一、Django请求生命周期

二、路由层 urls.py
url()方法 第一个参数其实就是一个正则表达式,一旦前面的正则匹配到了内容,就不会再往下继续匹配,而是直接执行对应的视图函数。
django在路由匹配的时候,当你在浏览器中没有敲最后的斜杠,
django会先拿着你没有敲斜杠的结果去匹配,如果没有匹配上,会让浏览器在末尾加斜杠再发一次请求,再去匹配一次,如果还是匹配不上才会报错。
如果你想取消该机制,不想做二次匹配可以在seetings配置文件中设置 APPEND_SLASH = False # 该参数默认是True
1.简单路由配置
url(r'^index/$', views.index) #开头和结尾都需要设置 ^ $
- 第一个参数是正则表达式,第二个参数是视图函数(跳转到哪个视图函数)
- 每个正则表达式前面的'r'是可选的,但是建议加上,取消转义
url(r'index/', views.index)
如果不加^和$,由于路由匹配是从上往下的,若是输入其他路径里面包含index,也是会被匹配到的
首页路径匹配不能这样写,这样写会把所有的都匹配到
url(r'', views.home) #404页面配置,写在最后一行
应该是用正则形式写,这样直接输入ip和端口号就能访问到首页
url(r'^$', views.home) #首页配置
2.无名分组
url(r'^index/(d+)/', views.index) #一定要记得写括号
def index(request,xxx) 或者 def index(request,*args)
- 按位置传参
- ()表示分组,路由匹配的时候,会将()正则表达式匹配到的内容当做位置参数传递给视图函数
- views视图函数必须要位置参数接收分组出来的数据,这个参数名可以随便取(这里用xxx接收(d+)),当分组出来的数据很多时,也可以用*args用一个元组接收所有数据

3.有名分组
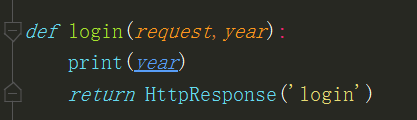
url(r'^index/(?P<year>d+)/', views.index) #大写P,year代表的是d+正则表达式匹配的内容
def index(request,year)
- 按关键字传参
- 路由匹配的时候,会将括号内的正则表达式匹配到的内容,当做关键字参数传递给视图函数
- views视图函数接收的的参数名必须要和url传递的参数名一致,不然就会报错。(year接收url传递的数字)
注意:有名分组和无名分组不能混合使用
但是在同一种分组下,是可以使用多个的
无名分组支持多个 url(r'^test/(d+)/(d+)/', views.test), 有名分组支持多个 url(r'^test/(?P<year>d+)/(?P<xx>d+)/', views.test),
三、反向解析
本质:其实就是给你返回一个能够访问对应的url的地址。
普通反向解析,无参
1.先给url和视图函数对应关系起别名(name就是起别名)
url(r'^test/', views.test),
url(r'^testadd/', views.testadd,name='aaa')
2.反向解析
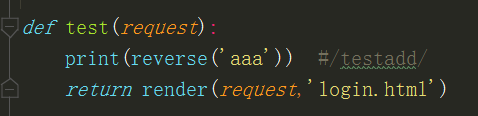
后端反向解析 视图层
后端可以在任意位置通过reverse反向解析出对应的url(就是通过别名name得出对应的url)
from django.shortcuts import render,HttpResponse,redirect,reverse
print(reverse('aaa')) #aaa是别名,打印testadd
前端反向解析 模板层
<a href="{% url 'aaa' %}">1</a>
无名分组反向解析(无名分组+反向解析)
也是先起别名name
url(r'^index/(d+)/$',views.index,name='kkk')
后端反向解析 视图层
reverse('kkk',args=(1,)) #后面的数字通常都是数据的id值
前端反向解析 模板层
{% url 'kkk' 1%} #后面的数字通常都是数据的id值
有名分组反向解析
同无名分组反向解析一样的用法
先起别名
url(r'^index/(?P<year>d+)/$',views.index,name='kkk')
后端反向解析
print(reverse('kkk',args=(1,))) # 推荐你使用上面这种 减少你的脑容量消耗 或者
print(reverse('kkk',kwargs={'year':1}))
前端反向解析
<a href="{% url 'kkk' 1 %}">1</a> # 推荐你使用上面这种 减少你的脑容量消耗 或者
