一、GIL全局解释锁
在Cpython解释器才有GIL的概念,不是python的特点
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
1.GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都是一样,都是将并发运行变成串行,以此来保证数据的安全性。用来阻止同一个进程下的多个线程的同时执行。保护不同的数据的安全,就应该加不同的锁。
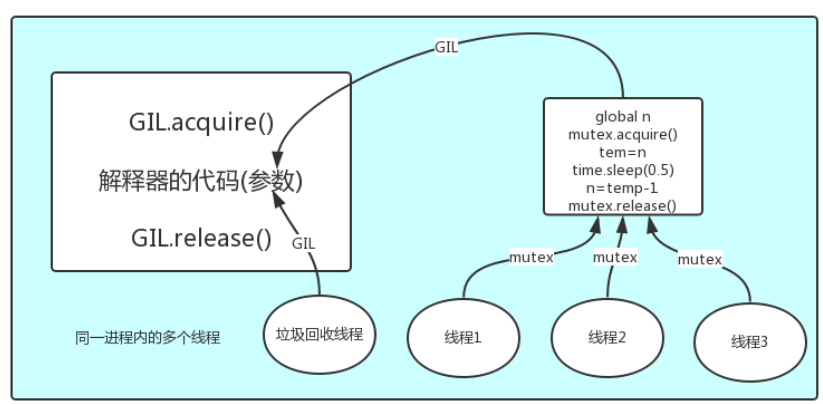
每次执行python程序,都会产生一个独立的进程,每个py文件都会产生独立的python进程。在一个python进程中,不仅有这个文件的主线程和开启的其他线程,还有解释器开启的垃圾回收机制等解释器级别的线程。
GIL存在是因为Cpython解释器的内存管理不是线程安全的:(这个内存管理指的是垃圾回收机制)
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(运行的py文件代码以及Cpython解释器的所有代码) 例如:test.py定义一个函数work,在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。 #2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
综上所述:在同一进程中多个线程在执行代码的时候,多个线程先访问到解释器的代码,拿到执行权限,然后将代码交给解释器去执行。解释器的代码是所有线程共享的,所以垃圾回收线程也是可以可能访问到解释器的代码去执行,这就导致了一个问题,当线程刚刚创建了一个数字100,还没来得及和一个变量名绑定关系,这个时候如果垃圾回收机制来检测到了,会直接把没有绑定关系的数字100删除,考虑到这种问题,所以出现GIL全局解释锁,保证python解释器同一时间只能执行一个任务的代码。
2.GIL和Lock
GIL保护的是解释器级的数据,Lock保护用户自己的数据。保护不同的数据的安全,就应该加不同的锁。


分析: #1.100个线程去抢GIL锁,即抢执行权限 #2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire() #3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL #4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
#互斥锁与join的区别 join是等待某个子线程或者子线程所有代码执行完毕,相当于锁住了整个代码 Lock只是锁住一部分操作数据的代码 两者之间是有很大差距的
3.GIL和多线程
有了GIL的存在,在同一时刻同一进程里面只有一个线程被执行。
那python的多线程没法利用多核的优势,是不是就没用了?
研究python的多线程是否有用需要分情况讨论:
假如有四个任务 计算密集型的情况下
单核情况下:开多个进程只会增加内存的开销,多线程开销更少,线程更节省资源
多核情况下:多核意味着并行计算,多进程可以把任务分散给每一个CPU,但是线程在一个进程中同一时刻只有一个线程执行用不上多核。进程更节省资源
假如有四个任务 I/O密集型的情况下
单核情况下:多进程增加资源消耗,而且进程的切换速度远不如线程,线程更节省资源
多核情况下:进程再多的核也解决不了I/O问题,都会进入阻塞态,而且还消耗资源,线程更节省资源
应用:多线程用于IO密集型:如socket,爬虫,web 多进程用于计算密集型:如金融分析
二、死锁现象和递归锁
所谓死锁:是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。如下就是死锁
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print('�33[41m%s 拿到A锁�33[0m' %self.name) mutexB.acquire() print('�33[42m%s 拿到B锁�33[0m' %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print('�33[43m%s 拿到B锁�33[0m' %self.name) time.sleep(2) mutexA.acquire() print('�33[44m%s 拿到A锁�33[0m' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t=MyThread() t.start() ''' Thread-1 拿到A锁 Thread-1 拿到B锁 Thread-1 拿到B锁 Thread-2 拿到A锁 然后就卡住,死锁了 '''
解决方法使用递归锁:RLock。RLock可以被第一个抢到锁的人连续的acquire和release,每acquire一次,锁计数加1,每release一次,锁计数减1,只要锁的
计数不为0,其他线程都只能等待,等待该线程释放完所有锁。
三、信号量Semaphore
Semaphore 管理一个内置的计数器,每当调用acquire()是内置计数-1,调用release()是内置计数器+1,计数器不能小于0,当计数器为0时,acquire()将阻塞线程直到其他线程调用release()
""" 互斥锁:一个厕所(一个坑位) 信号量:公共厕所(多个坑位) """ from threading import Semaphore,Thread import time import random sm = Semaphore(5) # 造了一个含有五个的坑位的公共厕所 def task(name): sm.acquire() print('%s占了一个坑位'%name) time.sleep(random.randint(1,3)) sm.release() for i in range(40): t = Thread(target=task,args=(i,)) t.start() #同时创建了40个线程,5个坑位的公共厕所,开始有五个线程去占,睡不同时间之后,释放锁,同时其他线程拿到锁,最多只能有五个线程拿到锁。
四、event事件 让线程等待线程
from threading import Event,Thread import time # 先生成一个event对象 e = Event() def light(): print('红灯正亮着') time.sleep(3) e.set() # 发信号 print('绿灯亮了') def car(name): print('%s正在等红灯'%name) e.wait() # 等待信号 print('%s加油门飙车了'%name) t = Thread(target=light) #线程运行light函数 t.start() for i in range(10): t = Thread(target=car,args=('伞兵%s'%i,)) t.start() #线程先执行light函数,然后运行car函数,睡3秒,运行e.set()及下面的代码,同时,e.wait在等待信号,接收到信号之后也执行下面的代码。
五、线程queue
同一个进程下的多个线程本来就是数据共享 为什么还要用队列,因为队列是管道+锁,使用队列你就不需要自己手动操作锁的问题,因为锁操作不好极容易产生死锁现象。
import queue q = queue.Queue() #先进先出 q.put('hahha') print(q.get()) #haha q = queue.LifoQueue() #last in first out 后进先出 和堆栈先进后出一样 q.put(1) q.put(2) q.put(3) print(q.get()) #3 q = queue.PriorityQueue() # 数字越小 优先级越高 q.put((10,'haha')) q.put((100,'hehehe')) q.put((0,'xxxx')) q.put((-10,'yyyy')) print(q.get()) #(-10, 'yyyy')
六、TCP服务端实现并发
将不同的功能尽量拆分成不同的函数拆分出来的功能可以被多个地方使用
1.将连接循环和通信循环拆分成不同的函数
2.将服务端通信循环做成多线程
服务端
import socket from threading import Thread server = socket.socket() server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn): while True: try: data = conn.recv(1024) if len(data) == 0:break print(data.decode('utf-8')) conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() while True: conn, addr = server.accept() # 监听 等待客户端的连接 阻塞态 t = Thread(target=talk,args=(conn,)) t.start()
客户端
import socket client = socket.socket() client.connect(('127.0.0.1',8080)) while True: client.send(b'hello') data = client.recv(1024) print(data.decode('utf-8'))