novel_url) yield scrapy.Request(url=novel_url,callback=self.second_parse) # 在这里找到下一页直接返回用自己的函数解析就翻页了 # 这是找到下一页的url next_page_url = response.xpath('//div[@class="pages"]/div/a[@class="next"]/attribute::href').extract() # 判断一下,如果没有下一页链接则表明该板块爬取完毕 if not next_page_url: pass # print(next_page_url[0]) yield scrapy.Request(url=next_page_url[0],callback=self.parse) # 解析每一个小说的简介 并进入下一页 去获取没一个章节的小说链接 def second_parse(self,response): item = NovelItem() item['title'] = response.xpath('//div[@class="b-info"]//h1/text()').extract_first().strip() # print(item['title']) item['author'] = response.xpath('//div[@class="bookDetail"]/dl[2]/dd/text()').extract_first().strip() item['sort'] = response.xpath('//div[@class="main-index"]/a[last()]/text()').extract_first().strip() item['intro'] = response.xpath('//div[@id="waa"]/text()').extract_first().strip() item['status'] = response.xpath('//div[@class="bookDetail"]/dl[1]/dd/text()').extract_first() item['url'] = response.url item['c_time'] = datetime.now() # 下面的可以写到管道类中 if item['sort']: # 其他的都要strip一下 item['sort'] = item['sort'].strip() else: item['sort'] = '其他' # 查询章节列表url chapters_info_url = response.xpath('//a[@class="reader"]/@href').extract_first() yield scrapy.Request(chapters_info_url,callback=self.thrid_parse,meta={'item':item}) def thrid_parse(self,response): # print(resopnse.text) novel_item = response.meta['item'] # 提取小说章节信息 lias = response.xpath('//div[@class="chapterNum"]/ul//li/a') # 获取小说章节名称和章节url 链接的一个列表里面是元组 chapter_infos = [(a.xpath('./text()').extract_first(),a.xpath('./@href').extract_first()) for a in lias] novel_item['chapter_info'] = chapter_infos yield novel_item # 查询数据库 sql = "select id,url from chapter where content is null " self.cursor.execute(sql) for item in self.cursor.fetchall(): yield scrapy.Request(item[1],callback=self.four_parse,meta={"id":item[0]}) # # def four_parse(self,response): item = NovelChapterItem() item['content'] =''.join(response.xpath('//*[@id="content"]/text()').extract()) item['chapter_id'] = response.meta['id'] item['url'] = response.url # print(item['content']) yield item
在DownloaderMiddleware中不需要进行修改,这里只加了一个随机请求头的中间件
class RandomUserAgent(object): # 如何运行此中间件? settings 直接添加就OK def process_request(self, request, spider): # # 在请求头里设置ua ua = UserAgent(verify_ssl=False).random request.headers["User-Agent"] = ua
然后是items和pipelines这里都不需要修改代码如下:
import scrapy class NovelItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 小说名称 title = scrapy.Field() # 小说作者 author = scrapy.Field() # 小说类别 sort = scrapy.Field() # 小说简介 intro = scrapy.Field() # 小说状态(如连载和完结) status = scrapy.Field() # 小说爬取时间 c_time = scrapy.Field() # 小说网址链接 url = scrapy.Field() chapter_info = scrapy.Field() class NovelChapterItem(scrapy.Item): content = scrapy.Field() chapter_id = scrapy.Field() url = scrapy.Field()
import pymysql from quanshu.items import NovelItem,NovelChapterItem import logging from scrapy.exceptions import DropItem logger = logging.getLogger(__name__) class QuanshuPipeline(object): def process_item(self, item, spider): if isinstance(item, NovelItem): sql = "select id from novel where title=%s and author = %s" self.cursor.execute(sql,(item['title'],item['author'])) if self.cursor.fetchone(): pass else: try: # 写入小说信息 sql = 'insert into novel (title,author,sort,intro,status,c_time,url) values(%s,%s,%s,%s,%s,%s,%s)' self.cursor.execute(sql, (item['title'], item['author'], item['sort'], item['intro'], item['status'], item['c_time'], item['url'], )) self.conn.commit() # 章节信息 novel_id = self.cursor.lastrowid sql = 'insert into chapter (novel_id,title,ord,c_time,url) values ' for index ,info in enumerate(item['chapter_info']): title, url = info temp = '(%s,"%s",%s,"%s","%s"),'%(novel_id,title.replace(" ",""),index,item['c_time'],url) sql += temp sql = sql[:-1] # print(sql) try: self.cursor.execute(sql) self.conn.commit() except Exception as e: self.conn.rollback() logger.warning('小说章节信息写入数据库错误 url=%s %s'%(url,e) ) except Exception as e: self.conn.rollback() logger.warning('小说信息写入错误 url=%s %s'%(item['url'],e)) elif isinstance(item,NovelChapterItem): sql = 'update chapter set content=%s where id = %s' try: self.cursor.execute(sql,(item['content'],item['chapter_id'])) self.conn.commit() # print('小说内容写入成功') except Exception as e: # print('失败') self.conn.rollback() logger.warning('小说内容写入数据库信息错误 url=%s %s'%(item['url'],e)) else: raise DropItem # 设置爬虫一开始就链接数据库 def open_spider(self,spider): data_config = spider.settings["DATABASE_CONFIG"] # print(data_config) if data_config['type'] == 'mysql': self.conn = pymysql.connect(**data_config['config']) self.cursor = self.conn.cursor() spider.conn = self.conn spider.cursor = self.cursor # 设置爬虫一结束就关闭数据库链接 def close_spider(self,spider): data_config = spider.settings["DATABASE_CONFIG"] if data_config['type'] == 'mysql': self.cursor.close() self.conn.close()
下面settings文件的修改,这里是最重要的,先看代码:
# scrapy-redis 的配置 # 配置调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 重复过滤 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # redis 配置 REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 REDIS_PARAMS = { 'password': '123456', } # 数据保存数据库的配置 DATABASE_CONFIG = { 'type': 'mysql', 'config':{ 'host':'127.0.0.1', 'port':3306, 'user':'root', 'password':'root', 'db':'novel', 'charset':'utf8', } }
上面这部分是redis相关的配置,首先要使用scrapy-redis调度器组件和重复过滤组件,然后配置redis数据库的相关信息,还有数据入库mysql数据库相关的配置
DOWNLOADER_MIDDLEWARES = { # 'quanshu.middlewares.QuanshuDownloaderMiddleware': 543, # 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #随机请求头中间件 'quanshu.middlewares.RandomUserAgent': 200, } ITEM_PIPELINES = { 'quanshu.pipelines.QuanshuPipeline': 300, # 这里不用scrapy_redis的pipeline我们直接存到mysql中 }
上面的两个配置第一个是之前写好的随机请求头中间件的启用,下面的是pipelines的选用,注意这里我们选择的是scrapy本来的pipelines而没有选择scrapy-redis的pipelines,具体原因下面会说。
到这里基本的scrapy-redis程序就准备好了。
部署爬虫程序到服务器
本次准备一个Master端加七个Slaver端,下面是本次运行环境:
- 服务器系统:centos7.x版本
- python版本:python3,6
- fake-useragent:0.1.11
- pymysql :0.9.3
- Scrapy : 1.6.0
- Scrapy-rdeis : 0.6.8
- redis : 3.2.1
- Twisted : 19.2.0
需要注意的是在配置安装服务器环境的时候Twisted最好下载然后本地安装,好几台在线安装都失败。
这里由于自己的主节点的服务器的内存过小,所以redis中值存放了request请求队列和url指纹去重队列,这也是为什么没有使用scrapy-redis中的pipelines的原因。
环境准备好之后就可以再每个从节点上运行scrapy-redis程序了
启动scrapy-redis程序之后查看日志,每个scrapy-redis都会停在这里等待主节点发送任务。
此时在主节点发送需要爬取的网址url,将url压入redis数据库即可,代码如下
import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 r = redis.Redis(host='***.***.***.***', port=6379, password=123456, decode_responses=True) # host是redis主机,需要redis服务端和客户端都启动 redis默认端口是6379 for j in range(1,12): for i in range(20):
r.lpush("novel:start_url","http://www.quanshuwang.com/list/%s_%s.html"%(j,i+1))
这样,每个子节点拿到请求的url之后就能开始爬去工作了,当然每次爬取过程中子节点还会把需要下次请求的request再次写入redis数据库中。
到这里本次的分布式部署就结束了。
说一说此次遇到的问题以及一些解决思路
- 由于时间的关系本次只是简单的部署了一下,下次希望改进成scrapyd进行部署,至于为什么,当你需要监控爬虫状态和日志的时候你就知道了。每次一台一台服务器的查看,真的很麻烦。
- 由于没有使用scrapy-redis中的pipelines而是直接在每个子节点直接把数据写入到数据库,但是由于爬虫爬去的速度和下载内容的速度远大于向数据库中写入的速度,也是因为这样出现了好多问题,比如数据写着写着会丢失,还有就是mysql数据库会莫名的报错,具体的解决办法,可以将每台子节点写入数据库的程序写成异步的twisted模块中好像有这个功能,由于其他是耽误了所以也没尝试,不过网上看了好多资料,好像可以,不过异步写入数据库可能数据会乱,还有就是设置延迟将爬虫爬取的速度降下来,使用bs4解析模块,不要用xpath解析。因为xpath比bs4速度快。还有就是主节点的服务器配置弄好点,直接把数据先保存在redis数据库中,然后在通过其他python程序去取数据就好了。
- 在爬虫运行过程种出现了好几次redis保存问题
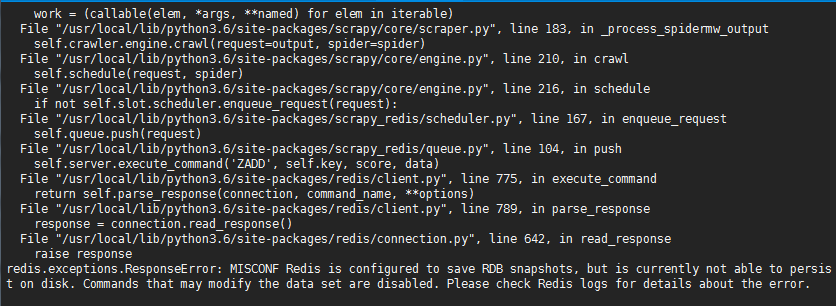


前两张是从节点scrapy-redis程序报错,最后是主节点redis日志报错信息,这是redis在数据持久化写入文件没有权限问题,解决办法将目标文件打开权限即可。