<a href="{% url 'kkk' year=1 %}">1</a>
注意:在同一应用下,别名千万不能重复(******)
四、路由分发 include (针对存在多个app)
当你的django项目特别庞大的时候 路由与视图函数对应关系特别特别多,那么你的总路由urls.py代码太过冗长 不易维护
每一个应用都可以有自己的urls.py,static文件夹,templates文件夹(******)
正是基于上述条件 可以实现多人分组开发 等多人开发完成之后 我们只需要创建一个空的django项目
然后将多人开发的app全部注册进来 在总路由实现一个路由分发 而不再做路由匹配(来了之后 我只给你分发到对应的app中)
from django.conf.urls import url,include
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^app01/',include('app01.urls')), url(r'^app02/',include('app02.urls')), ]
总路由中,一级路由后面千万不要加$符号
五、名称空间(了解)
多个app内路由起了相同的别名,这个时候用反向解析,并不会自动识别应用前缀
有两种方式:
方式1:
总路由
url(r'^app01/',include('app01.urls',namespace='app01')) url(r'^app02/',include('app02.urls',namespace='app02'))
后端解析:
reverse('app01:index') #名称空间:别名 reverse('app02:index')
前端解析:
{% url 'app01:index' %} #名称空间:别名
{% url 'app02:index' %}
方式2:
起别名的时候不要冲突,一般情况下在起别名的时候通常建议以应用名作为前缀
name ='app01_index'
六、伪静态
静态网页:数据是写死的 万年不变
伪静态网页的设计是为了增加百度等搜索引擎seo查询力度
所有的搜索引擎其实都是一个巨大的爬虫程序
网站优化相关 通过伪静态确实可以提高你的网站被查询出来的概率
但是再怎么优化也抵不过RMB玩家
#路由,用html结尾 url(r'^book.html/',views.book)
虚拟环境
一般情况下 我们会给每一个项目 配备该项目所需要的模块 不需要的一概不装
虚拟环境 就类似于为每个项目量身定做的解释器环境
如何创建虚拟环境
每创建一个虚拟环境 就类似于你又下载了一个全新的python解释器
django版本的区别
django1.X跟django2.X版本区别 路由层1.X用的是url 而2.X用的是path 2.X中的path第一个参数不再是正则表达式,而是写什么就匹配什么 是精准匹配 当你使用2.X不习惯的时候 2.X还有一个叫re_path 2.x中的re_path就是你1.X的url
虽然2.X中path不支持正则表达式 但是它提供了五种默认的转换器 1.0版本的url和2.0版本的re_path分组出来的数据都是字符串类型 默认有五个转换器,感兴趣的自己可以课下去试一下 str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式 int,匹配正整数,包含0。 slug,匹配字母、数字以及横杠、下划线组成的字符串。 uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。 path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?) path('index/<int:id>/',index) # 会将id匹配到的内容自动转换成整型
还支持自定义转换器 class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value 占四位,不够用0填满,超了则就按超了的位数来! register_converter(FourDigitYearConverter, 'yyyy') urlpatterns = [ path('articles/2003/', views.special_case_2003), path('articles/<yyyy:year>/', views.year_archive), ... ]
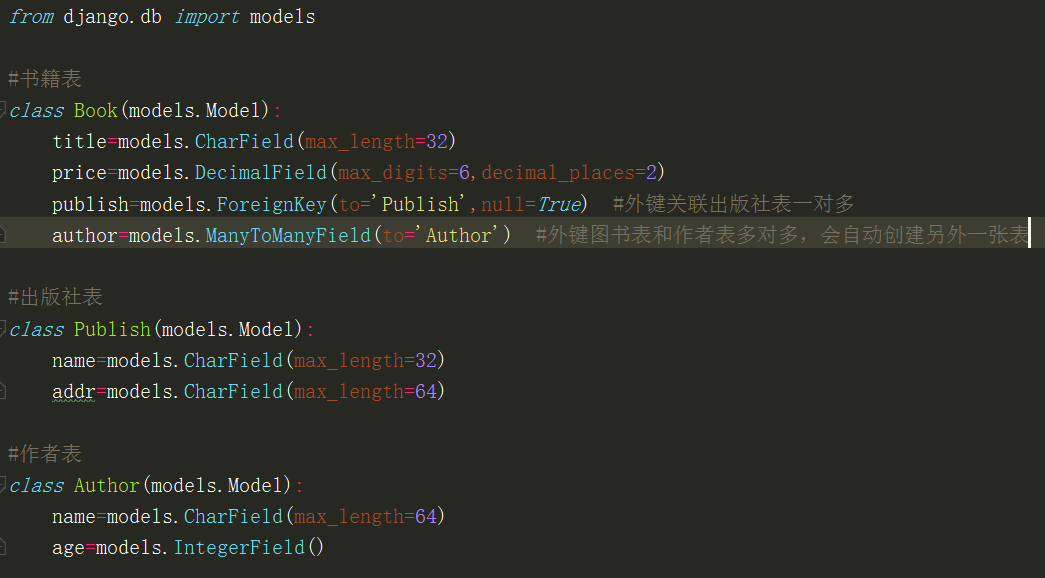
图书管理系统表设计
三张表:图书表,出版社表,作者表
图书表和出版社表是一对多,图书表和作者表是多对多
一对多: Foreignkey 一对一:OneToOneField 多对多:ManyToManyField
mysql数据库生成的表
